Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Creación de un flujo de trabajo de coincidencia basado en reglas con el tipo de regla simple
El siguiente procedimiento muestra cómo crear un flujo de trabajo de coincidencia basado en reglas con el tipo de regla simple mediante la consola o la AWS Entity Resolution API. CreateMatchingWorkflow
- Console
-
Para crear un flujo de trabajo coincidente basado en reglas con la regla simple, utilice la consola
-
Inicie sesión en AWS Management Console y abra la AWS Entity Resolution consola en. https://console.aws.amazon.com/entityresolution/
-
En el panel de navegación izquierdo, en Flujos de trabajo, selecciona Matching.
-
En la página Flujos de trabajo coincidentes, en la esquina superior derecha, selecciona Crear flujo de trabajo coincidente.
-
Para el paso 1: especificar los detalles del flujo de trabajo coincidentes, haga lo siguiente:
-
Introduzca un nombre de flujo de trabajo coincidente y una descripción opcional.
-
Para la entrada de datos, elija una AWS Glue base de datos del menú desplegable, seleccione la AWS Glue tabla y, a continuación, el mapeo de esquema correspondiente.
Puede añadir hasta 19 entradas de datos.
-
La opción Normalizar datos está seleccionada de forma predeterminada, de modo que las entradas de datos se normalizan antes de que coincidan. Si no desea normalizar los datos, deseleccione la opción Normalizar datos.
nota
La normalización solo se admite en los siguientes escenarios en Crear mapeo de esquemas:
-
Si se agrupan los siguientes subtipos de nombres: nombre, segundo nombre, apellido.
-
Si se agrupan los siguientes subtipos de direcciones: dirección 1, dirección 2, dirección 3, ciudad, estado, país, código postal.
-
Si los siguientes subtipos de teléfono están agrupados: número de teléfono, código de país del teléfono.
-
-
Para especificar los permisos de acceso al servicio, elija una opción y lleve a cabo la acción recomendada.
Opción Acción recomendada Crear y usar un nuevo rol de servicio -
AWS Entity Resolution crea un rol de servicio con la política requerida para esta tabla.
-
El Nombre del rol de servicio predeterminado es
entityresolution-matching-workflow-<timestamp>. -
Debe tener permisos para crear roles y adjuntar políticas.
-
Si los datos de entrada están cifrados, puede elegir la opción Estos datos se cifran con una clave de KMS y, a continuación, introducir una AWS KMS clave que se utilizará para descifrar los datos introducidos.
Usar un rol de servicio existente -
Seleccione un Nombre de rol de servicio existente en la lista desplegable.
Si tiene permisos de listas de roles, se mostrará la lista de roles.
Si no tiene permisos de listas de roles, puede ingresar el nombre de recurso de Amazon (ARN) del rol que desea usar.
Si no hay ningún rol de servicio existente, la opción Usar un rol de servicio existente no estará disponible.
-
Consulte el rol de servicio mediante la elección del enlace externo Ver en IAM.
De forma predeterminada, AWS Entity Resolution no intenta actualizar la política de roles existente para añadir los permisos necesarios.
-
-
(Opcional) Para habilitar las etiquetas para el recurso, selecciona Añadir nueva etiqueta y, a continuación, introduce el par clave y valor.
-
Elija Siguiente.
-
-
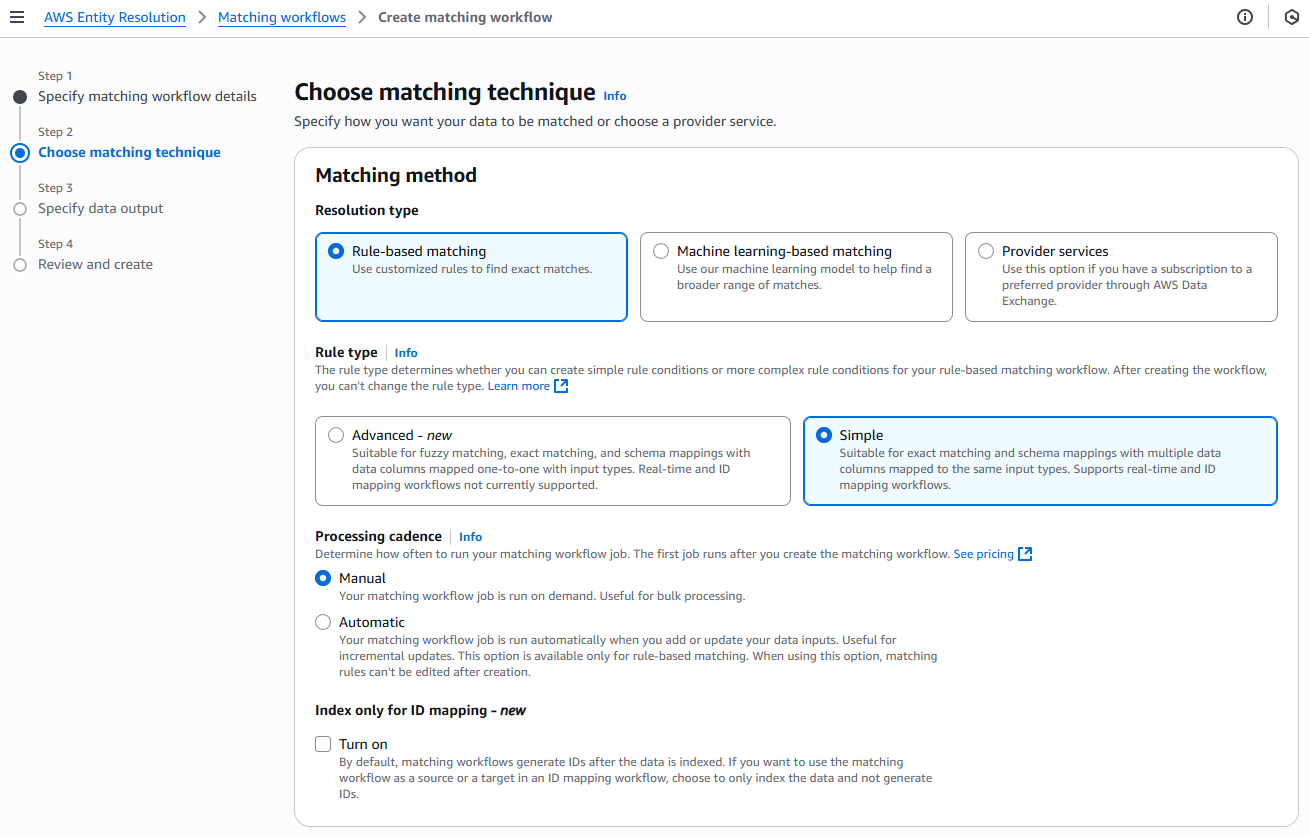
Para el paso 2: elija una técnica de coincidencia:
-
Para el método de coincidencia, elija la coincidencia basada en reglas.
-
En Tipo de regla, elija Simple.
-
En Cadencia de procesamiento, selecciona una de las siguientes opciones.
-
Seleccione Manual para ejecutar un flujo de trabajo bajo demanda para una actualización masiva
-
Elija Automático para ejecutar un flujo de trabajo en cuanto haya nuevos datos en su bucket de S3
nota
Si eliges Automático, asegúrate de tener activadas EventBridge las notificaciones de Amazon para tu bucket de S3. Para obtener instrucciones sobre cómo habilitar Amazon EventBridge mediante la consola S3, consulte Habilitar Amazon EventBridge en la Guía del usuario de Amazon S3.
-
-
(Opcional) En el caso de indexar únicamente los datos y no generarlos, puede optar por activar la opción de indexar únicamente los datos y no de generarlos IDs.
De forma predeterminada, el flujo de trabajo coincidente se genera IDs después de indexar los datos.
-
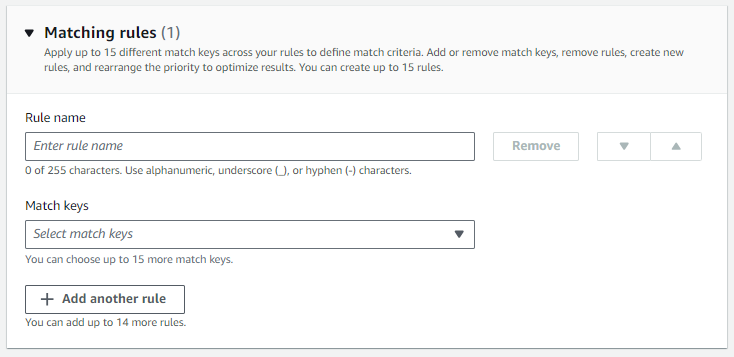
En Reglas de coincidencia, introduzca un nombre de regla y, a continuación, elija las claves de coincidencia para esa regla.
Puede crear hasta 15 reglas y aplicar hasta 15 claves de coincidencia diferentes a sus reglas para definir los criterios de coincidencia.
-
En el tipo de comparación, elija una de las siguientes opciones en función de su objetivo.
Su objetivo Opción recomendada Busque cualquier combinación de coincidencias entre los datos almacenados en varios campos de entrada Múltiples campos de entrada Limite la comparación a un solo campo de entrada Campo de entrada único 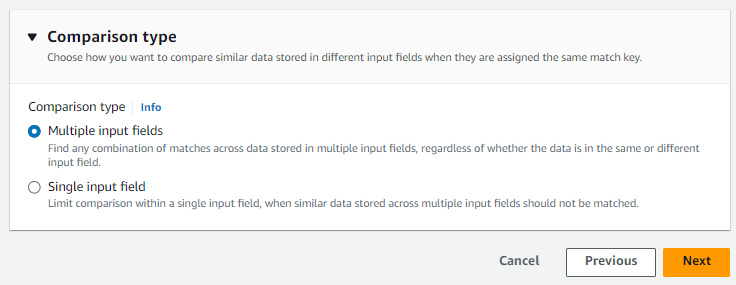
-
Elija Siguiente.
-
-
Para el paso 3: especifique la salida y el formato de los datos:
-
En Destino y formato de salida de datos, elija la ubicación de Amazon S3 para la salida de datos y si el formato de datos será Datos normalizados o Datos originales.
-
Para el cifrado, si elige personalizar la configuración de cifrado, introduzca la AWS KMS clave ARN.
-
Vea la salida generada por el sistema.
-
En el caso de la salida de datos, decide qué campos quieres incluir, ocultar o enmascarar y, a continuación, realiza las acciones recomendadas en función de tus objetivos.
Su objetivo Acción recomendada Incluya campos Mantenga el estado de salida como Incluido. Ocultar campos (excluirlos de la salida) Elija el campo de salida y, a continuación, elija Ocultar. Enmascarar campos Elija el campo de salida y, a continuación, elija Salida de hash. Restablece los ajustes anteriores Elija Restablecer. -
Elija Siguiente.
-
-
Para el paso 4: Revisa y crea:
-
Revise las selecciones que realizó en los pasos anteriores y edítelas si es necesario.
-
Elija Create and run.
Aparece un mensaje que indica que se ha creado el flujo de trabajo correspondiente y que el trabajo ha comenzado.
-
-
En la página de detalles del flujo de trabajo coincidente, en la pestaña Métricas, consulta lo siguiente en Métricas del último trabajo:
-
El identificador del trabajo.
-
El estado del trabajo de flujo de trabajo coincidente: en cola, en curso, completado, fallido
-
El tiempo de finalización del trabajo de flujo de trabajo.
-
El número de registros procesados.
-
El número de registros no procesados.
-
La coincidencia única IDs generada.
-
El número de registros de entrada.
También puede ver las métricas de trabajo para hacer coincidir los trabajos de flujo de trabajo que se han ejecutado anteriormente en el historial de trabajos.
-
-
Cuando se complete el trabajo del flujo de trabajo correspondiente (el estado es Completado), puede ir a la pestaña Salida de datos y, a continuación, seleccionar su ubicación de Amazon S3 para ver los resultados.
-
(Solo tipo de procesamiento manual) Si ha creado un flujo de trabajo coincidente basado en reglas con el tipo de procesamiento manual, puede ejecutar el flujo de trabajo coincidente en cualquier momento seleccionando Ejecutar flujo de trabajo en la página de detalles del flujo de trabajo coincidente.
-
- API
-
Para crear un flujo de trabajo coincidente basado en reglas con la regla simple, escriba mediante la API
nota
De forma predeterminada, el flujo de trabajo utiliza el procesamiento estándar (por lotes). Para utilizar el procesamiento incremental (automático), debe configurarlo de forma explícita.
-
Abre una terminal o una línea de comandos para realizar la solicitud a la API.
-
Crea una solicitud POST para el siguiente punto final:
/matchingworkflows -
En el encabezado de la solicitud, establece el tipo de contenido en application/json.
-
Para el cuerpo de la solicitud, proporciona los siguientes parámetros JSON obligatorios:
{ "description": "string", "incrementalRunConfig": { "incrementalRunType": "string" }, "inputSourceConfig": [ { "applyNormalization":boolean, "inputSourceARN": "string", "schemaName": "string" } ], "outputSourceConfig": [ { "applyNormalization":boolean, "KMSArn": "string", "output": [ { "hashed": boolean, "name": "string" } ], "outputS3Path": "string" } ], "resolutionTechniques": { "providerProperties": { "intermediateSourceConfiguration": { "intermediateS3Path": "string" }, "providerConfiguration":JSON value, "providerServiceArn": "string" }, "resolutionType": "RULE_MATCHING", "ruleBasedProperties": { "attributeMatchingModel": "string", "matchPurpose": "string", "rules": [ { "matchingKeys": [ "string" ], "ruleName": "string" } ] }, "ruleConditionProperties": { "rules": [ { "condition": "string", "ruleName": "string" } ] } }, "roleArn": "string", "tags": { "string" : "string" }, "workflowName": "stringDonde:
-
workflowName(obligatorio): debe ser único y debe coincidir con un patrón de entre 1 y 255 caracteres [a-zA-Z_0-9-] * -
inputSourceConfig(obligatorio): lista de 1 a 20 configuraciones de fuentes de entrada -
outputSourceConfig(obligatorio): exactamente una configuración de fuente de salida -
resolutionTechniques(obligatorio): establézcalo en «RULE_MATCHING» para una coincidencia basada en reglas -
roleArn(obligatorio): ARN del rol de IAM para la ejecución del flujo de trabajo -
ruleConditionProperties(obligatorio): lista de las condiciones de la regla y el nombre de la regla coincidente.
Los parámetros opcionales incluyen:
-
description— Hasta 255 caracteres -
incrementalRunConfig— Configuración del tipo de ejecución incremental -
tags— Hasta 200 pares clave-valor
-
-
(Opcional) Para utilizar el procesamiento incremental en lugar del procesamiento estándar (por lotes) predeterminado, añada el siguiente parámetro al cuerpo de la solicitud:
"incrementalRunConfig": { "incrementalRunType": "AUTOMATIC" } -
Envíe la solicitud .
-
Si se ejecuta correctamente, recibirás una respuesta con el código de estado 200 y un cuerpo JSON que contiene:
{ "workflowArn": "string", "workflowName": "string", // Plus all configured workflow details } -
Si la llamada no se realiza correctamente, es posible que recibas uno de los siguientes errores:
-
400: ConflictException si el nombre del flujo de trabajo ya existe
-
400: ValidationException si la entrada no pasa la validación
-
402: ExceedsLimitException si se superan los límites de la cuenta
-
403: AccessDeniedException si no tienes acceso suficiente
-
429 — ThrottlingException si la solicitud fue restringida
-
500: InternalServerException si se produce un fallo en el servicio interno
-
-
