Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Trabajo con tablas en la consola de AWS Glue
Una tabla en el AWS Glue Data Catalog es la definición de metadatos que representa los datos en un almacén de datos. Puede crear tablas al ejecutar un rastreador, o bien puede crear una tabla manualmente en la consola de AWS Glue. En la lista Tablas en la consola de AWS Glue se muestran los valores de los metadatos de su tabla. Puede usar definiciones de tabla para especificar orígenes y destinos al crear trabajos de ETL (extracción, transformación y carga).
nota
Con los cambios recientes en la consola de administración de AWS, es posible que tenga que modificar sus roles de IAM existentes para obtener permiso de SearchTables. Para la creación de nuevos roles, se agregó de forma predeterminada el permiso de la API de SearchTables.
Para comenzar, inicie sesión en AWS Management Console y abra la consola de AWS Glue en https://console.aws.amazon.com/glue/
Adición de tablas en la consola
A fin de usar un rastreador para agregar tablas, elija Agregar tablas y Agregar tablas mediante un rastreador. A continuación, siga las instrucciones en el asistente Adición de rastreadores. Cuando se ejecuta el rastreador, se agregan las tablas al AWS Glue Data Catalog. Para obtener más información, consulte Definición de rastreadores en AWS Glue.
Si conoce los atributos necesarios para crear una definición de tabla de Amazon Simple Storage Service (Amazon S3) en su Data Catalog puede crearla con el asistente de tabla. Elija Agregar tablas, Agregar tabla manualmente y siga las instrucciones en el asistente Agregar tabla.
Al agregar una tabla manualmente a través de la consola, tenga en cuenta lo siguiente:
-
Si tiene previsto obtener acceso a la tabla desde Amazon Athena, proporcione un nombre únicamente con caracteres alfanuméricos y guiones bajos. Para obtener más información, consulte Nombres de Athena.
-
La ubicación de sus datos de origen debe ser una ruta de Amazon S3.
-
El formato de datos de los datos debe coincidir con uno de los formatos que aparecen en el asistente. La clasificación correspondiente y otras propiedades de la tabla se rellenan automáticamente en función del formato elegido. SerDe Puede definir tablas con los siguientes formatos:
- Avro
-
Formato binario JSON Apache Avro.
- CSV
-
Valores separados por caracteres. También puede especificar el delimitador de coma, barra vertical, punto y coma, tabulador o Ctrl-A.
- JSON
-
JavaScript Notación de objetos.
- XML
-
Formato de lenguaje de marcado extensible. Especifique la etiqueta XML que define una fila en los datos. Las columnas se definen dentro de etiquetas de fila.
- Parquet
-
Almacenamiento en columnas de Apache Parquet.
- ORC
-
Formato archivo Optimized Row Columnar (ORC). Formato diseñado para almacenar de forma eficiente los datos de Hive.
-
Puede definir una clave de partición para la tabla.
-
Actualmente, las tablas con particiones que crea con la consola no se pueden usar en los trabajos de ETL.
Atributos de tabla
A continuación se muestran algunos atributos importantes de su tabla:
- Name
-
El nombre se determina al crearse la tabla y no puede cambiarlo. Puede hacer referencia a un nombre de tabla en muchas operaciones de AWS Glue.
- Database
-
El objeto contenedor donde reside su tabla. Este objeto contiene una organización de sus tablas que existe en el AWS Glue Data Catalog y puede diferir de una organización en su almacén de datos. Al eliminar una tabla, todas las tablas incluidas en la base de datos también se eliminan del Data Catalog.
- Descripción
-
Descripción de la tabla. Puede escribir una descripción para ayudarle a entender el contenido de la tabla.
- Formato de tabla
-
Especifique la creación de una tabla estándar de AWS Glue o de una tabla en formato Apache Iceberg.
- Habilitar la compactación
-
Seleccione Habilitar la compactación para compactar objetos pequeños de Amazon S3 de la tabla y convertirlos en objetos más grandes.
- Rol de IAM
Para ejecutar la compactación, el servicio asume un rol de IAM en su nombre. Puede elegir un rol de IAM mediante el menú desplegable. Asegúrese de que el rol tenga los permisos necesarios para habilitar la compactación.
Para obtener más información sobre los permisos necesarios para este rol de IAM, consulte Requisitos previos para la optimización de tablas .
- Ubicación
-
El señalizador a la ubicación de los datos en un almacén de datos que representa esta definición de tabla.
- Clasificación
-
Un valor de categorización proporcionado cuando se creó la tabla. Normalmente, este se escribe al ejecutarse un rastreador y especifica el formato de los datos de origen.
- Última actualización
-
La hora y la fecha (UTC) en que se actualizó esta tabla en el Data Catalog.
- Fecha agregada
-
La hora y la fecha (UTC) en que se agregó esta tabla al Data Catalog.
- Obsoleto
-
Si AWS Glue descubre que una tabla en el Data Catalog ya no existe en su almacén de datos original, marca la tabla como obsoleta en el catálogo de datos. Si ejecuta un flujo de trabajo que hace referencia a una tabla obsoleta, podría producirse un error en el flujo de trabajo. Edite trabajos que hagan referencia a tablas obsoletas para quitarlas como orígenes y destinos. Recomendamos que elimine las tablas obsoletas cuando ya no sean necesarias.
- Connection
-
Si AWS Glue requiere una conexión a su almacén de datos, el nombre de la conexión se asocia a la tabla.
Visualización y edición de los detalles de la tabla
Para ver los detalles de una tabla existente, elija el nombre de tabla de la lista y, a continuación, elija Acción, Ver detalles.
Entre los detalles de la tabla se incluyen propiedades de su tabla y su esquema. Esta vista muestra el esquema de la tabla, incluidos los nombres de columna en el orden definido para la tabla, los tipos de datos y las columnas con clave para las particiones. Si una columna es un tipo complejo, puede elegir Ver propiedades para mostrar detalles de la estructura de ese campo, como se muestra en el siguiente ejemplo:
{ "StorageDescriptor": { "cols": { "FieldSchema": [ { "name": "primary-1", "type": "CHAR", "comment": "" }, { "name": "second ", "type": "STRING", "comment": "" } ] }, "location": "s3://aws-logs-111122223333-us-east-1", "inputFormat": "", "outputFormat": "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat", "compressed": "false", "numBuckets": "0", "SerDeInfo": { "name": "", "serializationLib": "org.apache.hadoop.hive.serde2.OpenCSVSerde", "parameters": { "separatorChar": "|" } }, "bucketCols": [], "sortCols": [], "parameters": {}, "SkewedInfo": {}, "storedAsSubDirectories": "false" }, "parameters": { "classification": "csv" } }
Para obtener más información acerca de las propiedades de una tabla, como StorageDescriptor, consulte Estructura StorageDescriptor.
Para cambiar el esquema de una tabla, elija Editar esquema para agregar y quitar columnas, cambiar nombres de columna y cambiar tipos de datos.
Para comparar diferentes versiones de una tabla, incluido su esquema, elija Comparar versiones para ver una side-by-side comparación de las dos versiones del esquema de una tabla. Para obtener más información, consulte Comparación de las versiones del esquema de la tabla .
Para mostrar los archivos que componen una partición de Amazon S3, elija Ver partición. Para las tablas de Amazon S3, la columna Clave muestra las claves de partición que se usan para particionar la tabla en el almacén de datos de origen. La creación de particiones es una forma de dividir una tabla en partes relacionadas según los valores de una columna de clave, tales como fecha, ubicación o departamento. Para obtener más información acerca de las particiones, busque en Internet información acerca de la "creación de particiones Hive".
nota
Para obtener step-by-step instrucciones sobre cómo ver los detalles de una tabla, consulta el tutorial Explore la tabla en la consola.
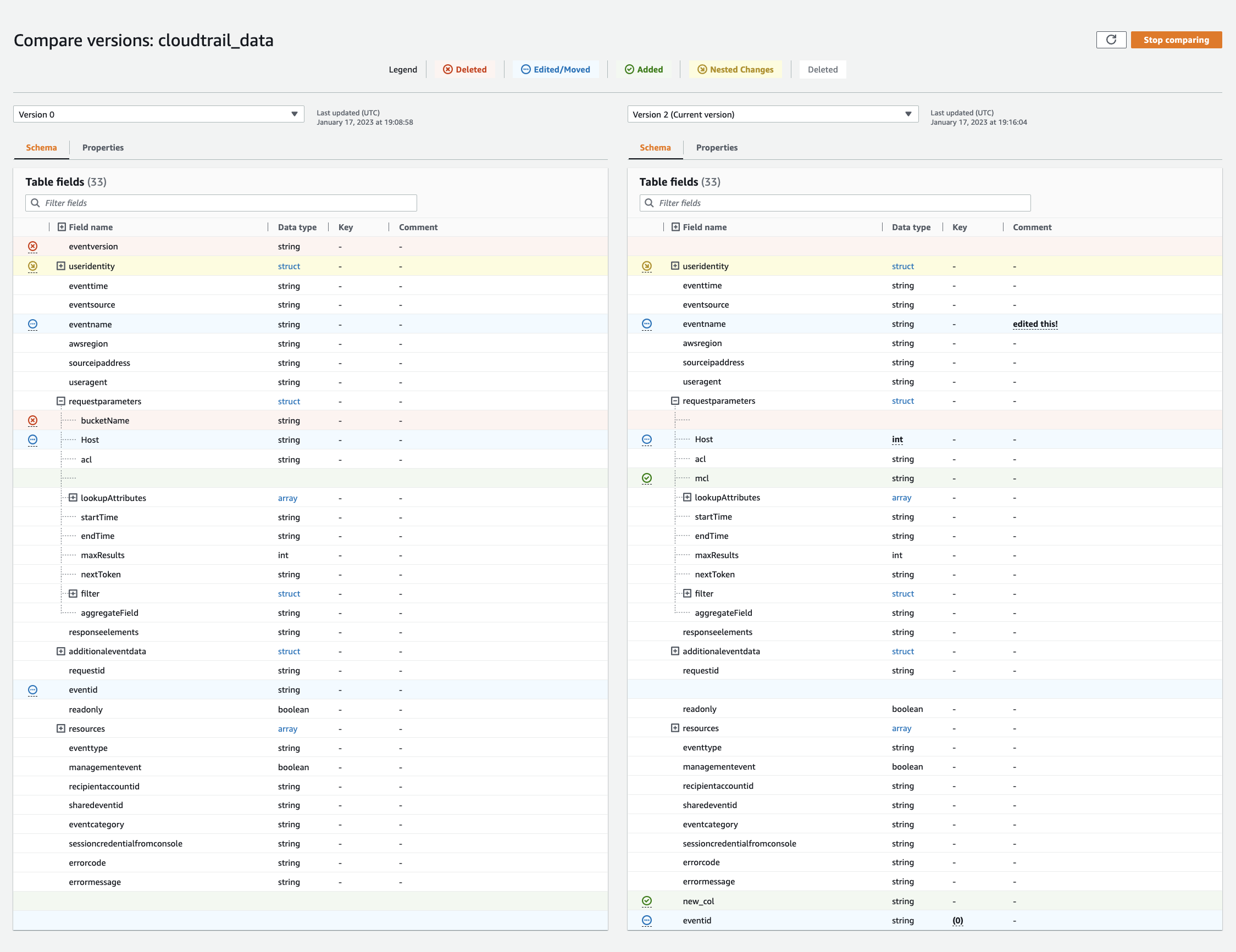
Comparación de las versiones del esquema de la tabla
Al comparar dos versiones de esquemas de tablas, puede comparar los cambios en las filas anidadas expandiendo y contrayendo las filas anidadas, comparar los esquemas de dos versiones side-by-side y ver las propiedades de la tabla. side-by-side
Para comparar las versiones
-
En la consola de AWS Glue, seleccione Tablas, Acciones y, a continuación, elija Comparar versiones.
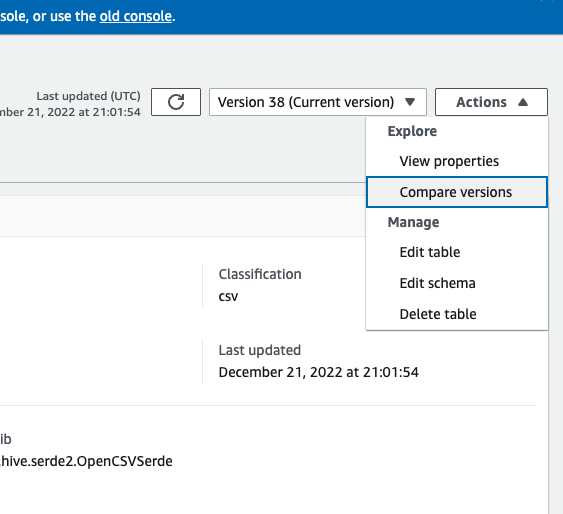
-
Elija una versión para comparar mediante el menú desplegable de versiones. Cuando compare esquemas, la pestaña Esquema aparece resaltada en naranja.
-
Cuando compare tablas entre dos versiones, los esquemas de las tablas se muestran en la parte izquierda y derecha de la pantalla. Esto le permite determinar los cambios visualmente comparando el nombre de la columna, el tipo de datos, la clave y los campos de comentarios. side-by-side Cuando se produce un cambio, aparece un icono de color que muestra el tipo de cambio realizado.
-
Eliminada: se muestra un icono rojo que indica dónde se quitó la columna de una versión anterior del esquema de la tabla.
-
Editada o movida: se muestra un icono azul que indica dónde se modificó o movió la columna en una versión más reciente del esquema de la tabla.
-
Agregado: se muestra un icono verde que indica dónde se agregó una columna a una versión más reciente del esquema de la tabla.
-
Cambios anidados: se muestra un icono amarillo que indica dónde contiene cambios la columna anidada. Elija la columna para expandirla y ver las columnas que se eliminaron, editaron, movieron o agregaron.
-
-
Utilice la barra de búsqueda de campos filtrados para mostrar los campos en función de los caracteres que introduzca aquí. Si introduce un nombre de columna en cualquier versión de la tabla, los campos filtrados se muestran en ambas versiones de la tabla para mostrarle dónde se produjeron los cambios.
-
Para comparar propiedades, elija la pestaña de Propiedades.
-
Para detener la comparación de versiones, elija Detener comparación para volver a la lista de tablas.
Optimización de las tablas de Iceberg
Los lagos de datos de Amazon S3 que utilizan formatos de tablas abiertas, como Apache Iceberg, almacenan los datos como objetos de Amazon S3. Tener miles de objetos pequeños de Amazon S3 en una tabla de lago de datos aumenta la sobrecarga de metadatos en las tablas Iceberg y afecta al rendimiento de lectura. Para mejorar el rendimiento de lectura de los servicios de análisis de AWS, como Amazon Athena y Amazon EMR, y los trabajos de AWS Glue ETL, AWS Glue Data Catalog proporciona una compactación gestionada (un proceso que compacta objetos pequeños de Amazon S3 para convertirlos en objetos más grandes) para las tablas Iceberg del catálogo de datos. Puede usar la consola de AWS Glue, la consola de Lake Formation, AWS CLI, o la API de AWS para habilitar o deshabilitar la compactación de las tablas Iceberg individuales que se encuentran en el catálogo de datos.
El optimizador de tablas supervisa constantemente las particiones de las tablas e inicia el proceso de compactación cuando se supera el umbral de cantidad y tamaño de los archivos. En el catálogo de datos, el valor límite predeterminado para iniciar la compactación se establece en 384 MB, mientras que en la biblioteca Iceberg el umbral de compactación es aproximadamente el 75 % del tamaño del archivo objetivo. El catálogo de datos efectúa la compactación sin interferir con las consultas simultáneas. El catálogo de datos admite la compactación de datos solo para tablas en formato Parquet.
Temas
Requisitos previos para la optimización de tablas
El optimizador de tablas asume los permisos del rol de AWS Identity and Access Management (IAM) que especifica al habilitar la compactación de una tabla. El rol de IAM debe tener los permisos para leer los datos y actualizar los metadatos en el catálogo de datos. Cree un rol de IAM y adjunte las siguientes políticas integradas:
-
Agregue la siguiente política en línea que conceda a Amazon S3 permisos de lectura y escritura en la ubicación para los datos que no estén registrados en Lake Formation. Esta política también incluye permisos para actualizar la tabla en el catálogo de datos y permitir que AWS Glue agregue registros en los registros Amazon CloudWatch y publicar métricas. Para los datos de origen en Amazon S3 que no estén registrados en Lake Formation, el acceso se determina mediante las políticas de permisos de IAM para Amazon S3 y acciones de AWS Glue.
En las siguientes políticas en línea, sustituya
bucket-namepor el nombre de su bucket de Amazon S3,aws-account-idyregionpor un número de cuenta y región del catálogo de datos de AWS válidos,database_namepor el nombre de su base de datos ytable_namepor el nombre de la tabla.{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject", "s3:DeleteObject" ], "Resource": [ "arn:aws:s3:::<bucket-name>/*" ] }, { "Effect": "Allow", "Action": [ "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::<bucket-name>" ] }, { "Effect": "Allow", "Action": [ "glue:UpdateTable", "glue:GetTable" ], "Resource": [ "arn:aws:glue:<region>:<aws-account-id>:table/<database-name>/<table-name>", "arn:aws:glue:<region>:<aws-account-id>:database/<database-name>", "arn:aws:glue:<region>:<aws-account-id>:catalog" ] }, { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:<region>:<aws-account-id>:log-group:/aws-glue/iceberg-compaction/logs:*" } ] } -
Utilice la siguiente política para habilitar la compactación de los datos registrados en Lake Formation.
Para obtener más información sobre cómo registrar un bucket de Amazon S3 en Lake Formation, consulte Requisitos para los roles utilizados en el registro de ubicaciones.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "lakeformation:GetDataAccess" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "glue:UpdateTable", "glue:GetTable" ], "Resource": [ "arn:aws:glue:<region>:<aws-account-id>:table/<databaseName>/<tableName>", "arn:aws:glue:<region>:<aws-account-id>:database/<database-name>", "arn:aws:glue:<region>:<aws-account-id>:catalog" ] }, { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:<region>:<aws-account-id>:log-group:/aws-glue/iceberg-compaction/logs:*" } ] }Si el rol de compactación no tiene permisos de
IAM_ALLOWED_PRINCIPALSgrupo otorgados en la tabla, necesitará los permisos ALTER, DESCRIBE, INSERT y DELETE de Lake Formation en la tabla. -
(Opcional) Para compactar tablas Iceberg con datos de buckets de Amazon S3 cifrados mediante cifrado del lado del servidor, el rol de compactación requiere permisos para descifrar los objetos de Amazon S3 y generar una nueva clave de datos para escribir los objetos en los buckets cifrados. Agregue la siguiente política a la clave de AWS KMS deseada. Solo admitimos el cifrado a nivel de bucket.
{ "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::<aws-account-id>:role/<compaction-role-name>" }, "Action": [ "kms:Decrypt", "kms:GenerateDataKey" ], "Resource": "*" } -
(Opcional) Para la ubicación de datos registrada en Lake Formation, el rol utilizado para registrar la ubicación requiere permisos para descifrar los objetos de Amazon S3 y generar una nueva clave de datos para escribir los objetos en los buckets cifrados. Para obtener más información, consulte Registro de una ubicación de Amazon S3.
-
(Opcional) Si la clave AWS KMS está almacenada en una cuenta AWS diferente, debe incluir los siguientes permisos para la función de compactación.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "kms:Decrypt", "kms:GenerateDataKey" ], "Resource": ["arn:aws:kms:<REGION>:<KEY_OWNER_ACCOUNT_ID>:key/<KEY_ID>"] } ] } -
El rol que utilice para ejecutar la compactación debe tener el permiso
iam:PassRolecorrespondiente al rol.{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "iam:PassRole" ], "Resource": [ "arn:aws:iam::<account-id>:role/<compaction-role-name>" ] } ] } -
Agregue la siguiente política de confianza al rol para que el servicio AWS Glue asuma el rol de IAM para ejecutar el proceso de compactación.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Allow", "Principal": { "Service": "glue.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }
Habilitar la compactación
Puede usar la consola de AWS Glue, la consola de Lake Formation, AWS CLI, o la APIde AWS para habilitar la compactación de las tablas de Apache Iceberg en el catálogo de datos. Para las tablas nuevas, puede elegir Apache Iceberg como formato de tabla y habilitar la compactación al crear la tabla. La compactación está deshabilitada de forma predeterminada para las tablas nuevas.
Después de activar la compactación, la pestaña de Optimización de la tabla muestra los siguientes detalles de compactación (después de aproximadamente 15 a 20 minutos):
-
Hora de inicio: hora a la que se inició el proceso de compactación en Lake Formation. El valor es una marca en la hora UTC.
-
Hora de finalización: hora en la que finalizó el proceso de compactación en Lake Formation. El valor es una marca en la hora UTC.
-
Estado: el estado del ciclo de compactación. Los valores indican éxito o fracaso.
-
Archivos compactados: número total de archivos compactados.
-
Bytes compactados: número total de bytes compactados.
Deshabilitación de la compactación
Puede deshabilitar la compactación automática de una tabla Apache Iceberg concreta mediante la consola AWS Glue o AWS CLI.
Consultar los detalles de compactación
Puede ver el estado de compactación de Apache Iceberg mediante la consola de AWS Glue, AWS CLI, o mediante las operaciones de la API de AWS.
Visualización de métricas de Amazon CloudWatch
Tras ejecutar la compactación correctamente, el servicio crea métricas Amazon CloudWatch sobre el rendimiento del trabajo de compactación. Puedes ir a la CloudWatchconsola y elegir Métricas, Todas las métricas. Puede filtrar las métricas por el espacio de nombres específico (por ejemplo, AWS Glue), el nombre de la tabla o el nombre de la base de datos.
Para obtener más información, consulte Ver métricas disponibles en la Guía del usuario de Amazon CloudWatch.
-
Número de bytes compactados
-
Número de archivos compactados
-
Número de DPU asignado a los trabajos
-
Duración del trabajo (horas)
Eliminar un optimizador
Puede eliminar un optimizador y los metadatos asociados a la tabla mediante AWS CLI o una operación de API de AWS.
Ejecute el siguiente comando AWS CLI para eliminar el historial de compactación de una tabla.
aws glue delete-table-optimizer \ --catalog-id123456789012\ --database-nameiceberg_db\ --table-nameiceberg_table\ --type compaction
Utilice la operación DeleteTableOptimizer para eliminar un optimizador de una tabla.
Consideraciones y limitaciones
La compactación de datos admite:
Tipos de datos: booleano, entero, largo, flotante, doble, cadena, decimal, fecha, hora, marca de tiempo, cadena, UUID, binario
Compresión: zstd, gzip, snappy, sin comprimir
-
Cifrado: la compactación de datos solo admite el cifrado Amazon S3 (SSE-S3) y el cifrado KMS del lado del servidor (SSE-KMS).
-
Compactación de bin pack
Evolución del esquema
Tablas con el tamaño de archivo objetivo (escriba. target-file-size-bytes propiedad en configuración iceberg) dentro del rango inclusivo de 128 MB a 512 MB.
Regiones
Asia-Pacífico (Tokio)
Asia-Pacífico (Seúl)
Asia-Pacífico (Bombay)
Europa (Irlanda)
Europa (Fráncfort)
Este de EE. UU. (Norte de Virginia)
Este de EE. UU. (Ohio)
Oeste de EE.UU. (Norte de California)
-
Puede ejecutar la compactación desde la cuenta en la que reside el catálogo de datos cuando el bucket de Amazon S3 que almacena los datos subyacentes esté en otra cuenta. Para ello, el rol de compactación requiere acceso al bucket de Amazon S3.
La compactación de datos actualmente no admite:
Tipos de datos: fijos
Compresión: brotli, lz4
Compactación de archivos a medida que evoluciona la especificación de la partición.
Clasificación regular o clasificación en orden Z
Combinar o eliminar archivos: el proceso de compactación omite los archivos de datos que tienen archivos de eliminación asociados.
-
Compactación en tablas con varias cuentas: no se puede ejecutar la compactación en tablas con varias cuentas.
-
Compactación en tablas en varias regiones: no se puede ejecutar la compactación en tablas en varias regiones.
Habilitar la compactación en los enlaces de recursos
Puntos de conexión para los buckets de Amazon S3
