Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Amazon EMR activado EC2 : supervisión mejorada con el CloudWatch uso de métricas y registros personalizados
Descripción general
Amazon EMR ofrece capacidades de procesamiento de macrodatos potentes y rentables. Para maximizar el rendimiento y la utilización de los recursos, es esencial una supervisión eficaz. Amazon CloudWatch ofrece una observabilidad integral para los clústeres de EMR, lo que le permite realizar un seguimiento de las métricas y los registros en tiempo real. En este documento se describe cómo:
-
Configure el CloudWatch agente para enviar EMR en los registros a EC2 CloudWatch
-
Agregue Hadoop, YARN y HBase métricas personalizadas mediante clasificaciones
-
Supervise las métricas a través de paneles integrados
-
Realice un seguimiento de los registros del clúster mediante grupos de CloudWatch registros
Requisitos previos y antecedentes
De forma predeterminada, Amazon EMR envía las métricas básicas CloudWatch cada cinco minutos sin coste adicional. Con la versión 7.0+ de EMR, puede implementar el CloudWatch agente para:
-
Recopile 34 métricas detalladas adicionales en intervalos de un minuto (se aplican cargos adicionales)
-
Recopile métricas de todos los nodos del clúster
-
Agregue los datos en el nodo principal antes de enviarlos a CloudWatch
-
Acceda a las métricas a través de la pestaña Supervisión o la consola de EMR CloudWatch
EMR 7.1 amplía estas capacidades y le permite configurar el agente para capturar métricas especializadas de Hadoop, YARN y componentes. HBase Para los entornos que utilizan Prometheus, las métricas se pueden reenviar a Amazon Managed Service for Prometheus.
CloudWatch Configuración del agente para los registros
Para capturar los inicios de sesión de EMR CloudWatch, cree un archivo cloudwatch-config.json que defina qué archivos de registro recopilar:
cloudwatch-config.json
{ "agent": {"metrics_collection_interval":60,"logfile":"/var/log/emr-cluster-metrics/amazon-cloudwatch-agent/amazon-cloudwatch-agent.log","run_as_user":"****","omit_hostname":true}, "logs": { "logs_collected": { "files": { "collect_list": [ { "file_path": "/mnt/var/log/hadoop-yarn/hadoop-yarn-resourcemanager-*", "log_group_name": "/emr/yarn/resourcemnger", "log_stream_name": "{instance_id}", "publish_multi_logs" : true }, { "file_path": "/var/log/hadoop-hdfs/hadoop-hdfs-namenode-*", "log_group_name": "/emr/hdfs/namenode", "log_stream_name": "{instance_id}", "publish_multi_logs" : true } ] } } } }
Script de Bootstrap para la configuración del agente CloudWatch
Para aplicar su CloudWatch configuración personalizada a los nodos EMR, cree un script de arranque que reinicie el CloudWatch agente con su configuración. Este script garantiza que el agente se ejecute con sus parámetros específicos de recopilación de registros tras el aprovisionamiento del clúster.
Creación del script de Bootstrap
Cree un archivo denominado cloudwatch-agent-bootstrap.sh con el siguiente contenido:
#!/bin/bash set -xe EMR_SECONDARY_BA_SCRIPT=$(cat << 'EOF' while true; do NODEPROVISIONSTATE=$(sed -n '/localInstance [{]/,/[}]/ {/nodeProvisionCheckinRecord [{]/,/[}]/ {/status:/ p}}' /emr/instance-controller/lib/info/job-flow-state.txt | awk '{ print $2 }') if [ "$NODEPROVISIONSTATE" == "SUCCESSFUL" ]; then sleep 10 echo "Running my post provision bootstrap" NODETYPE=$(cat /mnt/var/lib/instance-controller/extraInstanceData.json | jq -r '.instanceRole' | awk '{print tolower($0)}') # Copy config file on the instance sudo aws s3 cp s3://amzn-s3-demo-bucket1>/cloudwatch-config.json /etc/emr-cluster-metrics/amazon-cloudwatch-agent/conf/emr-amazon-cloudwatch-agent.json # Stop the current agent sudo /usr/bin/amazon-cloudwatch-agent-ctl -a stop # Start the agent with the created config file sudo /usr/bin/amazon-cloudwatch-agent-ctl -a fetch-config -s -m ec2 -c file:/etc/emr-cluster-metrics/amazon-cloudwatch-agent/conf/emr-amazon-cloudwatch-agent.json # Status CW Agent echo "Status CW Agent" sudo /usr/bin/amazon-cloudwatch-agent-ctl -m ec2 -a status exit fi sleep 10 done EOF ) echo "${EMR_SECONDARY_BA_SCRIPT}" | tee -a /tmp/emr-secondary-ba.sh chmod u+x /tmp/emr-secondary-ba.sh /tmp/emr-secondary-ba.sh > /tmp/emr-secondary-ba.log 2>&1 & exit 0
Nota de configuración importante
importante
Antes de cargar el script, <amzn-s3-demo-bucket1> sustitúyalo por el nombre real del bucket de S3 en el que guardaste el archivo cloudwatch-config.json del paso anterior. Esto garantiza que el script de arranque pueda recuperar el archivo de configuración durante la inicialización del clúster.
Este script de arranque hará lo siguiente:
-
Espere a que se complete el aprovisionamiento del nodo
-
Descarga tu configuración personalizada CloudWatch
-
Detenga cualquier CloudWatch agente en ejecución
-
Reinicie el agente con su configuración específica
-
Registre el estado del agente para solucionar problemas
Clasificaciones métricas personalizadas para Hadoop, YARN y HBase
Además de CloudWatch las métricas predeterminadas, puede mejorar sus capacidades de supervisión configurando métricas personalizadas específicas de la aplicación para los componentes del clúster de EMR. La API de configuración de Amazon EMR proporciona una forma flexible de definir exactamente qué métricas desea recopilar.
Configuración de métricas personalizadas
Puede implementar la recopilación de métricas personalizada de dos maneras:
-
Durante la creación de clústeres para nuevos clústeres
-
Como reconfiguración de los clústeres existentes a través de la consola EMR
Creación de un archivo de clasificación
El archivo de clasificación define qué métricas de componentes específicos deben recopilarse del clúster. A continuación, se muestra un ejemplo de estructura para recopilar métricas de Hadoop personalizadas:
[ { "Classification": "emr-metrics", "Configurations": [ { "Classification": "emr-hadoop-hdfs-datanode-metrics", "Properties": { "Hadoop:service=DataNode,name=DataNodeActivity-*": "DatanodeNetworkErrors,TotalReadTime,TotalWriteTime,BytesRead,BytesWritten,RemoteBytesRead,RemoteBytesWritten,ReadBlockOpNumOps,ReadBlockOpAvgTime,WriteBlockOpNumOps,WriteBlockOpAvgTime", "otel.metric.export.interval": "30000" } }, { "Classification": "emr-hadoop-yarn-nodemanager-metrics", "Properties": { "Hadoop:service=NodeManager,name=JvmMetrics": "MemNonHeapUsedM,MemNonHeapCommittedM,MemNonHeapMaxM,MemHeapUsedM,MemHeapCommittedM,MemHeapMaxM,MemMaxM", "Hadoop:service=NodeManager,name=NodeManagerMetrics": "ContainerCpuUtilization,NodeCpuUtilization,ContainersCompleted,ContainersFailed,ContainersKilled,ContainersLaunched,ContainersRolledBackOnFailure,ContainersRunning,ContainerUsedMemGB,ContainerUsedVMemGB,ContainerLaunchDurationNumOps,ContainerLaunchDurationAvgTime", "otel.metric.export.interval": "20000" } } ], "Properties": {} } ]
Pasos para la implementación
-
Cree un archivo JSON con las clasificaciones métricas que desee.
-
Personalice las métricas en función de sus requisitos de supervisión.
-
Guarde el archivo y cárguelo en su bucket de S3.
-
Consulte este archivo cuando cree un clúster nuevo o reconfigure uno existente.
Prácticas recomendadas
-
Recopile únicamente métricas que proporcionen información significativa sobre sus cargas de trabajo.
-
Tenga en cuenta el intervalo de recopilación de métricas en función de sus necesidades de supervisión.
-
Consulte la AWS documentación para obtener la lista completa de las métricas disponibles para cada componente.
-
Agrupe las métricas relacionadas dentro de la misma clasificación para una mejor organización.
Este enfoque le permite centrar la supervisión en las métricas más importantes para sus aplicaciones de EMR específicas, lo que le brinda una mayor visibilidad del rendimiento del clúster.
Implementación de un clúster de EMR con integración CloudWatch
Siga estos pasos para crear un clúster de Amazon EMR que envíe automáticamente registros y métricas personalizadas a: CloudWatch
Paso 1: Habilitar el agente CloudWatch
Al crear el clúster de EMR a través de la consola de AWS administración:
-
Navegue hasta la sección Aplicaciones durante la creación del clúster.
-
Seleccione las casillas de verificación de sus aplicaciones principales (Hadoop, Spark, etc.).
-
Desplázate para buscar y seleccionar la opción Amazon CloudWatch Agent.
-
Esto habilita al agente en su clúster, lo cual es esencial para recopilar métricas y registros mejorados.
El CloudWatch agente se instalará en todos los nodos del clúster, lo que le permitirá recopilar las métricas del sistema y de las aplicaciones en los intervalos configurados.
Nombre y aplicaciones
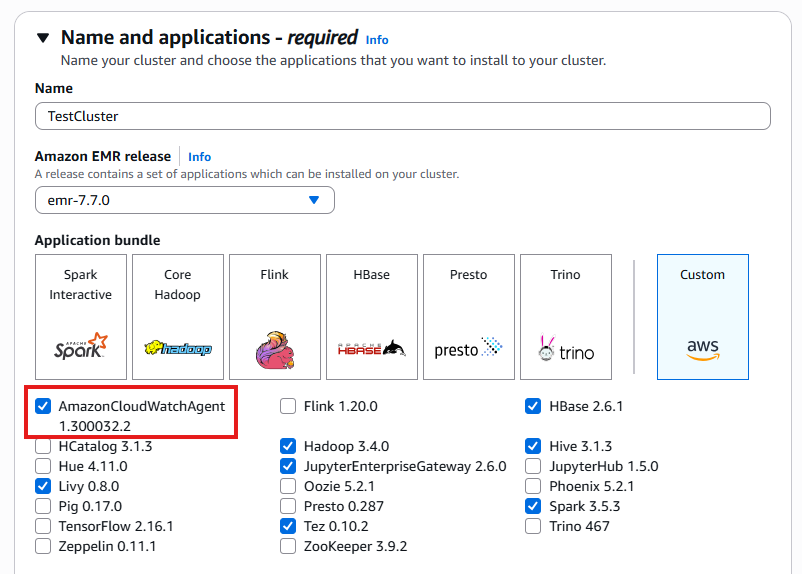
Crear un clúster y mostrar los paquetes disponibles.
nota
El CloudWatch agente está disponible en la versión 7.0 y posteriores de EMR. Es necesario habilitar este componente para la recopilación de métricas y el reenvío de registros personalizados que se describen en esta guía.
Paso 2: Añadir la acción Bootstrap para la recopilación de registros
Para configurar el CloudWatch agente para que recopile y reenvíe archivos de registro específicos a CloudWatch:
-
En el asistente de creación de clústeres de EMR, vaya a la sección Acciones de Bootstrap
-
Haga clic en Añadir acción de arranque
-
Selecciona Acción personalizada en el menú desplegable
-
Proporcione un nombre para la acción de arranque (por ejemplo, Configurar CloudWatch el agente)
-
En el campo Ubicación del script, introduzca la ruta S3 a su script cloudwatch-agent-bootstrap .sh (p. ej., s3://your-bucket-name/cloudwatch-agent-bootstrap.sh)
-
Haga clic en Añadir para guardar la acción de arranque
Esta acción de arranque se ejecutará durante el inicio del clúster, lo que garantizará que CloudWatchagent esté correctamente configurada con sus ajustes personalizados para recopilar y reenviar los archivos de registro especificados en el archivo de configuración.
El agente empezará a recopilar registros automáticamente una vez que se hayan aprovisionado los nodos, lo que proporcionará una visibilidad casi en tiempo real de las operaciones del clúster a través CloudWatch de los registros.
Acciones de arranque
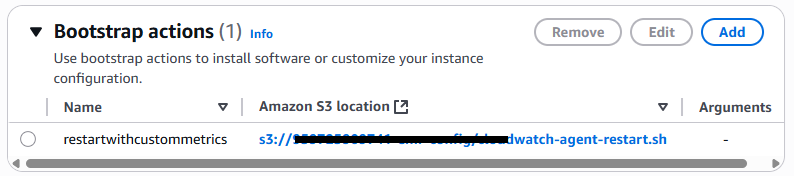
Uso de acciones de arranque.
Paso 3: Configurar la recopilación de métricas personalizadas
Para habilitar la recopilación de HBase métricas personalizadas de Hadoop, YARN o más allá del conjunto predeterminado:
-
En el asistente de creación de clústeres de EMR, vaya a la sección Configuraciones.
-
Haga clic en el botón Editar configuraciones para ampliar las opciones de configuración.
-
Seleccione la opción Cargar JSON desde Amazon S3 en el menú desplegable del método de configuración.
-
Introduzca la ruta URI de S3 a su archivo de clasificación de métricas personalizado (p. ej., s3://amzn-s3-demo-bucket1/ emr-metrics-classification .json).
-
Haga clic en Cargar para analizar la configuración.
-
Compruebe que la configuración aparece correctamente en la interfaz de la consola.
-
Haga clic en Guardar cambios para aplicar estas configuraciones métricas al clúster.
Este paso indica al CloudWatch agente que recopile las métricas de los componentes específicos definidas en el archivo de clasificación. Las métricas se recopilarán en los intervalos especificados en la configuración y se publicarán allí CloudWatch, donde se podrán visualizar y analizar.
Las métricas personalizadas proporcionan información más detallada sobre las características de rendimiento de su clúster, lo que permite una supervisión y solución de problemas más precisas de sus aplicaciones de EMR.
Configuración del software
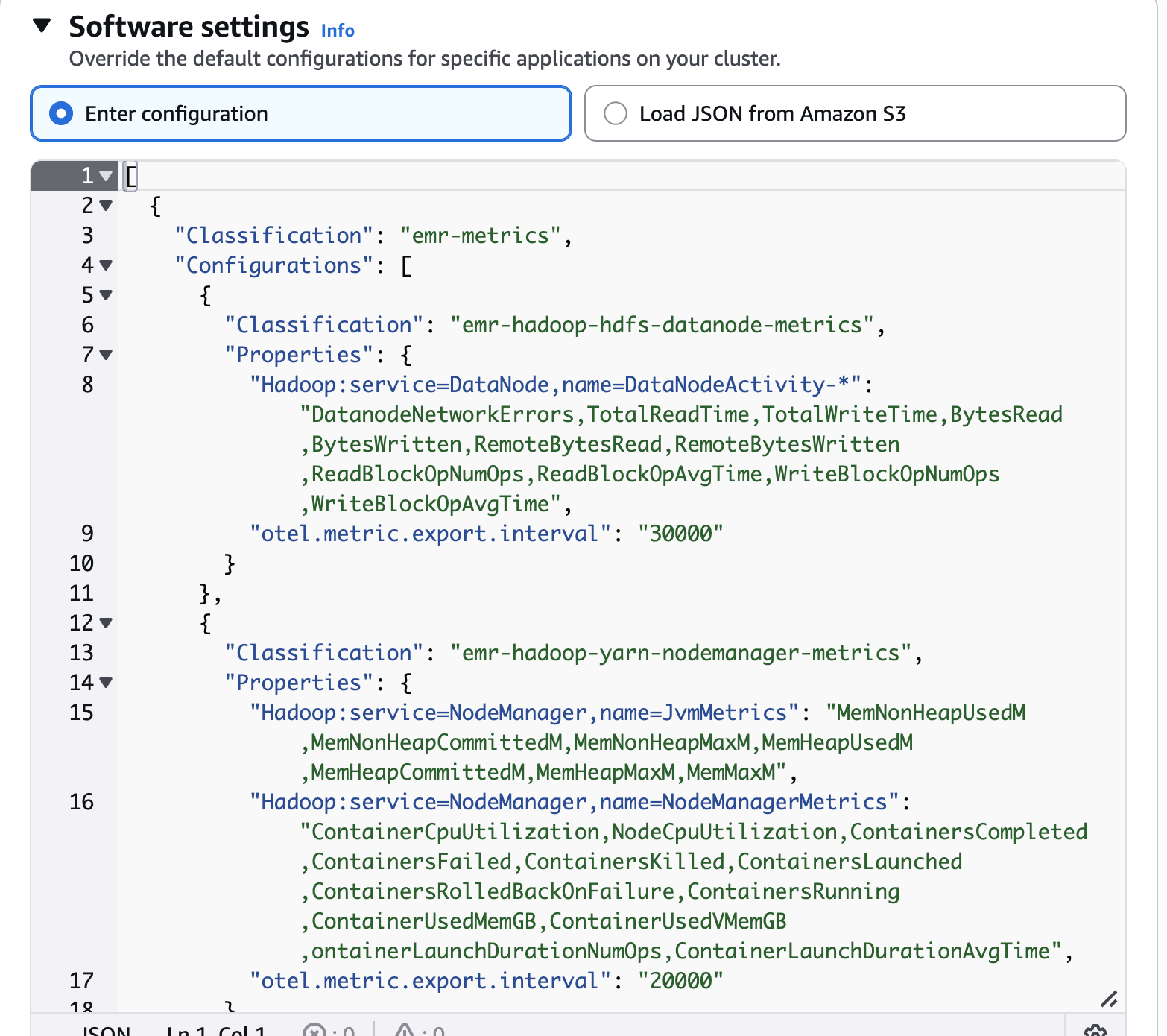
Anule las configuraciones predeterminadas.
Actualización de la configuración de métricas para los clústeres en ejecución
Puede modificar la configuración de recopilación de métricas de un clúster de EMR existente sin interrumpir las operaciones siguiendo estos pasos:
-
Navegue hasta el clúster de EMR activo en la consola de AWS administración.
-
Seleccione la pestaña Configuraciones en la vista de detalles del clúster.
-
Busque la sección de configuraciones de grupos de instancias.
-
Haga clic en el botón Reconfigurar para modificar la configuración.
-
Elija Cargar JSON desde Amazon S3 o edite directamente la configuración.
-
Introduzca la ubicación actualizada del archivo de clasificación de métricas o realice los cambios en el editor.
-
Aplique los cambios para actualizar el comportamiento de recopilación de métricas.
Esta capacidad de reconfiguración le permite ajustar su enfoque de supervisión a medida que evolucionan sus requisitos de carga de trabajo. El CloudWatch agente se adaptará automáticamente a la nueva configuración y recopilará el conjunto de métricas actualizado sin requerir el reinicio del clúster ni el tiempo de inactividad.
importante
Los cambios de configuración pueden tardar varios minutos en propagarse a todos los nodos del clúster. Siga supervisando sus CloudWatch paneles de control para confirmar que las nuevas métricas aparecen según lo esperado.
Configuraciones de clúster
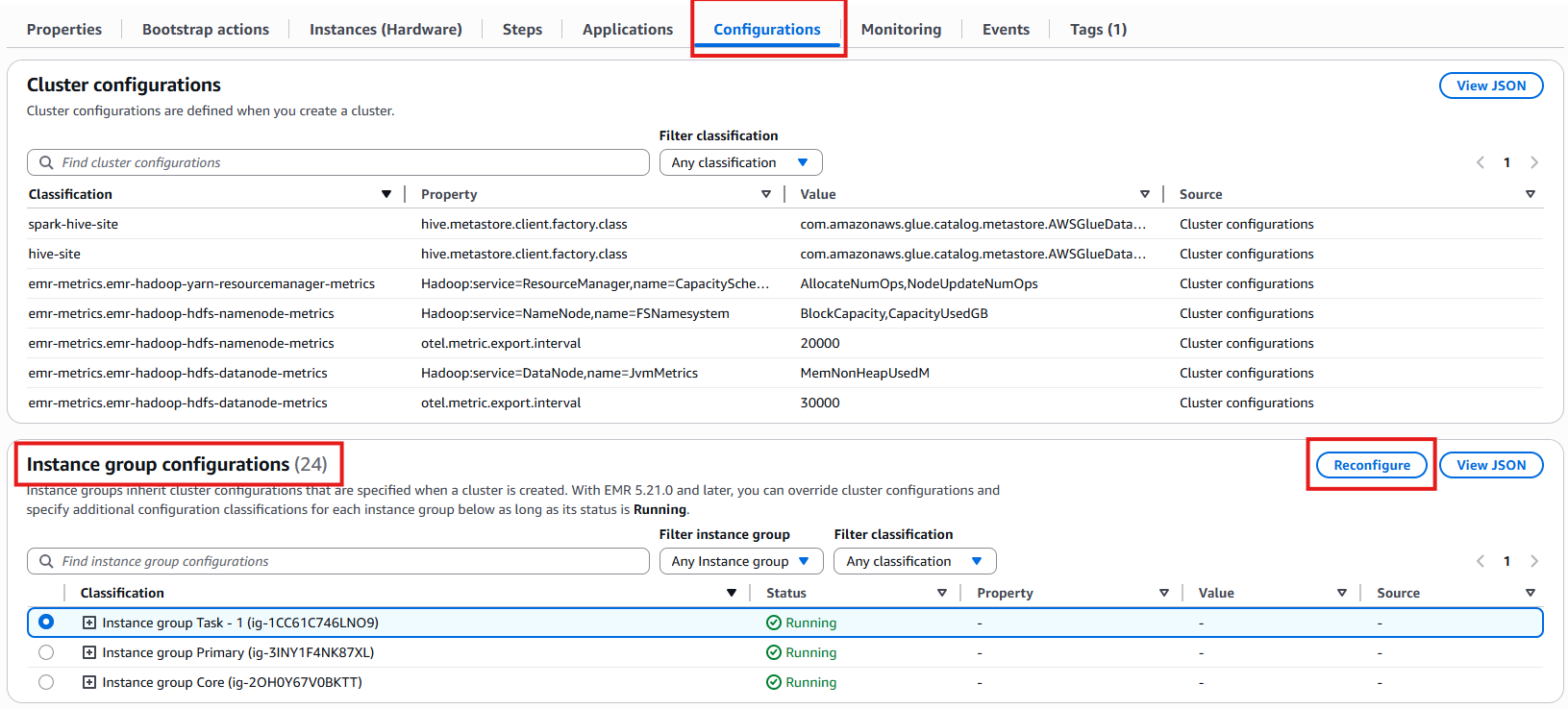
Configuraciones de grupos de instancias.
Validación de la integración CloudWatch
Tras completar los pasos de configuración, es el momento de comprobar que la configuración de supervisión funciona correctamente:
Paso 1: Implemente su clúster de EMR
-
Revise todos los ajustes de configuración para comprobar su precisión.
-
Asegúrese de que las acciones de arranque y los archivos de clasificación estén referenciados correctamente.
-
Haga clic en Crear clúster para iniciar su entorno EMR.
-
Espere a que el clúster alcance el estado En ejecución (normalmente de 5 a 15 minutos).
Paso 2: ejecutar aplicaciones de prueba
Envía varias aplicaciones de prueba a Spark para generar métricas significativas:
-
Ejecuta un trabajo sencillo de Spark que procese datos de muestra.
-
Ejecuta una tarea de análisis que dure más tiempo para observar la utilización de los recursos.
-
Pruebe diferentes configuraciones de aplicaciones para comparar las métricas de rendimiento.
Una vez finalizadas las aplicaciones (o mientras están en ejecución):
-
Navega hasta la CloudWatch consola.
-
Compruebe los grupos de registros configurados para ver los registros de las aplicaciones.
-
Examine los paneles de métricas para observar las métricas específicas de la CPU, la memoria y la aplicación.
-
Compruebe que las métricas personalizadas definidas en el archivo de clasificación aparezcan en. CloudWatch
Este proceso de validación confirma que su CloudWatch integración captura correctamente tanto los registros como las métricas, lo que le proporciona una visibilidad completa del rendimiento y el comportamiento de las aplicaciones de su clúster de EMR.
Acceso a los registros de EMR en CloudWatch grupos de registros
Una vez que el clúster de EMR esté en ejecución y el CloudWatch agente esté configurado correctamente, los registros de la aplicación y del sistema estarán disponibles en CloudWatch Registros. Siga estos pasos para acceder a ellos y analizarlos:
Visualización de sus grupos de registros
-
Navegue hasta la CloudWatch consola en AWS Management Console.
-
Seleccione Grupos de registros en el panel de navegación izquierdo.
-
Busque los grupos de registros creados por su configuración, como:
-
/emr/yarn/resourcemngerpara los ResourceManager registros de YARN.
-
/emr/hdfs/namenodepara NameNode registros HDFS.
-
Cualquier grupo de registros adicional especificado en el archivo de configuración.
-
Cada grupo de registros contiene flujos de registros organizados por ID de instancia, lo que le permite rastrear los registros hasta nodos específicos del clúster.
Trabajando con datos de registro
-
Busque datos de registro: utilice CloudWatch Logs Insights para realizar consultas estructuradas en sus grupos de registros.
-
Cree métricas: extraiga métricas de los patrones de registro para crear CloudWatch métricas personalizadas.
-
Configure alertas: configure las alarmas en función de patrones de error específicos o frecuencias de registro.
-
Exportación de registros: descargue los registros para analizarlos o archivarlos sin conexión.
Retención de registros
nota
De forma predeterminada, los registros se conservan durante 30 días. Puede modificar la política de retención de cada grupo de registros para conservar los registros durante períodos más largos si es necesario por motivos de cumplimiento o análisis.
CloudWatch Los registros proporcionan una ubicación centralizada para todos los datos de registro de EMR, lo que elimina la necesidad de usar SSH en los nodos individuales del clúster para solucionar problemas o analizar el comportamiento de las aplicaciones.
Visualización de métricas personalizadas en el panel de monitoreo de EMR
Una vez que el clúster de EMR se ejecute con el CloudWatch agente y la configuración de métricas personalizadas, puede supervisar fácilmente estas métricas directamente en la consola de EMR:
Acceder a sus métricas personalizadas
-
Navegue hasta el clúster de EMR en la consola de AWS administración.
-
Seleccione la pestaña Supervisión en la página de detalles del clúster.
-
Localice el menú desplegable de clasificación de métricas del filtro cerca de la parte superior de los paneles de monitoreo.
-
Utilice este filtro para seleccionar categorías de métricas específicas:
-
Elija HDFS para ver NameNode las DataNode métricas.
-
Seleccione YARN para ver ResourceManager y almacenar las métricas.
-
Elija HBasedatos HBase de rendimiento específicos.
-
Seleccione las clasificaciones de métricas personalizadas que haya definido.
-
El panel se actualizará de forma dinámica para mostrar gráficos de las métricas seleccionadas, que muestran las tendencias de rendimiento a lo largo del tiempo.
Trabajando con visualizaciones de métricas
-
Ajustar los intervalos de tiempo: cambie la ventana de tiempo para ver la actividad reciente o las tendencias históricas.
-
Compare las métricas: muestre varias métricas relacionadas side-by-side para el análisis de correlación.
-
Funciones de zoom: concéntrese en períodos de tiempo específicos en los que aparecen anomalías o patrones.
-
Actualice los datos: actualice las visualizaciones con los datos de métricas más recientes prácticamente en tiempo real.
Este enfoque de monitoreo integrado le permite realizar un seguimiento tanto de las métricas de EMR estándar como de las métricas personalizadas en un panel unificado, lo que facilita la identificación de los problemas de rendimiento, las limitaciones de recursos o los cuellos de botella de las aplicaciones sin salir de la consola de EMR.
CloudWatch métricas
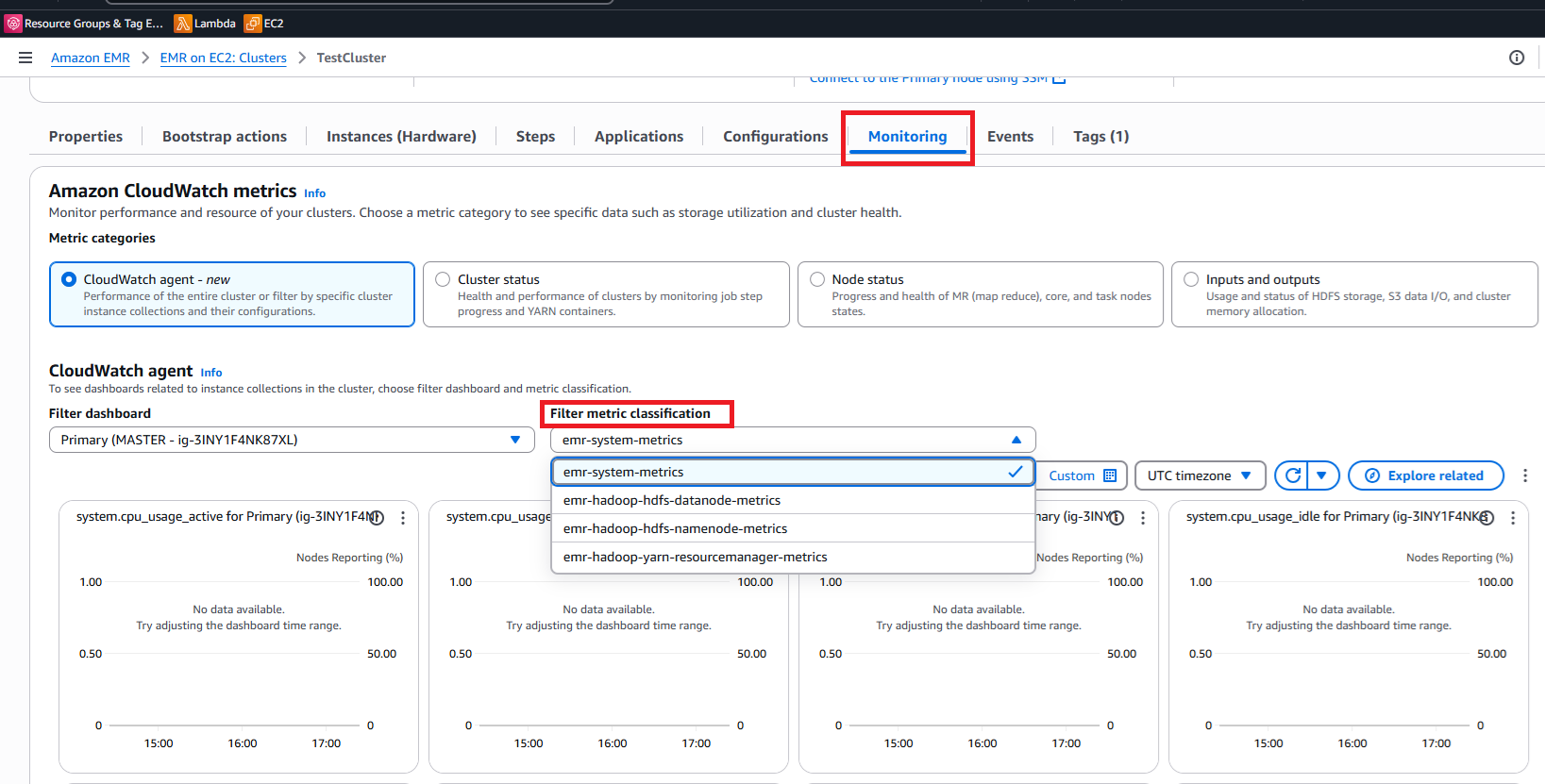
Filtrado y clasificación de métricas.
