Tutorial: creación de una transformación de machine learning con AWS Glue
Este tutorial le guiará a través de las acciones para crear y administrar una transformación de machine learning (ML) con AWS Glue. Antes de utilizar este tutorial, debe estar familiarizado con el uso de la consola de AWS Glue para añadir rastreadores y trabajos, y editar scripts. También debe estar familiarizado con la búsqueda y descarga de archivos en la consola de Amazon Simple Storage Service (Amazon S3).
En este ejemplo, se creará una transformación FindMatches para encontrar los registros coincidentes, enseñarle cómo identificar registros de coincidencia y no coincidencia, y utilizarla en un trabajo de AWS Glue. El trabajo de AWS Glue escribe un nuevo archivo de Amazon S3 con una columna adicional denominada match_id.
En este tutorial se ha utilizado un archivo denominado dblp_acm_records.csv como dato de origen. Este archivo es una versión modificada de publicaciones académicas (DBLP y ACM) disponible a partir del conjunto de datos de DBLP y ACMdblp_acm_records.csv es un archivo de valores separados por comas (CSV) en formato UTF-8 sin marca de orden de bytes (BOM).
El segundo archivo dblp_acm_labels.csv, es un archivo de etiquetado de ejemplo que contiene registros de coincidencia y no coincidencia utilizados para enseñar a la transformación como parte del tutorial.
Temas
Paso 1: Rastrear los datos de origen
En primer lugar, rastree el archivo CSV de Amazon S3 de origen para crear una tabla de metadatos correspondiente en el Data Catalog.
importante
Para dirigir el rastreador para crear una tabla únicamente para el archivo CSV, almacene los datos de origen de CSV en una carpeta de Amazon S3 diferente de los demás archivos.
Inicie sesión en la AWS Management Console y abra la consola de AWS Glue en https://console.aws.amazon.com/glue/
. -
En el panel de navegación, elija Crawlers (Rastreadores) y Add crawler (Añadir rastreador).
-
Siga el asistente para crear y ejecutar un rastreador denominado
demo-crawl-dblp-acmcon salida a la base de datosdemo-db-dblp-acm. Cuando ejecute el asistente, cree la base de datosdemo-db-dblp-acmsi no existe todavía. Elija una ruta de inclusión de Amazon S3 a los datos de ejemplo en la región de AWS actual. Por ejemplo, en el caso deus-east-1, la ruta de inclusión de Amazon S3 para el archivo de origen ess3://ml-transforms-public-datasets-us-east-1/dblp-acm/records/dblp_acm_records.csv.Si se ejecuta correctamente, el rastreador crea la tabla
dblp_acm_records_csvcon las siguientes columnas: id, title (título), authors (autores), venue (lugar), year (año) y source (origen).
Paso 2: Agregar una transformación de machine learning
A continuación, agregue una transformación de machine learning que se base en el esquema de la tabla de origen de datos creada por el rastreador denominada demo-crawl-dblp-acm.
-
En la consola de AWS Glue, en el panel de navegación, en la sección Integración de datos y ETL, seleccione Herramientas de clasificación de datos > Coincidencia de registros y, a continuación, Agregar transformación. Siga el asistente para crear una transformación
Find matchescon las siguientes propiedades.-
En Transform name (Nombre de transformación), escriba
demo-xform-dblp-acm. Este es el nombre de la transformación que se utiliza para buscar coincidencias en los datos de origen. -
En IAM role (Rol de IAM) elija un rol de IAM que tenga permiso para los datos de origen de Amazon S3, el archivo de etiquetado y las operaciones de la API de AWS Glue. Para obtener más información, consulte Creación de un rol de IAM para AWS Glue en la Guía para desarrolladores de AWS Glue.
-
En Data source (Origen de datos), elija la tabla denominada dblp_acm_records_csv en la base de datos demo-db-dblp-acm.
-
En Primary key (Clave principal), elija la columna de clave principal para la tabla, id.
-
En el asistente, elija Finish (Finalizar) y vuelva a la lista ML transforms (Transformaciones de ML).
Paso 3: Agregar una transformación de machine learning
A continuación, debe enseñar a su transformación de machine learning a usar el archivo de etiquetado de ejemplo del tutorial.
No puede utilizar una transformación de lenguaje automático en un trabajo de extracción, transformación y carga (ETL) hasta que el estado sea Ready for use (Listo para su uso). Para que la transformación esté preparada, debe enseñarle cómo identificar registros de coincidencia y no coincidencia mediante el ofrecimiento de ejemplos de registros de coincidencia y no coincidencia. Para enseñar a su transformación, puede generar un archivo de etiquetas, añadir etiquetas y, a continuación, subir un archivo de etiquetas. En este tutorial, puede utilizar el archivo de etiquetado de ejemplo denominado dblp_acm_labels.csv. Para obtener más información sobre el proceso de etiquetado, consulte Etiquetado.
-
En el panel de navegación de la consola de AWS Glue, elija Coincidencia de registros.
-
Elija la transformación
demo-xform-dblp-acmy, a continuación, elija Action (Acción) y Teach (Enseñar). Siga el asistente para enseñar a su transformaciónFind matches. En la página de propiedades de transformación, elija I have labels (Tengo etiquetas). Elija una ruta de Amazon S3 al archivo de etiquetado de ejemplo en la región de AWS actual. Por ejemplo, para
us-east-1, cargue el archivo de etiquetado proporcionado de la ruta de Amazon S3s3://ml-transforms-public-datasets-us-east-1/dblp-acm/labels/dblp_acm_labels.csvcon la opción overwrite (sobreescribir) las etiquetas existentes. El archivo de etiquetado debe estar ubicado en Amazon S3 en la misma región que la consola de AWS Glue.Al cargar un archivo de etiquetado, se inicia una tarea en AWS Glue para añadir o sobrescribir las etiquetas utilizadas para enseñar a la transformación cómo procesar el origen de datos.
En la última página del asistente, elija Finish (Finalizar), y vuelva a la lista ML transforms (Transformaciones de ML).
Paso 4: Calcular la calidad de su transformación de machine learning
A continuación, puede estimar la calidad de su transformación de machine learning. La calidad depende de la cantidad de etiquetado que acaba de realizar. Para obtener más información sobre la calidad de estimación, consulte Estimar calidad.
-
En la consola de AWS Glue, en el panel de navegación, en Integración de datos y ETL, seleccione Herramientas de clasificación de datos > Coincidencia de registros.
-
Elija la transformación
demo-xform-dblp-acmy elija la pestaña Estimate quality (Estimar calidad). Esta pestaña muestra las estimaciones de calidad actuales, si estuvieran disponibles, para la transformación. Elija Estimate quality (Estimar calidad) para iniciar una tarea para estimar la calidad de la transformación. La exactitud de la estimación de calidad se basa en el etiquetado de los datos de origen.
Diríjase a la pestaña History (Historial). En este panel, aparecen las ejecuciones de tareas para la transformación, incluida la tarea de Estimating quality (Estimación de calidad). Para obtener más información sobre la ejecución, elija Logs (Registros). Compruebe que el estado de ejecución sea Suceeded (Correcto) cuando finalice.
Paso 5: Agregar y ejecutar un trabajo con su transformación de machine learning.
En este paso, utilice la transformación de machine learning para agregar y ejecutar un trabajo en AWS Glue. Cuando la transformación demo-xform-dblp-acm esté lista para su uso, podrá utilizarla en un trabajo de ETL.
-
En el panel de navegación de la consola de AWS Glue, seleccione Jobs (Trabajos).
-
Elija Add job (Añadir trabajo) y siga los pasos en el asistente para crear un trabajo de ETL Spark con un script generado. Elija los siguientes valores de propiedad para su transformación:
-
En Name (Nombre), elija el trabajo de ejemplo en este tutorial, demo-etl-dblp-acm.
-
En IAM role (Rol de IAM), elija un rol de IAM con permiso para los datos de origen de Amazon S3, el archivo de etiquetado y las operaciones de la API de AWS Glue. Para obtener más información, consulte Creación de un rol de IAM para AWS Glue en la Guía para desarrolladores de AWS Glue.
-
En ETL language (Lenguaje de ETL), elija Scala. Este es el lenguaje de programación en el script de ETL.
-
En Script file name (Nombre de archivo de script), elija demo-etl-dblp-acm. Este es el nombre de archivo del script de Scala (mismo nombre de archivo).
-
En Data source (Origen de datos), elija dblp_acm_records_csv. El origen de datos que elija debe coincidir con el esquema de origen de datos de transformación de machine learning.
-
En Transform type (Tipo de transformación), elija Find matching records (Buscar registros de coincidencia) para crear un trabajo mediante una transformación de machine learning.
-
Borre Remove duplicate records (Eliminar registros duplicados). No quiere eliminar registros duplicados porque los registros de salida escritos disponen de un campo
match_idadicional añadido. -
En Transform (Transformación), elija demo-xform-dblp-acm, la transformación de machine learning utilizada por el trabajo.
-
En Create tables in your data target (Crear tablas en su destino de datos), elija crear tablas con las siguientes propiedades:
-
Data store type (Tipo de almacén de datos):
Amazon S3 -
Format (Formato):
CSV -
Compression type (Tipo de compresión):
None -
Target path (Ruta de destino): la ruta de Amazon S3 donde se escribe la salida del trabajo (en la región de AWS de la consola actual)
-
-
-
Elija Save job and edit script (Guardar trabajo y editar script) para mostrar la página del editor de scripts.
-
Edite el script para añadir una instrucción para que la salida del trabajo en Target path (Ruta de destino) se sobrescriba en un archivo de partición único. Añada esta instrucción inmediatamente después de la instrucción que ejecuta la transformación
FindMatches. La instrucción es similar a la siguiente.val single_partition = findmatches1.repartition(1)Debe modificar la instrucción
.writeDynamicFrame(findmatches1)para escribir la salida como.writeDynamicFrame(single_partion). -
Después de editar el script, elija Save (Guardar). El script modificado tiene un aspecto similar al siguiente código, pero se personaliza para su entorno.
import com.amazonaws.services.glue.GlueContext import com.amazonaws.services.glue.errors.CallSite import com.amazonaws.services.glue.ml.FindMatches import com.amazonaws.services.glue.util.GlueArgParser import com.amazonaws.services.glue.util.Job import com.amazonaws.services.glue.util.JsonOptions import org.apache.spark.SparkContext import scala.collection.JavaConverters._ object GlueApp { def main(sysArgs: Array[String]) { val spark: SparkContext = new SparkContext() val glueContext: GlueContext = new GlueContext(spark) // @params: [JOB_NAME] val args = GlueArgParser.getResolvedOptions(sysArgs, Seq("JOB_NAME").toArray) Job.init(args("JOB_NAME"), glueContext, args.asJava) // @type: DataSource // @args: [database = "demo-db-dblp-acm", table_name = "dblp_acm_records_csv", transformation_ctx = "datasource0"] // @return: datasource0 // @inputs: [] val datasource0 = glueContext.getCatalogSource(database = "demo-db-dblp-acm", tableName = "dblp_acm_records_csv", redshiftTmpDir = "", transformationContext = "datasource0").getDynamicFrame() // @type: FindMatches // @args: [transformId = "tfm-123456789012", emitFusion = false, survivorComparisonField = "<primary_id>", transformation_ctx = "findmatches1"] // @return: findmatches1 // @inputs: [frame = datasource0] val findmatches1 = FindMatches.apply(frame = datasource0, transformId = "tfm-123456789012", transformationContext = "findmatches1", computeMatchConfidenceScores = true)// Repartition the previous DynamicFrame into a single partition. val single_partition = findmatches1.repartition(1)// @type: DataSink // @args: [connection_type = "s3", connection_options = {"path": "s3://aws-glue-ml-transforms-data/sal"}, format = "csv", transformation_ctx = "datasink2"] // @return: datasink2 // @inputs: [frame = findmatches1] val datasink2 = glueContext.getSinkWithFormat(connectionType = "s3", options = JsonOptions("""{"path": "s3://aws-glue-ml-transforms-data/sal"}"""), transformationContext = "datasink2", format = "csv").writeDynamicFrame(single_partition) Job.commit() } } Elija Run job (Ejecutar trabajo) para iniciar la ejecución de trabajo. Compruebe el estado del trabajo en la lista de trabajos. Cuando el trabajo finaliza, en ML transform (Transformación ML), en la pestaña History (Historial), habrá una nueva fila Run ID (ID de ejecución) añadida al tipo ETL job (Trabajo de ETL).
Diríjase a Jobs (Trabajos), pestaña History (Historial). En este panel, aparecen las ejecuciones de trabajo. Para obtener más información sobre la ejecución, elija Logs (Registros). Compruebe que el estado de ejecución sea Suceeded (Correcto) cuando finalice.
Paso 6: Verificar los datos de salida desde Amazon S3
En este paso, verificará la salida de la ejecución de trabajo en el bucket de Amazon S3 que elija cuando agregue el trabajo. Puede descargar el archivo de salida en su máquina local y verificar que se identificaron los registros de coincidencia.
Abra la consola de Amazon S3 en https://console.aws.amazon.com/s3/
. Descargue el archivo de salida de destino del trabajo
demo-etl-dblp-acm. Abra el archivo en una aplicación de hoja de cálculo (es posible que tenga que añadir una extensión de archivo.csvpara que el archivo se abra correctamente).La imagen siguiente muestra un fragmento de la salida en Microsoft Excel.
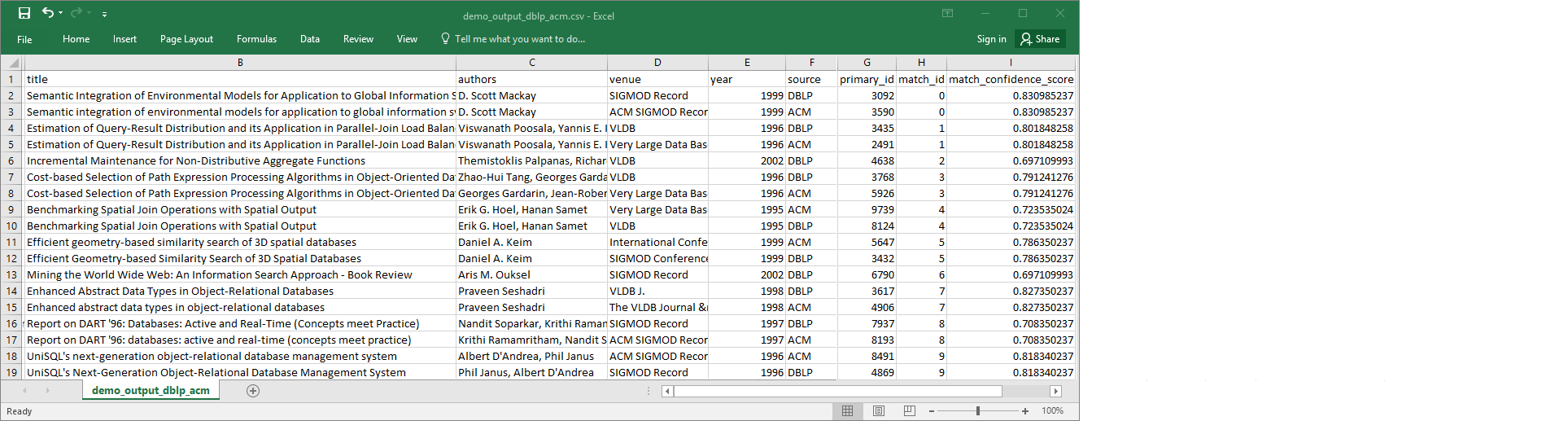
El archivo de origen y destino de datos tiene 4911 registros. Sin embargo, la transformación
Find matchesañade otra columna denominadamatch_idpara identificar registros de coincidencia en la salida. Las filas con el mismomatch_idse consideran registros de coincidencia. Lamatch_confidence_scorees un número entre 0 y 1 que proporciona una estimación de la calidad de las coincidencias encontradas porFind matches.-
Ordene el archivo de salida por
match_idpara ver fácilmente qué registros son coincidencias. Compare los valores en las demás columnas para ver si acepta los resultados de la transformaciónFind matches. Si no es así, puede seguir enseñando a la transformación mediante la adición de más etiquetas.También puede ordenar el archivo por otro campo, como
title, para ver si los registros con títulos similares tienen el mismomatch_id.
