Monitorización con métricas de observabilidad de AWS Glue
nota
Las métricas de observabilidad de AWS Glue están disponibles en AWS Glue, versión 4.0 y versiones posteriores.
Utilice las métricas de observabilidad de AWS Glue para obtener información sobre lo que ocurre dentro de sus trabajos de AWS Glue for Apache Spark y así mejorar la clasificación y el análisis de los problemas. Las métricas de observabilidad se visualizan a través de paneles de control Amazon CloudWatch y se pueden utilizar para analizar la causa raíz de los errores y diagnosticar los cuellos de botella en el rendimiento. Puede reducir el tiempo dedicado a depurar los problemas a gran escala para poder centrarse en resolverlos de forma más rápida y eficaz.
La observabilidad de AWS Glue proporciona métricas Amazon CloudWatch clasificadas en los cuatro grupos siguientes:
-
Fiabilidad (es decir, clases de errores): identifique fácilmente los motivos de error más comunes en un intervalo de tiempo determinado que desee abordar.
-
Rendimiento (es decir, asimetría): identifique un obstáculo en el rendimiento y aplique técnicas de ajuste. Por ejemplo, si experimenta una disminución del rendimiento debido a la asimetría de los trabajos, es posible que desee activar Spark Adaptive Query Execution y ajustar el umbral de unión descompensado.
-
Rendimiento (es decir, rendimiento por fuente/receptor): supervisa las tendencias de lectura y escritura de datos. También puede configurar alarmas Amazon CloudWatch para detectar anomalías.
-
Utilización de los recursos (es decir, el personal, la utilización de la memoria y el disco): encuentre de manera eficiente los trabajos con un bajo uso de la capacidad. Es posible que desee habilitar el escalado automático de AWS Glue para esos trabajos.
Cómo empezar con las métricas de observabilidad de AWS Glue
nota
Las nuevas métricas están habilitadas de forma predeterminada en la consola de AWS Glue Studio.
Para configurar las métricas de observabilidad en AWS Glue Studio:
-
Inicie sesión en la consola AWS Glue y seleccione Trabajos ETL en el menú de la consola.
-
Elija un trabajo haciendo clic en el nombre del trabajo en la sección Sus trabajos.
-
Elija la pestaña Detalles del trabajo.
-
Desplácese hasta la parte inferior y seleccione Propiedades avanzadas y, a continuación, Métricas de observabilidad del trabajo.
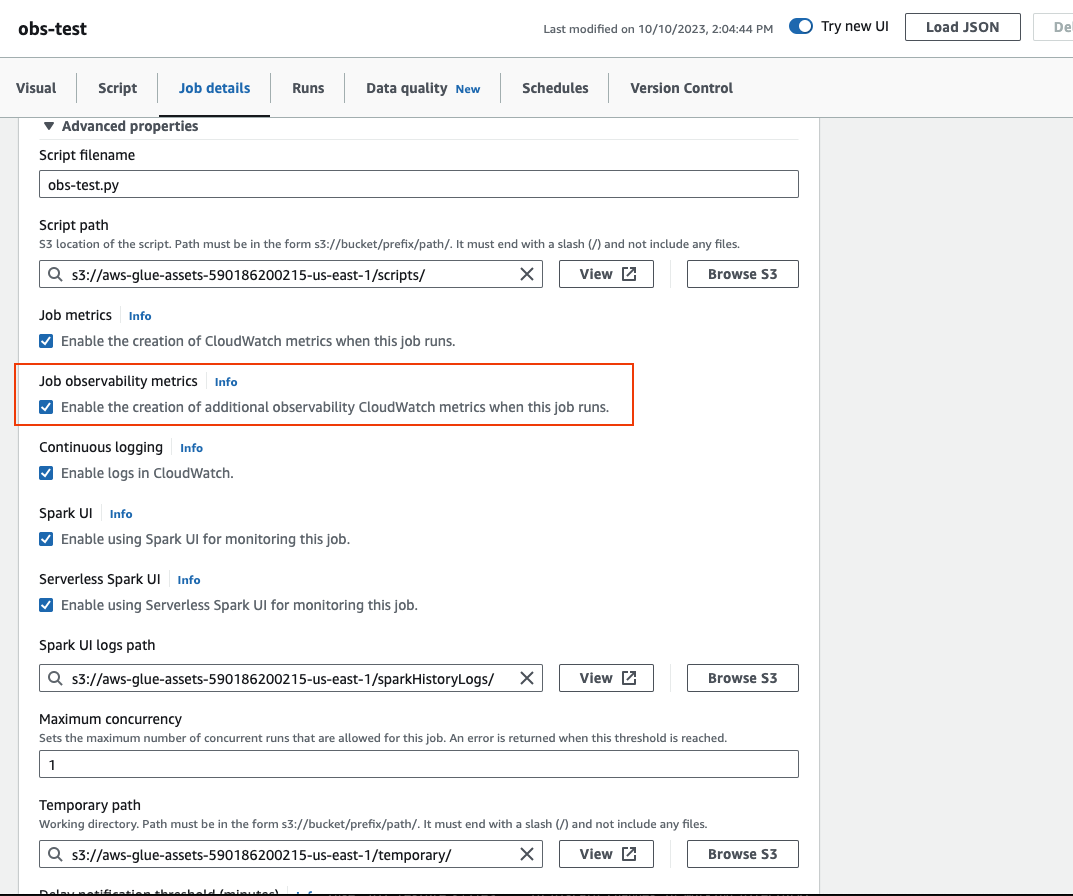
Para habilitar las métricas de observabilidad de AWS Glue usando AWS CLI:
-
Agregue al mapa
--default-argumentsel siguiente valor-clave en el archivo JSON de entrada:--enable-observability-metrics, true
Uso de la observabilidad de AWS Glue
Dado que las métricas de observabilidad de AWS Glue se proporcionan mediante Amazon CloudWatch, puede usar la consola Amazon CloudWatch, AWS CLI, el SDK o la API para consultar los puntos de datos de las métricas de observabilidad. Consulte Uso de observabilidad de Glue para monitorear el uso de los recursos a fin de reducir el costo
Uso de la observabilidad de AWS Glue en la consola Amazon CloudWatch
Para consultar y visualizar las métricas en la consola Amazon CloudWatch:
-
Abra la consola Amazon CloudWatch y seleccione Todas las métricas.
-
En Espacios de nombres personalizados, seleccione AWS Glue.
-
Elija Métricas de observabilidad de trabajo, Métricas de observabilidad por origen o Métricas de observabilidad por receptor.
-
Busque el nombre de la métrica, el nombre del trabajo o el identificador de ejecución específicos y selecciónelos.
-
En la pestaña Métricas graficadas, configure la estadística, el período y otras opciones que prefiera.
Para consultar una métrica de observabilidad mediante AWS CLI:
-
Cree un archivo JSON de definición de métricas y reemplace
your-Glue-job-nameyyour-Glue-job-run-id.$ cat multiplequeries.json [ { "Id": "avgWorkerUtil_0", "MetricStat": { "Metric": { "Namespace": "Glue", "MetricName": "glue.driver.workerUtilization", "Dimensions": [ { "Name": "JobName", "Value": "<your-Glue-job-name-A>" }, { "Name": "JobRunId", "Value": "<your-Glue-job-run-id-A>" }, { "Name": "Type", "Value": "gauge" }, { "Name": "ObservabilityGroup", "Value": "resource_utilization" } ] }, "Period": 1800, "Stat": "Minimum", "Unit": "None" } }, { "Id": "avgWorkerUtil_1", "MetricStat": { "Metric": { "Namespace": "Glue", "MetricName": "glue.driver.workerUtilization", "Dimensions": [ { "Name": "JobName", "Value": "<your-Glue-job-name-B>" }, { "Name": "JobRunId", "Value": "<your-Glue-job-run-id-B>" }, { "Name": "Type", "Value": "gauge" }, { "Name": "ObservabilityGroup", "Value": "resource_utilization" } ] }, "Period": 1800, "Stat": "Minimum", "Unit": "None" } } ] -
Ejecute el comando
get-metric-data:$ aws cloudwatch get-metric-data --metric-data-queries file: //multiplequeries.json \ --start-time '2023-10-28T18: 20' \ --end-time '2023-10-28T19: 10' \ --region us-east-1 { "MetricDataResults": [ { "Id": "avgWorkerUtil_0", "Label": "<your-label-for-A>", "Timestamps": [ "2023-10-28T18:20:00+00:00" ], "Values": [ 0.06718750000000001 ], "StatusCode": "Complete" }, { "Id": "avgWorkerUtil_1", "Label": "<your-label-for-B>", "Timestamps": [ "2023-10-28T18:50:00+00:00" ], "Values": [ 0.5959183673469387 ], "StatusCode": "Complete" } ], "Messages": [] }
Métricas de observabilidad
La observabilidad de AWS Glue crea perfiles y envía las siguientes métricas a Amazon CloudWatch cada 30 segundos, y algunas de estas métricas pueden estar visibles en la página de monitoreo de JobRuns de AWS Glue Studio.
| Métrica | Descripción | Categoría |
|---|---|---|
| glue.driver.skewness.stage |
Categoría métrica: job_performance Spark clasifica la asimetría de la ejecución: esta métrica captura la asimetría de la ejecución, que puede deberse a una asimetría de los datos de entrada o a una transformación (por ejemplo, una unión sesgada). Los valores de esta métrica se sitúan en el rango de [0, infinito [, donde 0 indica la relación entre el tiempo máximo y el tiempo medio de ejecución de las tareas; entre todas las tareas de la etapa, es inferior a un factor de asimetría de fase determinado. El factor de asimetría de fase predeterminado es 5 y se sobrescribe mediante spark conf: spark.metrics.conf.driver.source.glue.jobperformance.skewnessFactor Un valor de asimetría de fase igual a 1 significa que la relación es el doble del factor de asimetría de fase. El valor de la asimetría de fase se actualiza cada 30 segundos para reflejar la asimetría actual. El valor al final de la fase refleja la asimetría de fase final. Dimensiones válidas: JobName (el nombre del trabajo de AWS Glue), JobRunId (el ID de JobRun o ALL), Type (calibre) y ObservAbilityGroup (job_performance) Estadísticas válidas: promedio, máximo, mínimo, percentilo Unidad: recuento |
job_performance |
| glue.driver.skewness.job |
Categoría métrica: job_performance La asimetría del trabajo es el promedio ponderado de la asimetría de las etapas del trabajo. El promedio ponderado da más peso a las etapas que tardan más en ejecutarse. El propósito de esto evitar el caso extremo en el que una etapa muy asimétrica dure muy poco tiempo en comparación con otras etapas (y, por lo tanto, su asimetría no sea significativa para el rendimiento general del trabajo y no valga la pena hacer el esfuerzo para tratar de corregir esa asimetría). Esta métrica se actualiza al finalizar cada etapa y, por lo tanto, el último valor refleja la asimetría general real del trabajo. Dimensiones válidas: JobName (el nombre del trabajo de AWS Glue), JobRunId (el ID de JobRun o ALL), Type (calibre) y ObservAbilityGroup (job_performance) Estadísticas válidas: promedio, máximo, mínimo, percentilo Unidad: recuento |
job_performance |
| glue.succeed.ALL |
Categoría métrica: error Número total de tareas ejecutadas correctamente, para completar el panorama de las categorías de errores Dimensiones válidas: JobName (el nombre del trabajo de AWS Glue), JobRunId (el ID de JobRun o ALL), Type (recuento) y ObservAbilityGroup (error) Estadísticas válidas: SUMA Unidad: recuento |
error |
| glue.error.ALL |
Categoría métrica: error Número total de errores al momento de ejecutar el trabajo, para completar el panorama de las categorías de errores Dimensiones válidas: JobName (el nombre del trabajo de AWS Glue), JobRunId (el ID de JobRun o ALL), Type (recuento) y ObservAbilityGroup (error) Estadísticas válidas: SUMA Unidad: recuento |
error |
| glue.error. [categoría de error] |
Categoría métrica: error En realidad, se trata de un conjunto de métricas que se actualizan únicamente cuando se produce un error en la ejecución de un trabajo. La categorización de los errores ayuda a clasificar y depurar errores. Cuando se produce un error al ejecutar un trabajo, se clasifica el error que lo ha provocado y la métrica de la categoría de error correspondiente se define en 1. Esto ayuda a realizar un análisis de los errores a lo largo del tiempo, así como un análisis de los errores de todos los trabajos, para identificar las categorías de errores más comunes y empezar a abordarlas. AWS Glue tiene 28 categorías de error, incluidas las categorías de error OUT_OF_MEMORY (controlador y ejecutor), PERMISSION, SYNTAX y THROTTLING. Las categorías de error también incluyen las categorías COMPILATION, LAUNCH y TIMEOUT. Dimensiones válidas: JobName (el nombre del trabajo de AWS Glue), JobRunId (el ID de JobRun o ALL), Type (recuento) y ObservAbilityGroup (error) Estadísticas válidas: SUMA Unidad: recuento |
error |
| glue.driver.workerUtilization |
Categoría de métrica: resource_utilization El porcentaje de los trabajadores asignados que se utilizan realmente. Si no es bueno, el escalado automático puede ayudar. Dimensiones válidas: JobName (el nombre del trabajo de AWS Glue), JobRunId (el ID de JobRun o ALL), Type (calibre), y ObservAbilityGroup (resource_utilization) Estadísticas válidas: promedio, máximo, mínimo, percentilo Unidad: porcentaje |
resource_utilization |
| glue.driver.memory.heap. [disponible | usado] |
Categoría de métrica: resource_utilization La memoria de pila disponible o utilizada por el controlador durante la ejecución del trabajo. Esto ayuda a entender las tendencias de uso de la memoria, especialmente a lo largo del tiempo, lo que puede ayudar a evitar posibles fallos, además de depurar los errores relacionados con la memoria. Dimensiones válidas: JobName (el nombre del trabajo de AWS Glue), JobRunId (el ID de JobRun o ALL), Type (calibre), y ObservAbilityGroup (resource_utilization) Estadísticas válidas: Average Unidad: bytes |
resource_utilization |
| glue.driver.memory.heap.used.percentage |
Categoría de métrica: resource_utilization El controlador utilizó (%) la memoria acumulada durante la ejecución del trabajo. Esto ayuda a entender las tendencias de uso de la memoria, especialmente a lo largo del tiempo, lo que puede ayudar a evitar posibles fallos, además de depurar los errores relacionados con la memoria. Dimensiones válidas: JobName (el nombre del trabajo de AWS Glue), JobRunId (el ID de JobRun o ALL), Type (calibre), y ObservAbilityGroup (resource_utilization) Estadísticas válidas: Average Unidad: porcentaje |
resource_utilization |
| glue.driver.memory.non-heap. [disponible | usado] |
Categoría de métrica: resource_utilization La memoria no acumulada disponible o utilizada por el controlador durante la ejecución del trabajo. Esto ayuda a entender las tendencias de uso de la memoria, especialmente a lo largo del tiempo, lo que puede ayudar a evitar posibles fallos, además de depurar los errores relacionados con la memoria. Dimensiones válidas: JobName (el nombre del trabajo de AWS Glue), JobRunId (el ID de JobRun o ALL), Type (calibre), y ObservAbilityGroup (resource_utilization) Estadísticas válidas: Average Unidad: bytes |
resource_utilization |
| glue.driver.memory.non-heap.used.percentage |
Categoría de métrica: resource_utilization El controlador utilizó (%) memoria no acumulada durante la ejecución del trabajo. Esto ayuda a entender las tendencias de uso de la memoria, especialmente a lo largo del tiempo, lo que puede ayudar a evitar posibles fallos, además de depurar los errores relacionados con la memoria. Dimensiones válidas: JobName (el nombre del trabajo de AWS Glue), JobRunId (el ID de JobRun o ALL), Type (calibre), y ObservAbilityGroup (resource_utilization) Estadísticas válidas: Average Unidad: porcentaje |
resource_utilization |
| glue.driver.memory.total. [disponible | usado] |
Categoría de métrica: resource_utilization La memoria total disponible o utilizada por el controlador durante la ejecución del trabajo. Esto ayuda a entender las tendencias de uso de la memoria, especialmente a lo largo del tiempo, lo que puede ayudar a evitar posibles fallos, además de depurar los errores relacionados con la memoria. Dimensiones válidas: JobName (el nombre del trabajo de AWS Glue), JobRunId (el ID de JobRun o ALL), Type (calibre), y ObservAbilityGroup (resource_utilization) Estadísticas válidas: Average Unidad: bytes |
resource_utilization |
| glue.driver.memory.total.used.percentage |
Categoría de métrica: resource_utilization El controlador utilizó (%) de la memoria total durante la ejecución del trabajo. Esto ayuda a entender las tendencias de uso de la memoria, especialmente a lo largo del tiempo, lo que puede ayudar a evitar posibles fallos, además de depurar los errores relacionados con la memoria. Dimensiones válidas: JobName (el nombre del trabajo de AWS Glue), JobRunId (el ID de JobRun o ALL), Type (calibre), y ObservAbilityGroup (resource_utilization) Estadísticas válidas: Average Unidad: porcentaje |
resource_utilization |
| Glue.all.memory.heap. [disponible | usado] |
Categoría de métrica: resource_utilization La memoria de pila utilizada/disponible de los ejecutores. ALL significa todos los ejecutores. Dimensiones válidas: JobName (el nombre del trabajo de AWS Glue), JobRunId (el ID de JobRun o ALL), Type (calibre), y ObservAbilityGroup (resource_utilization) Estadísticas válidas: Average Unidad: bytes |
resource_utilization |
| glue.ALL.memory.heap.used.percentage |
Categoría de métrica: resource_utilization La memoria de pila utilizada por los ejecutores (%). ALL significa todos los ejecutores. Dimensiones válidas: JobName (el nombre del trabajo de AWS Glue), JobRunId (el ID de JobRun o ALL), Type (calibre), y ObservAbilityGroup (resource_utilization) Estadísticas válidas: Average Unidad: porcentaje |
resource_utilization |
| glue.ALL.memory.non-heap. [disponible | usado] |
Categoría de métrica: resource_utilization La memoria que no es de pila disponible/utilizada por los ejecutores. ALL significa todos los ejecutores. Dimensiones válidas: JobName (el nombre del trabajo de AWS Glue), JobRunId (el ID de JobRun o ALL), Type (calibre), y ObservAbilityGroup (resource_utilization) Estadísticas válidas: Average Unidad: bytes |
resource_utilization |
| glue.ALL.memory.non-heap.used.percentage |
Categoría de métrica: resource_utilization Los ejecutores utilizaron (%) de memoria que no es de pila. ALL significa todos los ejecutores. Dimensiones válidas: JobName (el nombre del trabajo de AWS Glue), JobRunId (el ID de JobRun o ALL), Type (calibre), y ObservAbilityGroup (resource_utilization) Estadísticas válidas: Average Unidad: porcentaje |
resource_utilization |
| glue.ALL.memory.total. [disponible | usado] |
Categoría de métrica: resource_utilization La memoria total utilizada/disponible de los ejecutores. ALL significa todos los ejecutores. Dimensiones válidas: JobName (el nombre del trabajo de AWS Glue), JobRunId (el ID de JobRun o ALL), Type (calibre), y ObservAbilityGroup (resource_utilization) Estadísticas válidas: Average Unidad: bytes |
resource_utilization |
| glue.ALL.memory.total.used.percentage |
Categoría de métrica: resource_utilization La memoria total (%) utilizada por los ejecutores. ALL significa todos los ejecutores. Dimensiones válidas: JobName (el nombre del trabajo de AWS Glue), JobRunId (el ID de JobRun o ALL), Type (calibre), y ObservAbilityGroup (resource_utilization) Estadísticas válidas: Average Unidad: porcentaje |
resource_utilization |
| glue.driver.disk. [disponible_GB | usado_GB] |
Categoría de métrica: resource_utilization El espacio en disco disponible o usado por el controlador durante la ejecución del trabajo. Esto ayuda a entender las tendencias de uso del disco, especialmente a lo largo del tiempo, lo que puede ayudar a evitar posibles fallos, además de depurar los errores relacionados con la falta de espacio en disco. Dimensiones válidas: JobName (el nombre del trabajo de AWS Glue), JobRunId (el ID de JobRun o ALL), Type (calibre), y ObservAbilityGroup (resource_utilization) Estadísticas válidas: Average Unidad: Gigabytes |
resource_utilization |
| glue.driver.disk.used.percentage] |
Categoría de métrica: resource_utilization El espacio en disco disponible o usado por el controlador durante la ejecución del trabajo. Esto ayuda a entender las tendencias de uso del disco, especialmente a lo largo del tiempo, lo que puede ayudar a evitar posibles fallos, además de depurar los errores relacionados con la falta de espacio en disco. Dimensiones válidas: JobName (el nombre del trabajo de AWS Glue), JobRunId (el ID de JobRun o ALL), Type (calibre), y ObservAbilityGroup (resource_utilization) Estadísticas válidas: Average Unidad: porcentaje |
resource_utilization |
| glue.ALL.disk. [disponible_GB | usado_GB] |
Categoría de métrica: resource_utilization El espacio en disco usado/disponible de los ejecutores. ALL significa todos los ejecutores. Dimensiones válidas: JobName (el nombre del trabajo de AWS Glue), JobRunId (el ID de JobRun o ALL), Type (calibre), y ObservAbilityGroup (resource_utilization) Estadísticas válidas: Average Unidad: Gigabytes |
resource_utilization |
| glue.ALL.disk.used.percentage |
Categoría de métrica: resource_utilization El espacio en disco disponible/usado/usado (%) de los ejecutores. ALL significa todos los ejecutores. Dimensiones válidas: JobName (el nombre del trabajo de AWS Glue), JobRunId (el ID de JobRun o ALL), Type (calibre), y ObservAbilityGroup (resource_utilization) Estadísticas válidas: Average Unidad: porcentaje |
resource_utilization |
| glue.driver.bytesRead |
Categoría métrica: rendimiento El número de bytes leídos por fuente de entrada en esta ejecución de trabajo, y en TODAS las fuentes. Esto ayuda a entender el volumen de datos y sus cambios a lo largo del tiempo, lo que ayuda a tratar problemas como la asimetría de los datos. Dimensiones válidas: JobName (el nombre del trabajo de AWS Glue), JobRunID (el JobRun ID. o ALL), Type (calibre), ObservabilityGroup (resource_utilization) y Source (ubicación de los datos de origen) Estadísticas válidas: Average Unidad: bytes |
rendimiento |
| glue.driver. [Registros leídos | Archivos leídos] |
Categoría métrica: rendimiento El número de registros/archivos leídos por fuente de entrada en esta ejecución de trabajo, y en TODAS las fuentes. Esto ayuda a entender el volumen de datos y sus cambios a lo largo del tiempo, lo que ayuda a tratar problemas como la asimetría de los datos. Dimensiones válidas: JobName (el nombre del trabajo de AWS Glue), JobRunID (el JobRun ID. o ALL), Type (calibre), ObservabilityGroup (resource_utilization) y Source (ubicación de los datos de origen) Estadísticas válidas: Average Unidad: recuento |
rendimiento |
| glue.driver.partitionsRead |
Categoría métrica: rendimiento El número de particiones leídas por fuente de entrada de Amazon S3 en esta ejecución de trabajo, y para TODAS las fuentes. Dimensiones válidas: JobName (el nombre del trabajo de AWS Glue), JobRunID (el JobRun ID. o ALL), Type (calibre), ObservabilityGroup (resource_utilization) y Source (ubicación de los datos de origen) Estadísticas válidas: Average Unidad: recuento |
rendimiento |
| glue.driver.bytesWrittten |
Categoría métrica: rendimiento El número de bytes escritos por receptor de salida en esta ejecución de trabajo, y en TODOS los receptores. Esto ayuda a entender el volumen de datos y cómo evoluciona con el tiempo, lo que ayuda a tratar problemas como la asimetría del procesamiento. Dimensiones válidas: JobName (el nombre del trabajo de AWS Glue), JobRunID (el JobRun ID. o ALL), Type (calibre), ObservabilityGroup (resource_utilization) y Sink (ubicación de los datos de sink) Estadísticas válidas: Average Unidad: bytes |
rendimiento |
| glue.driver. [Registros escritos | Archivos escritos] |
Categoría métrica: rendimiento El número de registros o archivos escritos por receptor de salida en esta ejecución de trabajo, y en TODOS los receptores. Esto ayuda a entender el volumen de datos y cómo evoluciona con el tiempo, lo que ayuda a tratar problemas como la asimetría del procesamiento. Dimensiones válidas: JobName (el nombre del trabajo de AWS Glue), JobRunID (el JobRun ID. o ALL), Type (calibre), ObservabilityGroup (resource_utilization) y Sink (ubicación de los datos de sink) Estadísticas válidas: Average Unidad: recuento |
rendimiento |
Categorías de errores
| Categorías de errores | Descripción |
|---|---|
| COMPILATION_ERROR | Los errores surgen durante la compilación del código de Scala. |
| CONNECTION_ERROR | Los errores se producen durante la conexión a un servicio remoto/servicio de host/base de datos, etc. |
| DISK_NO_SPACE_ERROR |
Los errores se producen cuando no queda espacio en el disco del controlador/ejecutor. |
| OUT_OF_MEMORY_ERROR | Los errores se producen cuando no queda espacio en la memoria del controlador/ejecutor. |
| IMPORT_ERROR | Los errores se producen al importar dependencias. |
| INVALID_ARGUMENT_ERROR | Los errores se producen cuando los argumentos de entrada son inválidos o ilegales. |
| PERMISSION_ERROR | Los errores se producen cuando no se tiene el permiso para acceder al servicio, los datos, etc. |
| RESOURCE_NOT_FOUND_ERROR |
Los errores se producen cuando los datos, la ubicación, etc. no existen. |
| QUERY_ERROR | Los errores se producen por la ejecución de una consulta SQL de Spark. |
| SYNTAX_ERROR | Los errores se producen cuando hay un error de sintaxis en el script. |
| THROTTLING_ERROR | Los errores se producen cuando se alcanza el límite de simultaneidad del servicio o se supera el límite de la cuota de servicio. |
| DATA_LAKE_FRAMEWORK_ERROR | Los errores se deben a un marco de lago de datos con soporte nativo de AWS Glue, como Hudi, Iceberg, etc. |
| UNSUPPORTED_OPERATION_ERROR | Los errores se producen al realizar una operación no compatible. |
| RESOURCES_ALREADY_EXISTS_ERROR | Los errores se producen cuando un recurso que se va a crear o añadir ya existe. |
| GLUE_INTERNAL_SERVICE_ERROR | Los errores se producen cuando hay un problema de servicio interno de AWS Glue. |
| GLUE_OPERATION_TIMEOUT_ERROR | Los errores se producen cuando se agota el tiempo de espera de una operación de AWS Glue. |
| GLUE_VALIDATION_ERROR | Los errores se producen cuando no se ha podido validar un valor requerido para el trabajo de AWS Glue. |
| GLUE_JOB_BOOKMARK_VERSION_MISMATCH_ERROR | Los errores se producen cuando ejecuta el mismo trabajo en el mismo bucket de origen y escribe en el mismo destino o en uno diferente simultáneamente (concurrencia >1) |
| LAUNCH_ERROR | Los errores se producen durante la fase de inicio del trabajo de AWS Glue. |
| DYNAMODB_ERROR | Los errores genéricos se deben al servicio de Amazon DynamoDB. |
| GLUE_ERROR | Los errores genéricos se deben al servicio de AWS Glue. |
| LAKEFORMATION_ERROR | Los errores genéricos se deben al servicio de AWS Lake Formation. |
| REDSHIFT_ERROR | Los errores genéricos se deben al servicio de Amazon Redshift. |
| S3_ERROR | Los errores genéricos se deben al servicio de Amazon S3. |
| SYSTEM_EXIT_ERROR | Error genérico de salida del sistema. |
| TIMEOUT_ERROR | Los errores genéricos se producen cuando el trabajo falla debido al tiempo de espera de la operación. |
| UNCLASSIFIED_SPARK_ERROR | Los errores genéricos se deben a Spark. |
| UNCLASSIFIED_ERROR | Categoría de errores predeterminada. |
Limitaciones
nota
glueContext debe inicializarse para publicar las métricas.
En la dimensión de origen, el valor es la ruta de Amazon S3 o el nombre de la tabla, según el tipo de fuente. Además, si la fuente es JDBC y se usa la opción de consulta, la cadena de consulta se establece en la dimensión de origen. Si el valor tiene más de 500 caracteres, se recorta hasta 500 caracteres. El valor tiene las siguientes limitaciones:
-
Se eliminarán los caracteres que no sean ASCII.
Si el nombre de la fuente no contiene ningún carácter ASCII, se convierte en <non-ASCII input>.
Limitaciones y consideraciones de las métricas de rendimiento
-
Se admiten DataFrame y DynamicFrame basado en DataFrame (por ejemplo, JDBC, lectura desde parquet en Amazon S3); sin embargo, no se admite DynamicFrame basado en RDD (por ejemplo, leer csv, json en Amazon S3, etc.). Técnicamente, se admiten todas las lecturas y escrituras visibles en la interfaz de usuario de Spark.
-
La métrica
recordsReadse emitirá si el origen de datos es una tabla de catálogo y el formato es JSON, CSV, texto o Iceberg. -
Las métricas
glue.driver.throughput.recordsWritten,glue.driver.throughput.bytesWrittenyglue.driver.throughput.filesWrittenno están disponibles en las tablas JDBC e Iceberg. -
Es posible que las métricas se retrasen. Si el trabajo finaliza en aproximadamente un minuto, es posible que no haya métricas de rendimiento en Amazon CloudWatch Metrics.
