Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Entender cómo crear clústeres de Amazon EMR y trabajar con ellos
En este tema, se ofrece información general de los clústeres de Amazon EMR, lo que incluye cómo enviar trabajos a un clúster, la forma en que se procesan los datos y los distintos estados por los que pasa el clúster durante el procesamiento.
En este tema
Familiarizarse con los clústeres y los nodos
El componente central de Amazon EMR es el clúster. Un clúster es un conjunto de instancias de Amazon Elastic Compute Cloud (Amazon EC2). Cada instancia del clúster se denomina nodo. Cada nodo tiene un rol dentro del clúster, conocido como el tipo de nodo. Amazon EMR también instala distintos componentes de software en cada tipo de nodo, lo que proporciona a cada nodo un rol en una aplicación distribuida, como Apache Hadoop.
Los tipos de nodos en Amazon EMR son los siguientes:
-
Nodo principal: un nodo que administra el clúster mediante la ejecución de componentes de software para coordinar la distribución de datos y las tareas entre los demás nodos para su procesamiento. El nodo principal hacer un seguimiento del estado de las tareas y supervisa el estado del clúster. Cada clúster tiene un nodo principal y se puede crear un clúster de un solo nodo con solo el nodo principal.
-
Nodo secundario: un nodo con componentes de software que ejecutan tareas y almacenan datos en el Hadoop Distributed File System (HDFS) del clúster. Los clústeres de varios nodos tienen al menos un nodo secundario.
-
Nodo de tareas: un nodo con componentes de software que solo ejecuta tareas y no almacena datos en HDFS. Los nodos de tareas son opcionales.
Envío de trabajo a un clúster
Cuando se ejecuta un clúster en Amazon EMR, dispone de varias opciones sobre cómo especificar el trabajo que hay que llevar a cabo.
-
Proporcionar toda la definición del trabajo que hay que realizar en funciones que debe especificar como pasos al crear un clúster. Esto se realiza normalmente para clústeres que procesan una cantidad definida de datos y, a continuación, terminan cuando se completa el procesamiento.
-
Cree un clúster de ejecución prolongada y utilice la consola de Amazon EMR, la API de Amazon EMR o AWS CLI los pasos para enviar, que pueden contener uno o más trabajos. Para obtener más información, consulte Envío del trabajo a un clúster de Amazon EMR.
-
Cree un clúster, conéctese al nodo principal y a los demás nodos según sea necesario mediante SSH y utilice las interfaces que proporcionan las aplicaciones instaladas para llevar a cabo tareas y enviar consultas, ya sea de forma interactiva o con scripts. Para obtener más información, consulte la Guía de publicación de Amazon EMR.
Procesamiento de datos
Al lanzar el clúster, puede elegir los marcos de trabajo y las aplicaciones que desea instalar para sus necesidades de procesamiento de datos. Para procesar datos en el clúster de Amazon EMR, puede enviar los trabajos o las consultas directamente a las aplicaciones instaladas, o puede ejecutar pasos en el clúster.
Envío de trabajos directamente a las aplicaciones
Puede enviar trabajos e interactuar directamente con el software que está instalado en el clúster de Amazon EMR. Para ello, normalmente se conecta al nodo principal a través de una conexión segura y accede a las interfaces y herramientas que están disponibles para que el software se ejecute directamente en el clúster. Para obtener más información, consulte Conectar a un clúster de Amazon EMR.
Ejecución de pasos para procesar datos
Puede enviar uno o varios pasos ordenados a un clúster de Amazon EMR. Cada paso es una unidad de trabajo que contiene instrucciones para manipular los datos para su procesamiento por el software instalado en el clúster.
A continuación se muestra un proceso de ejemplo que utiliza cuatro pasos:
-
Enviar un conjunto de datos de entrada para procesamiento.
-
Procesar la salida del primer paso mediante un programa de Pig.
-
Procesar un segundo conjunto de datos de entrada mediante un programa de Hive.
-
Escribir un conjunto de datos de salida.
Por lo general, cuando se procesan datos en Amazon EMR, la entrada son datos almacenados como archivos en el sistema de archivos subyacente elegido, como Amazon S3 o HDFS. Estos datos se transfieren de un paso al siguiente en la secuencia de procesamiento. El último paso escribe los datos de salida en una ubicación especificada, como un bucket de Amazon S3.
Los pasos se ejecutan en la siguiente secuencia:
-
Se envía una solicitud para empezar los pasos de procesamiento.
-
El estado de todos los pasos se establece en PENDING (Pendiente).
-
Cuando se inicia el primer paso de la secuencia, su estado cambia a RUNNING (En ejecución). Los demás pasos permanecen en el estado PENDING (Pendiente).
-
Una vez que finaliza el primer paso, su estado cambia a COMPLETED (Completado).
-
El siguiente paso de la secuencia se inicia y su estado cambia a RUNNING (En ejecución). Una vez finalizado, su estado cambia a COMPLETED (Completado).
-
Este patrón se repite para cada paso hasta que se completen todos y el procesamiento finaliza.
El siguiente diagrama representa la secuencia de pasos y cambios de estado de los pasos a medida que se procesan.

Si un paso falla durante el procesamiento, su estado cambia a ERROR. Puede determinar lo que ocurre para cada paso. De forma predeterminada, los pasos restantes de la secuencia se establecen en CANCELADO y no se ejecutan si falla un paso anterior. También puede elegir omitir el error y permitir que los pasos restantes continúen o terminar el clúster inmediatamente.
El siguiente diagrama representa la secuencia de pasos y el cambio de estado predeterminado cuando un paso produce un error durante el procesamiento.

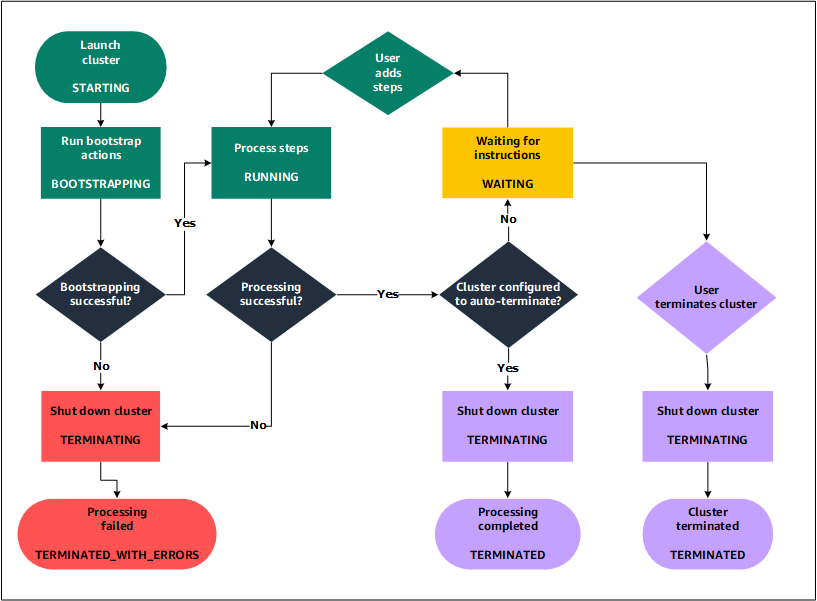
Descripción del ciclo de vida del clúster
Un clúster de Amazon EMR correcto sigue este proceso:
-
Amazon EMR primero aprovisiona EC2 instancias en el clúster para cada instancia según sus especificaciones. Para obtener más información, consulte Configuración del hardware y las redes de los clústeres de Amazon EMR. Para todas las instancias, Amazon EMR utiliza la AMI predeterminada de Amazon EMR o la AMI de Amazon Linux personalizada que se especifique. Para obtener más información, consulte Uso de una AMI personalizada para ofrecer más flexibilidad a la configuración del clúster de Amazon EMR. Durante esta fase, el estado del clúster es
STARTING. -
Amazon EMR ejecuta las acciones de arranque que especifique en cada instancia. Puede utilizar acciones de arranque para instalar aplicaciones personalizadas y realizar las personalizaciones que necesite. Para obtener más información, consulte Creación de acciones de arranque para instalar software adicional con un clúster de Amazon EMR. Durante esta fase, el estado del clúster es
BOOTSTRAPPING. -
Amazon EMR instala las aplicaciones nativas que especifique al crear el clúster, tales como Hive, Hadoop, Spark, etc.
-
Cuando las acciones de arranque se han completado correctamente y las aplicaciones nativas se han instalado correctamente, el estado del clúster es
RUNNING. En este punto, puede conectarse a las instancias del clúster y el clúster ejecutará por orden todos los pasos que haya especificado al crear el clúster. Puede enviar pasos adicionales, que se ejecutarán después de los pasos anteriores. Para obtener más información, consulte Envío del trabajo a un clúster de Amazon EMR. -
Una vez que los pasos se han ejecutado correctamente, el clúster pasa al estado
WAITING. Si un clúster está configurado para que se termine automáticamente después de que se haya completado el último paso, pasa a un estadoTERMINATINGy luego al estadoTERMINATED. Si el clúster está configurado para esperar, debe apagarlo manualmente cuando ya no lo necesite. Después de terminar manualmente el clúster, pasa al estadoTERMINATINGy, a continuación, al estadoTERMINATED.
Un error durante el ciclo de vida del clúster hace que Amazon EMR termine el clúster y todas sus instancias, a menos que habilite la protección de terminación. Si se termina un clúster debido a un error, todos los datos almacenados en el clúster se eliminan y el estado del clúster se establece en TERMINATED_WITH_ERRORS. Si ha habilitado la protección de terminación, puede recuperar los datos del clúster y después eliminar la protección de terminación y terminar el clúster. Para obtener más información, consulte Uso de la protección de finalización para proteger sus clústeres de Amazon EMR de un cierre accidental.
El siguiente diagrama representa el ciclo de vida de un clúster y cómo cada etapa del ciclo de vida se asocia a un determinado estado del clúster.