Tutorial: Escritura de un script de Glue for Spark AWS
Este tutorial ofrece una introducción al proceso de escritura de scripts de AWS Glue. Puede ejecutar scripts de manera programada con trabajos, o bien de manera interactiva con sesiones interactivas. Para obtener más información acerca de las tareas, consulta Creación de trabajos de ETL visual. Para más información sobre las sesiones interactivas, consulte Información general sobre las sesiones interactivas de AWS Glue.
El editor visual de AWS Glue Studio ofrece una interfaz gráfica, sin código, para crear trabajos con AWS Glue. AWS Agregue los scripts de Glue otra vez en los trabajos visuales. Le dan acceso al conjunto ampliado de herramientas disponibles para trabajar con los programas de Apache Spark. Puede acceder a API nativas de Spark, así como a bibliotecas de AWS Glue que facilitan los flujos de trabajo de extracción, transformación y carga (ETL) desde un script de AWS Glue.
En este tutorial, extraerá, transformará y cargará un conjunto de datos de multas de estacionamiento. El script que realiza este trabajo es idéntico, tanto en forma como en función, al generado en Making ETL easier with AWS Glue Studio
En este tutorial utilizará lenguaje y bibliotecas Python. Scala dispone de funcionalidad similar. Después de seguir este tutorial, debería poder generar e inspeccionar un script de Scala de ejemplo para comprender cómo llevar a cabo el proceso de escritura de scripts de ETL de AWS Glue de Scala.
Requisitos previos
Este tutorial tiene los requisitos previos siguientes:
-
Los mismos requisitos previos que en la publicación del blog de AWS Glue Studio, en la que se indica cómo ejecutar una plantilla de AWS CloudFormation.
Esta plantilla usa el catálogo de datos de AWS Glue para administrar el conjunto de datos de multas de estacionamiento disponible en
s3://aws-bigdata-blog/artifacts/gluestudio/. Crea los siguientes recursos a los que se hará referencia: -
AWS Glue StudioRole (Rol): rol de IAM que ejecuta trabajos de AWS Glue
-
AWS Glue StudioAmazon S3 Bucket (Bucket de Amazon S3): nombre del bucket de Amazon S3 para almacenar archivos relacionados con el blog
-
AWS Glue StudioTicketsYYZDB: base de datos de AWS Glue Data Catalog
-
AWS Glue StudioTableTickets: tabla de Data Catalog que se usará como origen
-
AWS Glue StudioTableTrials: tabla de Data Catalog que se usará como origen
-
AWS Glue StudioParkingTicketCount: tabla de Data Catalog que se usará como destino
-
El script generado en la publicación del blog de AWS Glue Studio. En caso de que la publicación se modifique, el script también está disponible en el siguiente texto.
Generación de un script de ejemplo
El editor visual de AWS Glue Studio es una potente herramienta de generación de código que puede usar para crear una estructura que sirva de base para el script que quiera escribir. Utilizará esta herramienta para crear un script de ejemplo.
Si quiere omitir estos pasos, se proporciona el script.
import sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job args = getResolvedOptions(sys.argv, ["JOB_NAME"]) sc = SparkContext() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) job.init(args["JOB_NAME"], args) # Script generated for node S3 bucket S3bucket_node1 = glueContext.create_dynamic_frame.from_catalog( database="yyz-tickets", table_name="tickets", transformation_ctx="S3bucket_node1" ) # Script generated for node ApplyMapping ApplyMapping_node2 = ApplyMapping.apply( frame=S3bucket_node1, mappings=[ ("tag_number_masked", "string", "tag_number_masked", "string"), ("date_of_infraction", "string", "date_of_infraction", "string"), ("ticket_date", "string", "ticket_date", "string"), ("ticket_number", "decimal", "ticket_number", "float"), ("officer", "decimal", "officer_name", "decimal"), ("infraction_code", "decimal", "infraction_code", "decimal"), ("infraction_description", "string", "infraction_description", "string"), ("set_fine_amount", "decimal", "set_fine_amount", "float"), ("time_of_infraction", "decimal", "time_of_infraction", "decimal"), ], transformation_ctx="ApplyMapping_node2", ) # Script generated for node S3 bucket S3bucket_node3 = glueContext.write_dynamic_frame.from_options( frame=ApplyMapping_node2, connection_type="s3", format="glueparquet", connection_options={"path": "s3://DOC-EXAMPLE-BUCKET", "partitionKeys": []}, format_options={"compression": "gzip"}, transformation_ctx="S3bucket_node3", ) job.commit()
Para generar un script de ejemplo
-
Complete el tutorial de AWS Glue Studio. Para completar este tutorial, consulte Creación de un trabajo en AWS Glue Studio a partir de un ejemplo de trabajo.
-
Vaya a la pestaña Script de la página de trabajo, tal como se muestra en la siguiente captura de pantalla:
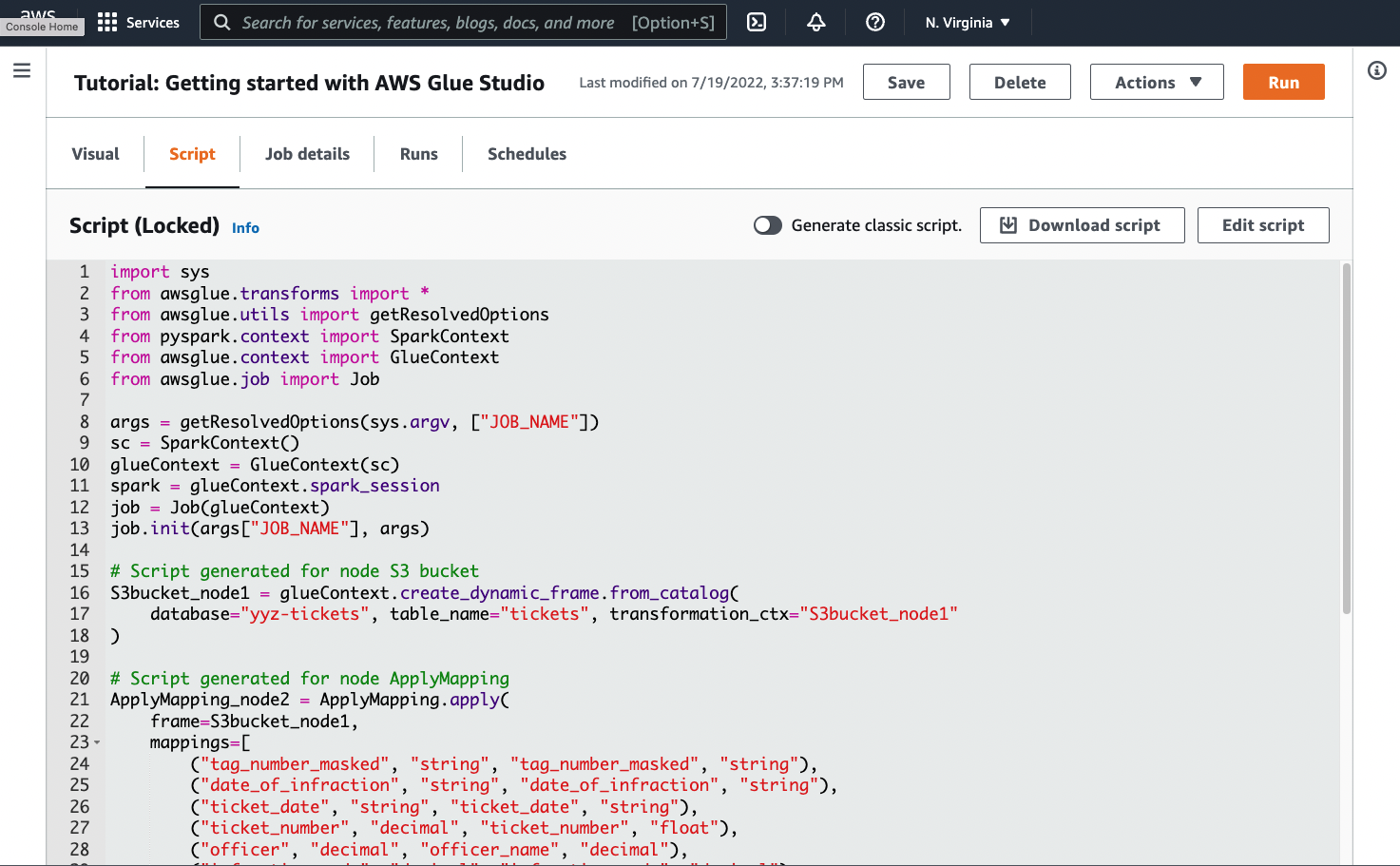
-
Copie el contenido completo de la pestaña Script. Configurando el lenguaje en Job details (Detalles del trabajo), puede cambiar y alternar entre generar código Python o Scala.
Paso 1. Crear un trabajo y pegar el script
En este paso, se crea un trabajo de AWS Glue en la AWS Management Console. De esta forma, se establece una configuración que permite que AWS Glue ejecute el script. Además, crea un lugar donde almacenar y editar el script.
Para crear una tarea
-
En la AWS Management Console, vaya a la página de inicio de AWS Glue.
-
En el panel de navegación lateral, seleccione Trabajos.
-
Elija Editor de scripts de Spark en Crear trabajo, a continuación, elija Crear.
-
Opcional Pegue todo el texto del script en el panel Script. Como alternativa, puede seguir el tutorial.
Paso 2. Importar bibliotecas de AWS Glue
Es necesario configurar el script para que interactúe con el código y la configuración que se definen fuera del script. Ese trabajo se realiza entre bastidores en AWS Glue Studio.
En este tutorial, se realizan las siguientes acciones.
-
Importar e inicializar un objeto de
GlueContext. Esta es la importación más importante, desde la perspectiva de la escritura de scripts. Esto expone métodos estándar para definir los conjuntos de datos de origen y de destino, que es el punto de partida de cualquier script ETL. Para obtener más información sobre la claseGlueContext, consulte Clase GlueContext. -
Inicializar una clase
SparkContexty una claseSparkSession. Con ellas, puede configurar el motor de Spark disponible en el trabajo de AWS Glue. No necesitará utilizarlas directamente en scripts introductorios de AWS Glue. -
Llamar a
getResolvedOptionscon el fin de preparar los argumentos del trabajo para su uso en el script. Para obtener más información sobre la resolución de parámetros de trabajo, consulte Acceso a los parámetros mediante getResolvedOptions. -
Inicializar un objeto
Job. El objetoJobestablece la configuración y hace un seguimiento del estado de diversas características de AWS Glue. El script puede ejecutarse sin un objetoJob, pero lo mejor es inicializarlo para que no se produzcan confusiones si esas funciones se integran posteriormente.Una de esas características son los marcadores de trabajo, que puede configurar de manera opcional en este tutorial. Puede obtener información sobre los marcadores de trabajo en la siguiente sección, Opcional: habilitar marcadores de trabajo.
En este procedimiento, escribirá el siguiente código. Este código es una parte del script de ejemplo generado.
from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job args = getResolvedOptions(sys.argv, ["JOB_NAME"]) sc = SparkContext() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) job.init(args["JOB_NAME"], args)
Para importar bibliotecas de AWS Glue
-
Copie esta sección de código y péguela en el editor de Script.
nota
Es posible que copiar código le parezca una mala práctica de ingeniería. En este tutorial, sugerimos hacerlo para animarle a poner nombre de manera sistemática a las variables principales en todos los scripts de ETL de AWS Glue.
Paso 3. Extraer datos de un origen
En cualquier proceso de ETL, primero se debe definir el conjunto de datos de origen que quiere cambiar. En el editor visual de AWS Glue Studio, esta información se proporciona creando un nodo Source (Origen).
En este paso, se proporciona el método create_dynamic_frame.from_catalog, un database y table_name, para extraer datos de un origen configurado en el Catálogo de datos de AWS Glue.
En el paso anterior, se inicializó un objeto GlueContext. Ese objeto se emplea para buscar métodos que se utilizan para configurar orígenes, como create_dynamic_frame.from_catalog.
En este procedimiento, escribirá el siguiente código utilizando create_dynamic_frame.from_catalog. Este código es una parte del script de ejemplo generado.
S3bucket_node1 = glueContext.create_dynamic_frame.from_catalog( database="yyz-tickets", table_name="tickets", transformation_ctx="S3bucket_node1" )
Para extraer datos de un origen
-
Examine la documentación para encontrar un método en
GlueContextpara extraer datos de un origen definido en el Catálogo de datos de AWS Glue. Estos métodos están documentados en Clase GlueContext. Elija el método create_dynamic_frame.from_catalog. Llame a este método englueContext. -
Examine la documentación de
create_dynamic_frame.from_catalog. Este método necesita los parámetrosdatabaseytable_name. Proporcione los parámetros necesarios acreate_dynamic_frame.from_catalog.El Catálogo de datos de AWS Glue almacena información sobre la ubicación y el formato de los datos de origen, y se configuró en la sección de requisitos previos. No es necesario proporcionar directamente esa información al script.
-
Opcional: proporcione el parámetro
transformation_ctxal método para que se admitan marcadores de trabajo. Puede obtener información sobre los marcadores de trabajo en la siguiente sección, Opcional: habilitar marcadores de trabajo.
nota
Métodos habituales para extraer datos
create_dynamic_frame_from_catalog se utiliza para conectarse a tablas del Catálogo de datos de AWS Glue.
Si necesita proporcionar directamente al trabajo una configuración que describa la estructura y ubicación del origen, consulte el método create_dynamic_frame_from_options. Deberá proporcionar parámetros más detallados que describan los datos que si se utiliza create_dynamic_frame.from_catalog.
Consulte la documentación suplementaria sobre format_options y connection_parameters para identificar los parámetros necesarios. Para ver una explicación sobre cómo proporcionar al script información sobre el formato de los datos de origen, consulte Opciones de formato de datos para las entradas y las salidas en AWS Glue para Spark. Para ver una explicación sobre cómo proporcionar al script información sobre la ubicación de los datos de origen, consulte Tipos de conexión y opciones para ETL en AWS Glue para Spark.
Si va a leer información de un origen que transmite flujos, debe proporcionar al trabajo información sobre el origen a través de los métodos create_data_frame_from_catalog o create_data_frame_from_options. Tenga en cuenta que estos métodos devuelven DataFrames de Apache Spark.
Nuestro código generado llama a create_dynamic_frame.from_catalog, mientras que en la documentación de referencia se alude a create_dynamic_frame_from_catalog. En última instancia, estos métodos llaman al mismo código, y se incluyen para que pueda escribir un código más limpio. Puede comprobar esto visualizando el código de origen de nuestro encapsulador de Python, disponible en aws-glue-libs
Paso 4. Transformar los datos con AWS Glue
Después de extraer los datos de origen en un proceso de ETL, debe describir cómo desea cambiar los datos. Para proporcionar esta información, debe crear un nodo Transform (Transformación) en el editor visual de AWS Glue Studio.
En este paso, debe proporcionarle al método ApplyMapping un mapa de los nombres y tipos de campos actuales y deseados para transformar DynamicFrame.
Se deben realizar las siguientes transformaciones.
-
Eliminar las cuatro claves
locationyprovince. -
Cambiar el nombre de
officerporofficer_name. -
Cambiar el tipo de
ticket_numberyset_fine_amountporfloat.
create_dynamic_frame.from_catalog proporciona un objeto DynamicFrame. DynamicFrame representa un conjunto de datos en AWS Glue. AWS Las transformaciones de Glue son operaciones que cambian DynamicFrames.
nota
¿Qué es un DynamicFrame?
Un DynamicFrame es una abstracción que permite conectar un conjunto de datos con una descripción de los nombres y tipos de entradas de los datos. En Apache Spark, existe una abstracción similar denominada DataFrame. Para ver una explicación sobre DataFrames, consulte la guía de Spark SQL
Con DynamicFrames, puede describir los esquemas de conjuntos de datos de forma dinámica. Imagine un conjunto de datos con una columna de precios, donde algunas entradas almacenan el precio como una cadena y otras lo hacen como un doble. AWS Glue calcula un esquema sobre la marcha: crea un registro autodescriptivo para cada fila.
Los campos incoherentes (como el precio) se representan explícitamente con un tipo (ChoiceType) en el esquema del marco. Los campos incoherentes se pueden eliminar con DropFields, o bien resolverlos con ResolveChoice. Estas son transformaciones que están disponibles en el DynamicFrame. Después, los datos se pueden volver a escribir en el lago de datos con writeDynamicFrame.
Puede llamar a muchas de las mismas transformaciones desde métodos de la clase DynamicFrame, lo que puede dar como resultado scripts más legibles. Para obtener más información acerca de DynamicFrame, consulte Clase DynamicFrame.
En este procedimiento, escribirá el siguiente código utilizando ApplyMapping. Este código es una parte del script de ejemplo generado.
ApplyMapping_node2 = ApplyMapping.apply( frame=S3bucket_node1, mappings=[ ("tag_number_masked", "string", "tag_number_masked", "string"), ("date_of_infraction", "string", "date_of_infraction", "string"), ("ticket_date", "string", "ticket_date", "string"), ("ticket_number", "decimal", "ticket_number", "float"), ("officer", "decimal", "officer_name", "decimal"), ("infraction_code", "decimal", "infraction_code", "decimal"), ("infraction_description", "string", "infraction_description", "string"), ("set_fine_amount", "decimal", "set_fine_amount", "float"), ("time_of_infraction", "decimal", "time_of_infraction", "decimal"), ], transformation_ctx="ApplyMapping_node2", )
Para transformar los datos con AWS Glue
-
Examine la documentación para identificar una transformación para cambiar y eliminar campos. Para obtener más información, consulte Clase de base GlueTransform. Elija la transformación
ApplyMapping. Para obtener más información acerca deApplyMapping, consulte Clase ApplyMapping. Llame aapplyen el objeto de transformaciónApplyMapping.nota
¿Qué es
ApplyMapping?ApplyMappingtoma unDynamicFramey lo transforma. Toma una lista de tuplas que representan transformaciones en los campos, una “asignación”. Los dos primeros elementos de la tupla, un nombre y un tipo de campo, se utilizan para identificar un campo en el marco. Los dos segundos parámetros también son un nombre y un tipo de campo.ApplyMapping convierte el campo de origen en el nombre y tipo del destino en un nuevo
DynamicFrame, que devuelve. Los campos que no se proporcionan se eliminan en el valor devuelto.En lugar de llamar a
apply, se puede llamar a la misma transformación con el métodoapply_mappingdeDynamicFramepara crear código más fluido y legible. Para obtener más información, consulte apply_mapping. -
Examine la documentación de
ApplyMappingpara identificar los parámetros requeridos. Consulte Clase ApplyMapping. Descubrirá que este método requiere los parámetrosframeymappings. Proporcione los parámetros necesarios aApplyMapping. -
Opcional: proporcione
transformation_ctxal método para que se admitan marcadores de trabajo. Puede obtener información sobre los marcadores de trabajo en la siguiente sección, Opcional: habilitar marcadores de trabajo.
nota
Funcionalidad de Apache Spark
Proporcionamos transformaciones para agilizar los flujos de trabajo de ETL dentro de un trabajo. Además, también puede acceder a las bibliotecas disponibles en un programa de Spark en el trabajo, creadas con fines más generales. Para utilizarlas, debe realizar conversiones entre DynamicFrame y DataFrame.
Puede crear DataFrame con toDF. A continuación, puede utilizar los métodos disponibles en el DataFrame para transformar su conjunto de datos. Para más información acerca de estos métodos, consulte DataFrame
Paso 5. Cargar datos en un destino
Después de transformar los datos, normalmente se almacenan los datos transformados en un lugar distinto al origen. Para realizar esta operación, cree un nodo target (destino) en el editor visual deAWS Glue Studio.
En este paso, se proporciona el método write_dynamic_frame.from_options los parámetros connection_type, connection_options, format y format_options para cargar datos en un bucket de destino en Amazon S3.
En el paso 1, inicializó un objeto GlueContext. En AWS Glue encontrará los métodos que se usan para configurar destinos y orígenes.
En este procedimiento, escribirá el siguiente código utilizando write_dynamic_frame.from_options. Este código es una parte del script de ejemplo generado.
S3bucket_node3 = glueContext.write_dynamic_frame.from_options( frame=ApplyMapping_node2, connection_type="s3", format="glueparquet", connection_options={"path": "s3://amzn-s3-demo-bucket", "partitionKeys": []}, format_options={"compression": "gzip"}, transformation_ctx="S3bucket_node3", )
Para cargar datos en un destino
-
Examine la documentación para buscar un método con el que cargar datos en un bucket de Amazon S3 de destino. Estos métodos están documentados en Clase GlueContext. Elija el método write_dynamic_frame_from_options. Llame a este método en
glueContext.nota
Métodos habituales para cargar datos
write_dynamic_frame.from_optionses el método más utilizado para cargar datos. Es compatible con todos los destinos disponibles en AWS Glue.Si va a escribir en un destino de JDBC definido en una conexión de AWS Glue, utilice el método write_dynamic_frame_from_jdbc_conf. AWS Las conexiones de Glue almacenan información sobre cómo conectarse a un origen de datos. Esto elimina la necesidad de proporcionar esa información en
connection_options. Sin embargo, aún es necesario utilizarconnection_optionspara proporcionardbtable.write_dynamic_frame.from_catalogno es un método habitual para cargar datos. Este método actualiza el Catálogo de datos de AWS Glue sin actualizar el conjunto de datos subyacente, y se utiliza en combinación con otros procesos que cambian el conjunto de datos subyacente. Para obtener más información, consulte Cómo actualizar el esquema y añadir nuevas particiones al Catálogo de datos mediante trabajos de ETL de AWS Glue. -
Examine la documentación de write_dynamic_frame_from_options. Este método requiere
frame,connection_type,format,connection_optionsyformat_options. Llame a este método englueContext.-
Consulte la documentación suplementaria sobre
format_optionsyformatpara identificar los parámetros que necesita. Para ver una explicación sobre los formatos de datos, consulte Opciones de formato de datos para las entradas y las salidas en AWS Glue para Spark. -
Consulte la documentación suplementaria sobre
connection_typeyconnection_optionspara identificar los parámetros que necesita. Para ver una explicación sobre las conexiones, consulte Tipos de conexión y opciones para ETL en AWS Glue para Spark. -
Proporcione los parámetros necesarios a
write_dynamic_frame.from_options. Este método tiene una configuración similar a la decreate_dynamic_frame.from_options.
-
-
Opcional proporcione
transformation_ctxawrite_dynamic_frame.from_optionspara que se admitan los marcadores de trabajo. Puede obtener información sobre los marcadores de trabajo en la siguiente sección, Opcional: habilitar marcadores de trabajo.
Paso 6. Confirmar el objeto Job
En el paso 1, inicializó un objeto Job. Es posible que necesite concluir manualmente su ciclo de vida al final del script si ciertas características opcionales lo requieren para funcionar correctamente, como cuando se utilizan marcadores de trabajos. Ese trabajo se realiza entre bastidores en AWS Glue Studio.
En este paso, llame al método commit del objeto Job.
En este procedimiento, escribirá el siguiente código. Este código es una parte del script de ejemplo generado.
job.commit()
Para confirmar el objeto Job
-
Si aún no lo ha hecho, realice los pasos opcionales indicados en las secciones anteriores para incluir
transformation_ctx. -
Llamar a
commit.
Opcional: habilitar marcadores de trabajo
En todos los pasos anteriores, se le ha indicado que configure los parámetros transformation_ctx. Esto tiene relación con una característica denominada marcadores de trabajo.
Con los marcadores de trabajos, puede ahorrar tiempo y dinero con los trabajos que se ejecutan de forma recurrente, frente a conjuntos de datos en los que el trabajo anterior puede ser fácilmente rastreado. Los marcadores de trabajo hacen un seguimiento del progreso de una transformación de AWS Glue en un conjunto de datos a partir de ejecuciones anteriores. Al hacer un seguimiento de dónde terminaron las ejecuciones anteriores, AWS Glue puede limitar su trabajo a las filas que no haya procesado antes. Para más información acerca de los marcadores de trabajo, consulte Seguimiento de los datos procesados mediante marcadores de trabajo.
Para habilitar los marcadores de trabajo, primero hay que agregar las instrucciones transformation_ctx en las funciones proporcionadas, tal como se describe en los ejemplos anteriores. El estado de los marcadores de trabajo se mantiene a través de las ejecuciones. Los parámetros transformation_ctx son claves que se usan para acceder a ese estado. Por sí solas, estas instrucciones no servirán de nada. También debe activar la característica en la configuración del trabajo.
En este procedimiento, habilita los marcadores de trabajo mediante AWS Management Console.
Para habilitar los marcadores de trabajo
-
Vaya a la sección Job details (Detalles del trabajo) del trabajo correspondiente.
-
Establezca Job bookmark (Marcador de trabajo) como Enable (Habilitar).
Paso 7. Ejecutar el código en forma de trabajo
En este paso, ejecutará el trabajo para comprobar que ha completado correctamente este tutorial. Esto se consigue simplemente haciendo clic en un botón, como en el editor visual de AWS Glue Studio.
Para ejecutar el código en forma de trabajo
-
Elija Untitled job (Trabajo sin título) en la barra de título para editar y establecer el nombre del trabajo.
-
Vaya a la pestaña Job details (Detalles del trabajo). Asigne un Rol de IAM al trabajo. Puede utilizar el que haya creado la plantilla de AWS CloudFormation en los requisitos previos del tutorial de AWS Glue Studio. Si ha completado ese tutorial, debería estar disponible como
AWS Glue StudioRole. -
Elija Save (Guardar) para guardar el script.
-
Elija Run (Ejecutar) para ejecutar el trabajo.
-
Vaya a la pestaña Ejecuciones para comprobar que el trabajo se ha completado.
-
Navegue hasta
amzn-s3-demo-bucket, el destino dewrite_dynamic_frame.from_options. Compruebe que el resultado coincide con sus expectativas.
Para obtener más información sobre la configuración y administración de trabajos, consulte Suministro de sus propios scripts personalizados.
Más información
Las bibliotecas y los métodos de Apache Spark están disponibles en los scripts de AWS Glue. Puede consultar la documentación de Spark para saber qué puede hacer con esas bibliotecas incluidas. Para obtener más información, consulte la sección de ejemplos del repositorio de origen de Spark
AWS Glue 2.0+ incluye varias bibliotecas de Python habituales de manera predeterminada. También hay mecanismos para cargar dependencias propias en un trabajo de AWS Glue en un entorno de Scala o Python. Para más información sobre las dependencias de Python, consulte Uso de bibliotecas de Python con AWS Glue.
Para más ejemplos de cómo utilizar Características de AWS Glue en Python, consulte Ejemplos de código Python en AWS Glue. Los trabajos de Scala y Python disponen de las mismas características, de modo que los ejemplos para Python pueden servir de inspiración a la hora de realizar un trabajo similar en Scala.
