Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Conexiones Redshift
Puede usar AWS Glue for Spark para leer y escribir en tablas de bases de datos de Amazon Redshift. Al conectarse a las bases de datos de Amazon Redshift, AWS Glue mueve los datos a través de Amazon S3 para lograr el máximo rendimiento mediante el SQL y los comandos de Amazon Redshift. COPY UNLOAD En AWS Glue 4.0 y versiones posteriores, puede utilizar la integración de Amazon Redshift para Apache Spark para leer y escribir con optimizaciones y funciones específicas de Amazon Redshift además de las disponibles al conectarse a través de versiones anteriores.
Descubra cómo AWS Glue facilita más que nunca a los usuarios de Amazon Redshift la migración a AWS Glue para la integración de datos sin servidor y la ETL.
Configuración de las conexiones de Redshift
Para utilizar los clústeres de Amazon Redshift en AWS Glue, necesitará algunos requisitos previos:
-
Un directorio de Amazon S3 para utilizar como almacenamiento temporario al leer y escribir en la base de datos.
-
Una Amazon VPC que permita la comunicación entre su clúster de Amazon Redshift, su trabajo de AWS Glue y su directorio de Amazon S3.
-
Permisos de IAM adecuados en el trabajo de AWS Glue y el clúster de Amazon Redshift.
Configuración de roles de IAM
Configurar la función para el clúster de Amazon Redshift
Su clúster de Amazon Redshift debe poder leer y escribir en Amazon S3 para poder integrarse con los trabajos de AWS Glue. Para ello, puede asociar los roles de IAM al clúster de Amazon Redshift al que desee conectarse. Su función debe tener una política que permita leer y escribir en su directorio temporario de Amazon S3. Su función debe tener una relación de confianza que permita al redshift.amazonaws.comservicio hacerloAssumeRole.
Para asociar un rol de IAM a Amazon Redshift
Requisitos previos: un bucket o directorio de Amazon S3 utilizado para el almacenamiento temporario de archivos.
-
Identifique qué permisos de Amazon S3 necesitará su clúster de Amazon Redshift. Al mover datos hacia y desde un clúster de Amazon Redshift, los trabajos de AWS Glue emiten declaraciones COPY y UNLOAD contra Amazon Redshift. Si su trabajo modifica una tabla en Amazon Redshift, AWS Glue también emitirá instrucciones CREATE LIBRARY. Para obtener información sobre los permisos específicos de Amazon S3 necesarios para que Amazon Redshift ejecute estas instrucciones, consulte la documentación de Amazon Redshift: Amazon Redshift: Permissions to access other Resources. AWS
En la consola de IAM, cree una política de IAM con los permisos necesarios. Para obtener más información sobre cómo crear una política de IAM, consulte Creación de políticas de IAM.
En la consola de IAM, cree un rol y una relación de confianza que permita a Amazon Redshift asumir el rol. Siga las instrucciones de la documentación de IAM para crear un rol para un AWS servicio (consola)
Cuando se le pida que elija un caso de uso del AWS servicio, elija «Redshift: personalizable».
Cuando se pida que adjunte una política, elija la política que definió previamente.
nota
Para obtener más información sobre la configuración de funciones para Amazon Redshift, consulte Autorizar a Amazon Redshift a acceder a otros AWS servicios en su nombre en la documentación de Amazon Redshift.
En la consola de Amazon Redshift, asocie la función a su clúster de Amazon Redshift. Siga las instrucciones de la documentación de Amazon Redshift.
Seleccione la opción resaltada en la consola de Amazon Redshift para configurar este ajuste:
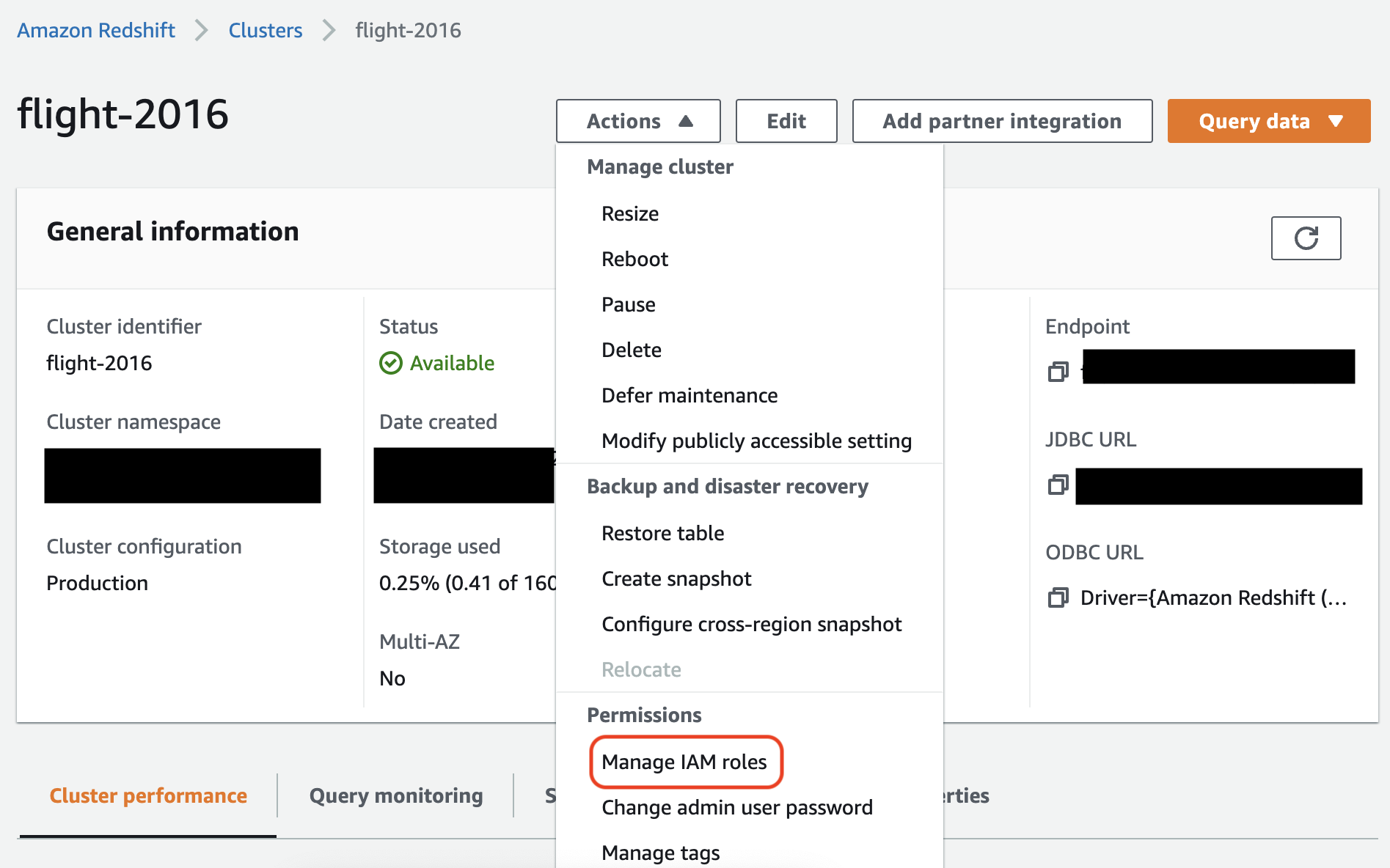
nota
De forma predeterminada, los trabajos de AWS Glue pasan las credenciales temporales de Amazon Redshift que se crean con el rol que especificó para ejecutar el trabajo. No recomendamos utilizar estas credenciales. Por motivos de seguridad, estas credenciales caducan después de 1 hora.
Configura el rol para el trabajo de AWS Glue
El trabajo de AWS Glue necesita un rol para acceder al bucket de Amazon S3. No necesita permisos de IAM para el clúster de Amazon Redshift, su acceso se controla mediante la conectividad de la VPC de Amazon y las credenciales de su base de datos.
Configuración de VPC de Amazon
Para configurar el acceso a almacenes de datos de Amazon Redshift
-
En el panel de navegación izquierdo, elija Clusters (Clústeres).
-
Seleccione el nombre de clúster al que desee obtener acceso desde AWS Glue.
-
En la sección Cluster Properties (Propiedades del clúster), elija un grupo de seguridad en VPC security groups (Grupos de seguridad de la VPC) para permitir a AWS Glue utilizarlo. Registre el nombre del grupo de seguridad que ha elegido para futuras referencias. Al elegir el grupo de seguridad se abrirá la lista de Security Groups (Grupos de seguridad) de la consola de Amazon EC2.
-
Elija el grupo de seguridad para modificar e ir a la pestaña Inbound (Entrada).
-
Añada una regla con autorreferencia para que los componentes de AWS Glue puedan comunicarse. En concreto, añada o confirme que hay una regla con Type (Tipo)
All TCP, Protocol (Protocolo)TCP, Port Range (Intervalo de puertos) con todos los puertos y el Source (Origen) con el mismo nombre de grupo de seguridad que Group ID (ID de grupo).La regla de entrada tiene un aspecto similar al siguiente:
Tipo Protocolo Rango de puerto Origen Todos los TCP
TCP
0–65535
database-security-group
Por ejemplo:

-
Añada también una regla para el tráfico saliente. Puede abrir el tráfico saliente con destino a todos los puertos, por ejemplo:
Tipo Protocolo Rango de puerto Destino All Traffic
ALL
ALL
0.0.0.0/0
O bien, crear una regla con autorreferencia en la que Type (Tipo) sea
All TCP, Protocol (Protocolo) seaTCP, Port Range (Intervalo de puertos) incluya todos los puertos y Destination (Destino) sea el mismo nombre de grupo de seguridad que Group ID (ID de grupo). En caso de que se utilice un punto de enlace de la VPC de Amazon S3, agregue también una regla HTTPS para el acceso de Amazon S3. Els3- prefix-list-ides obligatorio en la regla del grupo de seguridad para permitir el tráfico desde la VPC al punto final de la VPC de Amazon S3.Por ejemplo:
Tipo Protocolo Rango de puerto Destino Todos los TCP
TCP
0–65535
security-groupHTTPS
TCP
443
s3- prefix-list-id
Configurar AWS Glue
Deberás crear una conexión al catálogo de datos de AWS Glue que proporcione la información de conexión de Amazon VPC.
Para configurar la conectividad de Amazon Redshift y Amazon VPC con Glue en la consola AWS
-
Cree una conexión al catálogo de datos mediante los pasos que se indican en: Adición de una conexión de AWS Glue. Tras crear la conexión, conserve el nombre de la conexión,
connectionName, para el siguiente paso.Al seleccionar un tipo de conexión, seleccione Amazon Redshift.
Al seleccionar un clúster de Redshift, seleccione el clúster por su nombre.
Proporcione la información de conexión predeterminada para un usuario de Amazon Redshift en su clúster.
La configuración de VPC de Amazon se configurará automáticamente.
nota
Deberá proporcionar manualmente
PhysicalConnectionRequirementssu VPC de Amazon al crear una conexión de Amazon Redshift a través del SDK AWS . -
En la configuración de la tarea de AWS Glue, proporciona
ConnectionNamecomo conexión de red adicional.
Ejemplo: lectura de tablas de Amazon Redshift
Puede leer los clústeres desde Amazon Redshift y los entornos de Amazon Redshift sin servidor.
Requisitos previos: una tabla de Amazon Redshift de la que quiera leer. Siga los pasos de la sección anterior, Configuración de las conexiones de Redshift después de lo cual debería tener el URI de Amazon S3 para un directorio temporal, temp-s3-dir, y un rol de IAM rs-role-name, (en la cuenta). role-account-id
Ejemplo: escribir en tablas de Amazon Redshift
Puede leer los clústeres desde Amazon Redshift y los entornos de Amazon Redshift sin servidor.
Requisitos previos: un clúster de Amazon Redshift y siga los pasos de la Configuración de las conexiones de Redshift sección anterior, tras lo cual deberá disponer del URI de Amazon S3 para un directorio temporal, temp-s3-dir, y un rol de IAM, (en la cuenta). rs-role-name También necesitará un role-account-idDynamicFrame cuyos contenido desee escribir en la base de datos.
Referencia de opción de conexión a Amazon Redshift
Las opciones de conexión básicas que se utilizan en todas las conexiones JDBC de AWS Glue permiten configurar información similar url a la de todos los tipos de JDBC user y password son coherentes en todos los tipos de JDBC. Para obtener más información acerca de los parámetros de JDBC, consulte Referencia de opciones de conexión de JDBC.
El tipo de conexión Amazon Redshift requiere algunas opciones de conexión adicionales:
-
"redshiftTmpDir": (Obligatorio) La ruta de Amazon S3 donde se pueden almacenar datos temporarios al copiar desde la base de datos. -
"aws_iam_role": (Opcional) ARN para un rol de IAM. La tarea de AWS Glue transferirá esta función al clúster de Amazon Redshift para conceder al clúster los permisos necesarios para completar las instrucciones de la tarea.
Opciones de conexión adicionales disponibles en AWS Glue 4.0+
También puede transferir opciones para el nuevo conector Amazon Redshift a través de las opciones de conexión de AWS Glue. Para obtener una lista completa de las opciones de conectores compatibles, consulte la sección Spark SQL parameters (Parámetros de Spark SQL) en Amazon Redshift integration for Apache Spark (Integración de Amazon Redshift para Apache Spark).
Para su comodidad, aquí reiteramos algunas opciones nuevas:
| Nombre | Obligatoria | Predeterminado | Descripción |
|---|---|---|---|
| autopushdown |
No | TRUE | Aplica la inserción de predicados y consultas mediante la captura y el análisis de los planes lógicos de Spark para operaciones de SQL. Las operaciones se traducen en una consulta SQL y, a continuación, se ejecutan en Amazon Redshift para mejorar el rendimiento. |
| autopushdown.s3_result_cache |
No | FALSE | Almacena en caché la consulta SQL para descargar datos de la asignación de rutas de Amazon S3 en la memoria, de modo que no sea necesario volver a ejecutar la misma consulta en la misma sesión de Spark. Solo se admite cuando la opción |
| unload_s3_format |
No | PARQUET | PARQUET: descarga los resultados de la consulta en formato Parquet. TEXT: descarga los resultados de la consulta en formato de texto delimitado por barras. |
| sse_kms_key |
No | N/A | La clave AWS SSE-KMS que se utilizará para el cifrado durante |
| extracopyoptions |
No | N/A | Lista de opciones adicionales que se anexarán al comando Tenga en cuenta que, dado que estas opciones se anexan al final del comando |
| csvnullstring (experimental) |
No | NULL | Valor de cadena que se escribirá para los valores nulos cuando se utiliza el valor de |
Estos nuevos parámetros se pueden utilizar de las siguientes maneras.
Nuevas opciones para mejorar el rendimiento
El nuevo conector presenta algunas opciones nuevas de mejora del rendimiento:
-
autopushdown: habilitada de forma predeterminada. -
autopushdown.s3_result_cache: deshabilitada de forma predeterminada. -
unload_s3_format:PARQUETde forma predeterminada.
Para obtener información sobre el uso de estas opciones, consulte Amazon Redshift integration for Apache Spark (Integración de Amazon Redshift para Apache Spark). Le recomendamos que no active
autopushdown.s3_result_cache cuando tenga operaciones de lectura y escritura mixtas, ya que los resultados almacenados en caché pueden contener información obsoleta. La opción unload_s3_format se define como PARQUET de forma predeterminada para el comando UNLOAD a fin de mejorar el rendimiento y reducir el costo de almacenamiento. Para utilizar el comportamiento predeterminado del comando UNLOAD, restablezca la opción a TEXT.
Nueva opción de cifrado para lectura
De forma predeterminada, los datos de la carpeta temporal que AWS Glue utiliza al leer datos de la tabla de Amazon Redshift se cifran mediante el cifrado SSE-S3. Si quieres usar claves administradas por el cliente desde AWS Key Management Service (AWS KMS) para cifrar tus datos, puedes configurar el identificador de clave que ("sse_kms_key"
→ kmsKey) corresponde a KsmKey AWS KMS, en lugar de usar la opción de configuración antigua de la versión 3.0. ("extraunloadoptions" →
s"ENCRYPTED KMS_KEY_ID '$kmsKey'") AWS Glue
datasource0 = glueContext.create_dynamic_frame.from_catalog( database = "database-name", table_name = "table-name", redshift_tmp_dir = args["TempDir"], additional_options = {"sse_kms_key":"<KMS_KEY_ID>"}, transformation_ctx = "datasource0" )
Compatibilidad con URL de JDBC basadas en IAM
El nuevo conector admite una URL de JDBC basada en IAM, por lo que no es necesario pasar un usuario o contraseña ni un secreto. Con una URL de JDBC basada en IAM, el conector utiliza el rol de tiempo de ejecución del trabajo para acceder al origen de datos de Amazon Redshift.
Paso 1: adjunte la siguiente política mínima requerida a su rol de tiempo de ejecución del trabajo de AWS Glue.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": "redshift:GetClusterCredentials", "Resource": [ "arn:aws:redshift:<region>:<account>:dbgroup:<cluster name>/*", "arn:aws:redshift:*:<account>:dbuser:*/*", "arn:aws:redshift:<region>:<account>:dbname:<cluster name>/<database name>" ] }, { "Sid": "VisualEditor1", "Effect": "Allow", "Action": "redshift:DescribeClusters", "Resource": "*" } ] }
Paso 2: utilice la URL de JDBC basada en IAM de la siguiente manera. Especifique una nueva opción DbUser con el nombre de usuario de Amazon Redshift con el que se está conectando.
conn_options = { // IAM-based JDBC URL "url": "jdbc:redshift:iam://<cluster name>:<region>/<database name>", "dbtable": dbtable, "redshiftTmpDir": redshiftTmpDir, "aws_iam_role": aws_iam_role, "DbUser": "<Redshift User name>" // required for IAM-based JDBC URL } redshift_write = glueContext.write_dynamic_frame.from_options( frame=dyf, connection_type="redshift", connection_options=conn_options ) redshift_read = glueContext.create_dynamic_frame.from_options( connection_type="redshift", connection_options=conn_options )
nota
Actualmente, un DynamicFrame solo admite una URL de JDBC basada en IAM con un valor de
DbUser en el flujo de trabajo de GlueContext.create_dynamic_frame.from_options.
Migración de la versión 3.0 de AWS Glue a la versión 4.0
En AWS Glue 4.0, los trabajos de ETL tienen acceso a un nuevo conector Amazon Redshift Spark y a un nuevo controlador JDBC con diferentes opciones y configuraciones. El nuevo conector y controlador de Amazon Redshift están diseñados con el rendimiento como objetivo y mantienen la coherencia transaccional de los datos. Estos productos están registrados en la documentación de Amazon Redshift. Para obtener más información, consulte:
-
Amazon Redshift integration for Apache Spark (Integración de Amazon Redshift para Apache Spark)
-
Amazon Redshift JDBC driver, version 2.1 (Controlador JDBC versión 2.1 de Amazon Redshift)
Restricción de identificadores y nombres de tablas o columnas
El nuevo conector y el controlador de Spark para Amazon Redshift tienen un requisito más restringido para el nombre de tablas de Redshift. Si necesita más información, consulte Nombres e identificadores para definir el nombre de una tabla de Amazon Redshift. Es posible que el flujo de trabajo de marcador de trabajo no funcione con un nombre de tabla que no coincida con las reglas y con ciertos caracteres, como un espacio.
Si tiene tablas heredadas con nombres que no se ajustan a las reglas indicadas en Nombres e identificadores y tiene problemas con los marcadores (los trabajos vuelven a procesar datos antiguos de tablas de Amazon Redshift), le recomendamos que cambie el nombre de las tablas. Para obtener más información, consulte Ejemplos de ALTER TABLE.
Cambio de tempformat predeterminado en DataFrame
El conector de Spark de la versión 3.0 de AWS Glue establece de forma predeterminada el valor de tempformat en CSV al escribir en Amazon Redshift. Para mantener la coherencia, en la versión 3.0 de AWS Glue, el
DynamicFrame sigue estableciendo el valor predeterminado de tempformat para usar CSV. Si ha utilizado con anterioridad las API de Dataframe de Spark directamente con el conector de Spark para Amazon Redshift, puede establecer el tempformat en CSV en las opciones DataframeReader o Writer. De lo contrario, tempformat adopta AVRO como valor predeterminado en el nuevo conector de Spark.
Cambio de conducta: asignación del tipo de datos REAL de Amazon Redshift al tipo de datos FLOAT de Spark en lugar de DOUBLE
En la versión 3.0 de AWS Glue, el tipo REAL de Amazon Redshift se convierte a un tipo
DOUBLE de Spark. El nuevo conector de Spark para Amazon Redshift ha actualizado el comportamiento para que el tipo
REAL de Amazon Redshift se convierta al tipo FLOAT de Spark y viceversa. Si tiene un caso de uso heredado en el que aún desea que el tipo REAL de Amazon Redshift se asigne a un tipo DOUBLE de Spark, puede utilizar la siguiente solución alternativa:
-
En el caso de un
DynamicFrame, asigna el tipoFloata un tipoDoubleconDynamicFrame.ApplyMapping. En el caso de unDataframe, tiene que usarcast.
Ejemplo de código:
dyf_cast = dyf.apply_mapping([('a', 'long', 'a', 'long'), ('b', 'float', 'b', 'double')])
