Creación de trabajos con conectores personalizados
Puede utilizar conectores y conexiones tanto para nodos de origen de datos como para nodos de destino de datos en AWS Glue Studio.
Creación de trabajos que utilicen un conector para el origen de datos
Al crear un nuevo trabajo, puede elegir un conector para el origen de datos y los destinos de datos.
Para crear un trabajo que utilice conectores para el origen de datos o el destino de datos
Inicie sesión en la AWS Management Console y abra la consola de AWS Glue Studio en https://console.aws.amazon.com/gluestudio/.
-
En la página Connectors (Conectores), en la lista de recursos Your connections (Sus conexiones), elija la conexión que desea usar en su trabajo y, a continuación, elija Create job (Crear el trabajo).
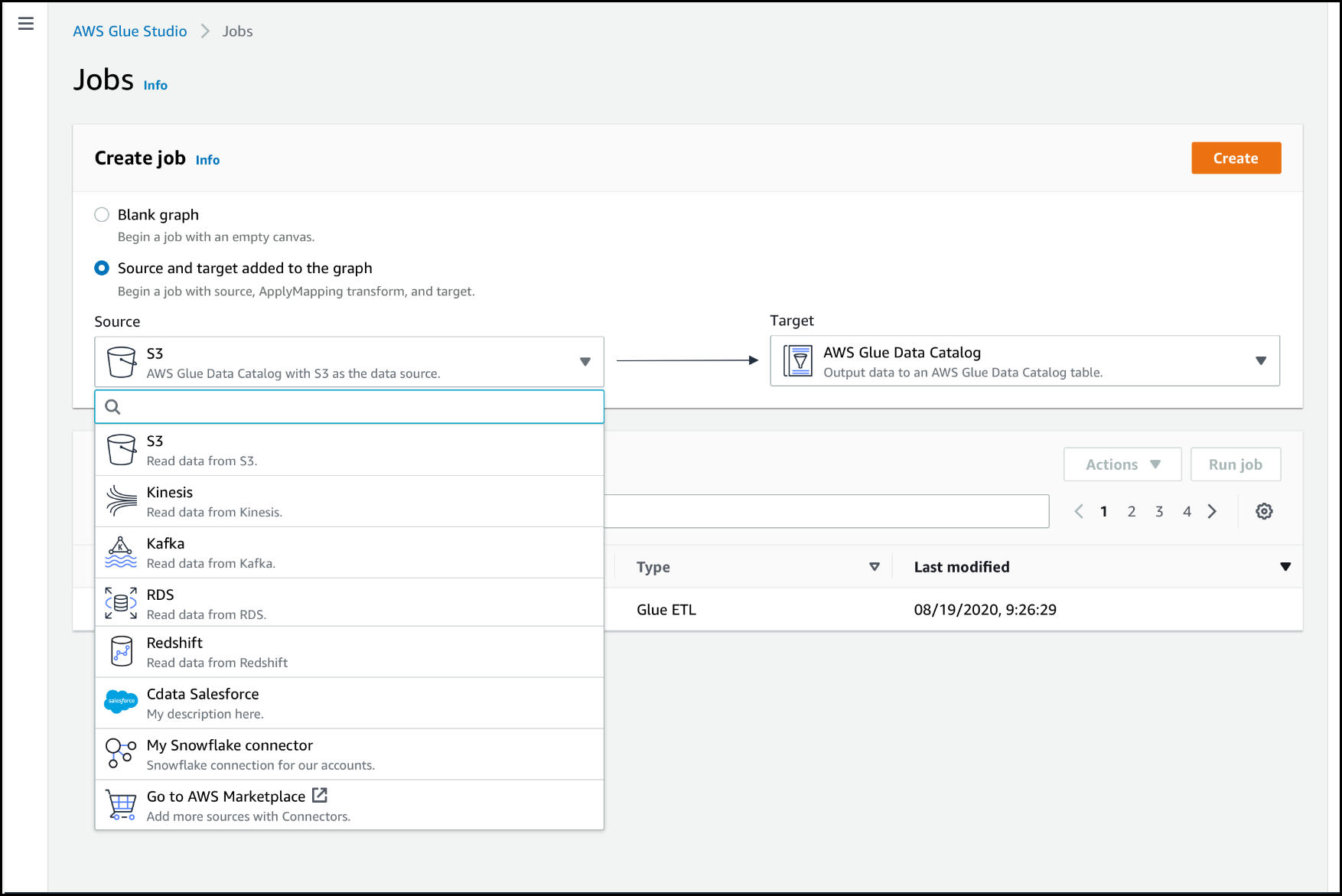
Como alternativa, en la página Jobs (Trabajos) de AWS Glue Studio, en Create job (Crear el trabajo), elija Source and target added to the graph (Origen y destino agregados al gráfico). En la lista desplegable Source (Origen), elija el conector personalizado que desea usar en el trabajo. También puede elegir un conector para Target (Destino).
-
Elija Create (Crear) para abrir el editor visual de trabajos.
-
Configure el nodo de origen de datos, como se describe en Configuración de las propiedades de origen para los nodos que utilizan conectores.
-
Continúe creando su trabajo de ETL mediante el agregado de transformaciones, almacenes de datos adicionales y destinos de datos, como se describe en Inicio de trabajos de ETL visuales en AWS Glue Studio.
-
Personalice el entorno de ejecución del trabajo mediante la configuración de las propiedades del trabajo, como se describe en Modificar las propiedades del trabajo.
-
Guarde y ejecute el trabajo.
Configuración de las propiedades de origen para los nodos que utilizan conectores
Después de crear un trabajo que utiliza un conector para el origen de datos, el editor visual de trabajos muestra un gráfico de trabajo con un nodo de origen de datos configurado para el conector. Debe configurar las propiedades del origen de datos para ese nodo.
Para configurar las propiedades de un nodo de origen de datos que utiliza un conector
-
Elija el nodo de origen de datos del conector en el gráfico de trabajo o agregue un nodo nuevo y elija el conector para el Node type (Tipo de nodo). A continuación, en el lado derecho, en el panel de detalles del nodo, seleccione la pestaña Data source properties (Propiedades de origen de datos), si aún no está seleccionada.
-
En la pestaña Data source properties (Propiedades de origen de datos), elija la conexión que desea utilizar para este trabajo.
Ingrese la información adicional necesaria para cada tipo de conexión:
- JDBC
-
-
Data source input type (Tipo de entrada de origen de datos): elija proporcionar un nombre de tabla o una consulta SQL como origen de datos. En función de su elección, deberá proporcionar la siguiente información adicional:
-
Table name (Nombre de la tabla): el nombre de la tabla en el origen de datos. Si el origen de datos no utiliza el término tabla, proporcione el nombre de una estructura de datos adecuada, como se indica en la información de uso del conector personalizado (que está disponible en AWS Marketplace).
-
Filter predicate (Filtrar predicado): una cláusula de condición que se usa al leer el origen de datos, similar a WHERE, utilizada para recuperar un subconjunto de los datos.
-
Query code (Código de consulta): ingrese una consulta SQL que se utilizará para recuperar un conjunto de datos específico del origen de datos. Un ejemplo de una consulta SQL básica es:
SELECT column_list FROM
table_name WHERE where_clause
-
Schema (Esquema): ya que AWS Glue Studio utiliza la información almacenada en la conexión para tener acceso al origen de datos en lugar de recuperar información de los metadatos de una tabla del Catálogo de datos, debe proporcionar los metadatos del esquema para el origen de datos. Elija Add schema (Agregar esquema) para abrir el editor de esquemas.
Para obtener instrucciones sobre cómo utilizar el editor de esquemas, consulte Edición de esquema para un nodo de transformación personalizado.
-
Partition column (Columna de partición): (opcional) puede optar por particionar las lecturas de datos al proporcionar valores para Partition column (Columna de partición), Lower bound (Límite inferior),Upper bound (Límite superior) y Number of partitions (Número de particiones).
Los valores lowerBound y upperBound se utilizan para decidir el intervalo de partición, no para filtrar las filas de la tabla. Todas las filas de la tabla se particionan y se devuelven.
La partición de columnas agrega una condición de partición adicional a la consulta utilizada para leer los datos. Cuando se utiliza una consulta en lugar de un nombre de tabla, debe validar que la consulta funciona con la condición de partición especificada. Por ejemplo:
-
Si el formato de consulta es "SELECT col1 FROM table1", pruebe la consulta al agregar una cláusula WHERE al final de la consulta que utiliza la columna de partición.
-
Si su formato de consulta es "SELECT col1 FROM table1 WHERE
col2=val", pruebe la consulta al ampliar la cláusula WHERE con AND y una expresión que utiliza la columna de partición.
-
Data type casting (Conversión de tipo de datos): si el origen de datos utiliza tipos de datos que no están disponibles en JDBC, utilice esta sección para especificar cómo se debe convertir un tipo de datos del origen de datos en tipos de datos JDBC. Puede especificar hasta 50 conversiones de tipos de datos diferentes. Todas las columnas del origen de datos que utilizan el mismo tipo de datos se convierten de la misma manera.
Por ejemplo, si tiene tres columnas en el origen de datos que utilizan el tipo de datos Float e indica que el tipo de datos Float se debe convertir al tipo de datos String de JDBC, las tres columnas que utilizan el tipo de datos Float se convierten a los tipos de datos String.
-
Job bookmark keys (Claves de marcadores de trabajo): los marcadores de trabajo ayudan a AWS Glue a mantener la información de estado y evitar el reprocesamiento de los datos antiguos. Especifique una o más columnas como claves favoritas. AWS Glue Studio utiliza claves favoritas para realizar un seguimiento de los datos que ya se han procesado durante una ejecución anterior del trabajo de ETL. Cualquier columna que utilice para claves de marcadores personalizadas debe ser estrictamente monotónica en aumento o disminución, pero se permiten espacios.
Si ingresa varias claves de marcadores, se combinan para formar una única clave compuesta. Una clave de marcador de trabajo compuesta no debe contener columnas duplicadas. Si no especifica ninguna clave favorita, AWS Glue Studio utiliza la clave principal como clave favorita de forma predeterminada, siempre que aumente o disminuya en forma secuencial (sin brechas). Si la tabla no tiene una clave principal, pero la propiedad del marcador de trabajo está habilitada, debe proporcionar claves de marcadores de trabajo personalizadas. De lo contrario, la búsqueda de claves principales que se utilizarán como valor predeterminado fallará y la ejecución del trabajo fallará.
Job bookmark keys sorting order (Orden de clasificación de claves de marcadores de trabajo): elija si los valores clave están en aumento o disminución secuencial.
- Spark
-
-
Schema (Esquema): ya que AWS Glue Studio utiliza la información almacenada en la conexión a fin de tener acceso al origen de datos en lugar de recuperar información de los metadatos de una tabla del Catálogo de datos, debe proporcionar los metadatos del esquema para el origen de datos. Elija Add schema (Agregar esquema) para abrir el editor de esquemas.
Para obtener instrucciones sobre cómo utilizar el editor de esquemas, consulte Edición de esquema para un nodo de transformación personalizado.
-
Connection options (Opciones de conexión): ingrese pares clave-valor adicionales según sea necesario para proporcionar información u opciones de conexión adicionales. Por ejemplo, puede ingresar un nombre de base de datos, un nombre de tabla, un nombre de usuario y una contraseña.
Por ejemplo, para OpenSearch, ingrese los siguientes pares clave-valor, como se describe en Tutorial: uso de AWS Glue Connector for Elasticsearch :
-
es.net.http.auth.user :
username
-
es.net.http.auth.pass :
password
-
es.nodes : https://<Elasticsearch
endpoint>
-
es.port : 443
-
path: <Elasticsearch
resource>
-
es.nodes.wan.only : true
Para obtener un ejemplo de las opciones de conexión mínimas que se van a utilizar, consulte el script de prueba de ejemplo MinimalSparkConnectorTest.scala en GitHub, que muestra las opciones de conexión que normalmente proporcionaría en una conexión.
- Athena
-
-
Table name (Nombre de la tabla): el nombre de la tabla en el origen de datos. Si está utilizando un conector para leer los registros de Athena-CloudWatch, debe ingresar all_log_streams del nombre de la tabla.
-
Athena schema name (Nombre del esquema Athena): elija el esquema de su origen de datos Athena que corresponde a la base de datos que contiene la tabla. Si está utilizando un conector para leer los registros de Athena-CloudWatch, debe ingresar un nombre de esquema similar a /aws/glue/name.
-
Schema (Esquema): ya que AWS Glue Studio utiliza la información almacenada en la conexión a fin de tener acceso al origen de datos en lugar de recuperar información de los metadatos de una tabla del Catálogo de datos, debe proporcionar los metadatos del esquema para el origen de datos. Elija Add schema (Agregar esquema) para abrir el editor de esquemas.
Para obtener instrucciones sobre cómo utilizar el editor de esquemas, consulte Edición de esquema para un nodo de transformación personalizado.
-
Additional connection options (Opciones adicionales de conexión): ingrese pares clave-valor adicionales según sea necesario para proporcionar información u opciones de conexión adicionales.
Para ver un ejemplo, consulte el archivo README.md en https://github.com/aws-samples/aws-glue-samples/tree/master/GlueCustomConnectors/development/Athena. En los pasos de este documento, el código de muestra muestra las opciones de conexión mínimas necesarias, que son tableName, schemaName y className. En el ejemplo del código se especifican estas opciones como parte de la variable optionsMap, pero puede especificarlos para su conexión y luego usar la conexión.
-
(Opcional) después de proporcionar la información necesaria, puede ver el esquema de datos resultante para su origen de datos al seleccionar la pestaña Output schema (Esquema de salida) en el panel de detalles del nodo. Los nodos secundarios que agregue al gráfico de trabajo utilizan el esquema que se muestra en esta pestaña.
-
(Opcional) después de configurar las propiedades del nodo y del origen de datos, puede ver la previsualización del conjunto de datos para su origen de datos al seleccionar la pestaña Data preview (Previsualización de datos) en el panel de detalles del nodo. La primera vez que elija esta pestaña para cualquier nodo de trabajo, se le pedirá que proporcione un rol de IAM para acceder a los datos. Hay un costo asociado con el uso de este recurso y la facturación comienza tan pronto como proporcione un rol de IAM.
Configuración de las propiedades de destino para los nodos que utilizan conectores
Si utiliza un conector para el tipo de destino de datos, debe configurar las propiedades del nodo de destino de datos.
Para configurar las propiedades de un nodo de destino de datos que utiliza un conector
-
Elija el nodo de destino de datos para el conector en el gráfico de trabajo. A continuación, en el lado derecho, en el panel de detalles del nodo, seleccione la pestaña Data target properties (Propiedades de destino de datos), si aún no está seleccionada.
-
En la pestaña Data target properties (Propiedades de Destino de datos), elija la conexión que se utilizará para escribir en el destino.
Ingrese la información adicional necesaria para cada tipo de conexión:
- JDBC
-
-
Connection (Conexión): elija la conexión que desea utilizar con el conector. Para obtener información acerca de cómo crear una conexión, consulte Creación de conexiones para conectores.
-
Table name (Nombre de la tabla): el nombre de la tabla en el destino de datos. Si el destino de datos no utiliza el término tabla, proporcione el nombre de una estructura de datos adecuada, como se indica en la información de uso del conector personalizado (que está disponible en AWS Marketplace).
-
Batch size (Tamaño del lote) (opcional): ingrese el número de filas o registros que desea insertar en la tabla de destino en una sola operación. El valor predeterminado es 1000 filas.
- Spark
-
-
Connection (Conexión): elija la conexión que desea utilizar con el conector. Si no creó una conexión anteriormente, elija Create connection (Crear conexión) para crear una. Para obtener información acerca de cómo crear una conexión, consulte Creación de conexiones para conectores.
-
Connection options (Opciones de conexión): ingrese pares clave-valor adicionales según sea necesario para proporcionar información u opciones de conexión adicionales. Puede ingresar un nombre de base de datos, un nombre de tabla, un nombre de usuario y una contraseña.
Por ejemplo, para OpenSearch, ingrese los siguientes pares clave-valor, como se describe en Tutorial: uso de AWS Glue Connector for Elasticsearch :
-
es.net.http.auth.user :
username
-
es.net.http.auth.pass :
password
-
es.nodes : https://<Elasticsearch
endpoint>
-
es.port : 443
-
path: <Elasticsearch
resource>
-
es.nodes.wan.only : true
Para obtener un ejemplo de las opciones de conexión mínimas que se van a utilizar, consulte el script de prueba de ejemplo MinimalSparkConnectorTest.scala en GitHub, que muestra las opciones de conexión que normalmente proporcionaría en una conexión.
-
Después de proporcionar la información necesaria, puede ver el esquema de datos resultante para su origen de datos al seleccionar la pestaña Output schema (Esquema de salida) en el panel de detalles del nodo.
![La imagen es una captura de pantalla del editor visual de trabajos de AWS Glue Studio, con un nodo de origen de datos seleccionado en el gráfico. Se selecciona la pestaña Data source properties (Propiedades de origen de datos) de la derecha. Los campos mostrados para las propiedades del origen de datos son Connection (Conexión) [una lista desplegable de conexiones disponibles, seguida de un botón Refresh (Actualizar) y un botón Add schema (Agregar esquema)]. Se muestra una sección de opciones de conexión adicional en su estado contraído.](images/data-source-properties-connector-screenshot2.png)
