Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Conceptos de AWS Glue
En el siguiente diagrama se muestra la arquitectura de un entorno de AWS Glue.
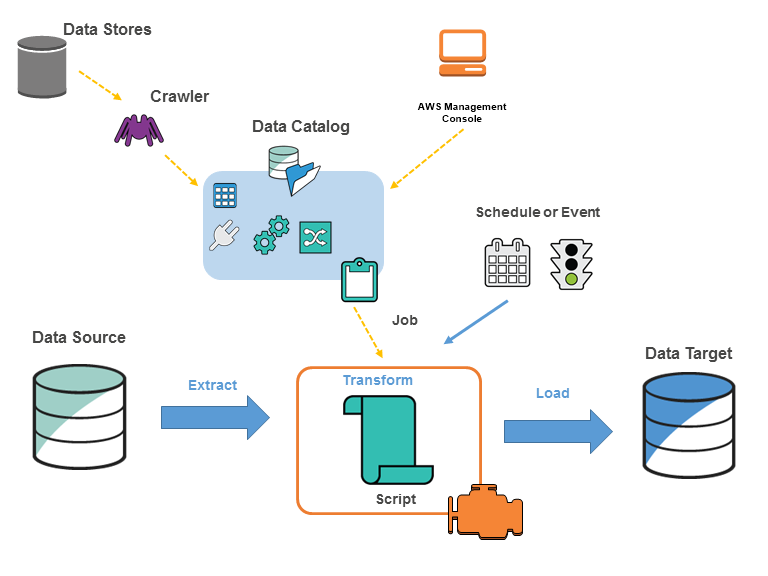
Los trabajos se definen en AWS Glue a fin de realizar el flujo de trabajo necesario para extraer, transformar y cargar datos (ETL) desde un origen de datos hasta un destino de datos. Normalmente, usted llevará a cabo las siguientes acciones:
-
Para los orígenes de almacén de datos, puede definir un rastreador para rellenar su AWS Glue Data Catalog con definiciones de tabla de metadatos. Puede dirigir su rastreador a un almacén de datos y el rastreador crea definiciones de tabla en el Data Catalog. Para orígenes de streaming, se definen manualmente tablas del Data Catalog y se especifican las propiedades del flujo de datos.
Además de las definiciones de tabla, el AWS Glue Data Catalog contiene otros metadatos necesarios para definir los trabajos de ETL. Utilizará estos metadatos al definir un flujo de trabajo para transformar sus datos.
AWS Glue puede generar un script para transformar sus datos. O bien, puede proporcionar el script en la consola o API de AWS Glue.
-
Puede ejecutar su flujo de trabajo bajo demanda o configurarlo de modo que se inicie al activarse un disparador especificado. El disparador puede corresponder a una programación basada en tiempo o a un evento.
Al ejecutarse su flujo de trabajo, un script extrae datos de su origen de datos, transforma los datos y los carga en su destino de datos. El script se ejecuta en un entorno Apache Spark en AWS Glue.
importante
Las tablas y las bases de datos de AWS Glue son objetos en el AWS Glue Data Catalog. Contienen metadatos; no datos de un almacén de datos.
|
Los datos basados en texto, como los CSV, deben estar codificados en |
Terminología de AWS Glue
AWS Glue se basa en la interacción de varios componentes para crear y gestionar su flujo de trabajo de extracción, transformación y carga (ETL).
AWS Glue Data Catalog
El almacén de metadatos persistentes en AWS Glue. Contiene definiciones de tablas, definiciones de trabajos y otra información de control para administrar su entorno de AWS Glue. Cada cuenta de AWS tiene un AWS Glue Data Catalog por región.
Clasificador
Determina el esquema de sus datos. AWS Glue proporciona clasificadores para tipos de archivos comunes, como CSV, JSON, AVRO, XML y otros. También proporciona clasificadores para sistemas de administración de bases de datos relacionales comunes mediante una conexión de JDBC. Puede escribir su propio clasificador mediante un patrón de grok o especificando una etiqueta de fila en un documento XML.
Conexión
Un objeto del Data Catalog que contiene las propiedades necesarias para conectarse a un almacén de datos determinado.
Rastreador
Un programa que se conecta a un almacén de datos (origen o destino), avanza por una lista de prioridades de clasificadores para determinar el esquema de sus datos y, a continuación, crea tablas de metadatos en el AWS Glue Data Catalog.
Base de datos
Un conjunto de definiciones de tabla del Data Catalog asociadas, organizadas en un grupo lógico.
Almacén de datos, origen de datos, destino de datos
Un almacén de datos es un repositorio para almacenar los datos de forma persistente. Entre los ejemplos se incluyen buckets de Amazon S3 y bases de datos relacionales. Un origen de datos es un almacén de datos que se utiliza como entrada para un proceso o una transformación. Un destino de datos es un almacén de datos en el que escribe un proceso o una transformación.
Punto de enlace de desarrollo
Un entorno que puede utilizar para desarrollar y probar los scripts ETL de AWS Glue.
Marco dinámico
Tabla distribuida que admite datos anidados como estructuras y matrices. Cada registro se autodescribe y está diseñado para flexibilidad de esquemas con datos semiestructurados. Cada registro contiene tanto los datos como el esquema que describe esos datos. Puede usar marcos dinámicos y Apache Spark DataFrames en sus scripts de ETL, y realizar conversiones entre ellos. Las tramas dinámicas proporcionan un conjunto de transformaciones avanzadas para la limpieza de datos y ETL.
Trabajo
La lógica empresarial que es necesaria para realizar el flujo de trabajo de ETL. Se compone de un script de transformación, orígenes de datos y destinos de datos. Las ejecuciones de trabajos pueden iniciarse a partir de disparadores programados o activados por eventos.
Panel de rendimiento del trabajo
AWS Glue proporciona un panel de ejecución integral para sus trabajos de ETL. El panel muestra información sobre las ejecuciones de trabajos desde un periodo específico.
Interfaz de cuaderno
Una experiencia de cuaderno mejorada con una configuración con un solo clic para facilitar la creación de trabajos y la exploración de datos. El bloc de notas y las conexiones se configuran automáticamente. Puede utilizar la interfaz de cuaderno basada en Jupyter Notebook para desarrollar, depurar e implementar scripts y flujos de trabajo mediante infraestructura de ETL de Apache Spark sin servidor de AWS Glue. También puede realizar consultas ad hoc, análisis de datos y visualización (por ejemplo, tablas y gráficos) en el entorno de cuaderno.
Script
Código que extrae datos de orígenes, los transforma y los carga en destinos. AWS Glue genera scripts PySpark o Scala.
Tabla
La definición de metadatos que representa sus datos. Independientemente de si sus datos están en un archivo de Amazon Simple Storage Service (Amazon S3), una tabla de Amazon Relational Database Service (Amazon RDS) u otro conjunto de datos, la tabla define el esquema de sus datos. Una tabla de AWS Glue Data Catalog está formada por los nombres de las columnas, las definiciones de tipos de datos, la información de partición y otros metadatos acerca de un conjunto de datos base. El esquema de sus datos viene representado en su definición de tabla de AWS Glue. Los datos reales permanecen en su almacén de datos original, ya sea en un archivo o en una tabla de base de datos relacional. AWS Glue cataloga sus archivos y tablas de bases de datos relacionales en el AWS Glue Data Catalog. Estos se usan como orígenes y destinos al crear un flujo de trabajo de ETL.
Transform
La lógica de código que se usa para manipular sus datos en un formato diferente.
Desencadenador
Inicia un flujo de trabajo de ETL. Los disparadores se pueden definir según un momento programado o un evento.
Editor visual de trabajos
El editor de trabajos visuales es una interfaz gráfica que facilita la creación, ejecución y supervisión de los trabajos de extracción, transformación y carga (ETL) en AWS Glue. Puede componer visualmente flujos de trabajo de transformación de datos y ejecutarlos sin problemas en el motor de ETL sin servidor basado en Apache Spark de AWS Glue e inspeccionar el esquema y los datos resultantes en cada paso del trabajo.
Entorno de trabajo
Con AWS Glue, solo paga por el tiempo que tarda en ejecutarse su trabajo de ETL. No hay que administrar recursos ni hay costos iniciales. No se le cobra por el tiempo de inicio o cierre. Se le cobra una tarifa por hora basada en el número de unidades de procesamiento de datos (o DPU) utilizadas para ejecutar el trabajo de ETL. Una sola unidad de procesamiento de datos (DPU) también se denomina empleado. AWS Glue cuenta con tres tipos de empleados para ayudarlo a seleccionar la configuración que cumpla con sus requisitos de latencia y costo del trabajo. Los procesos de trabajo pueden tener configuraciones estándar, G.1X, G.2X y G.025X.
