Depuración de excepciones de memoria insuficiente e irregularidades relativas al trabajo
Puede depurar excepciones de memoria insuficiente (OOM) e irregularidades relativas al trabajo en AWS Glue. En las siguientes secciones se describen situaciones de depuración de excepciones de memoria insuficiente del controlador Apache Spark o un ejecutor de Spark.
Depuración de una excepción de memoria insuficiente del controlador
En esta situación, un trabajo de Spark está leyendo un gran número de pequeños archivos desde Amazon Simple Storage Service (Amazon S3). Convierte los archivos al formato Apache Parquet y, a continuación, los escribe en Amazon S3. El controlador Spark se está quedando sin memoria. Los datos de Amazon S3 de entrada tienen más de un millón de archivos en diferentes particiones de Amazon S3.
El código con perfil es el siguiente:
data = spark.read.format("json").option("inferSchema", False).load("s3://input_path") data.write.format("parquet").save(output_path)
Visualizar las métricas con perfil en la consola de AWS Glue
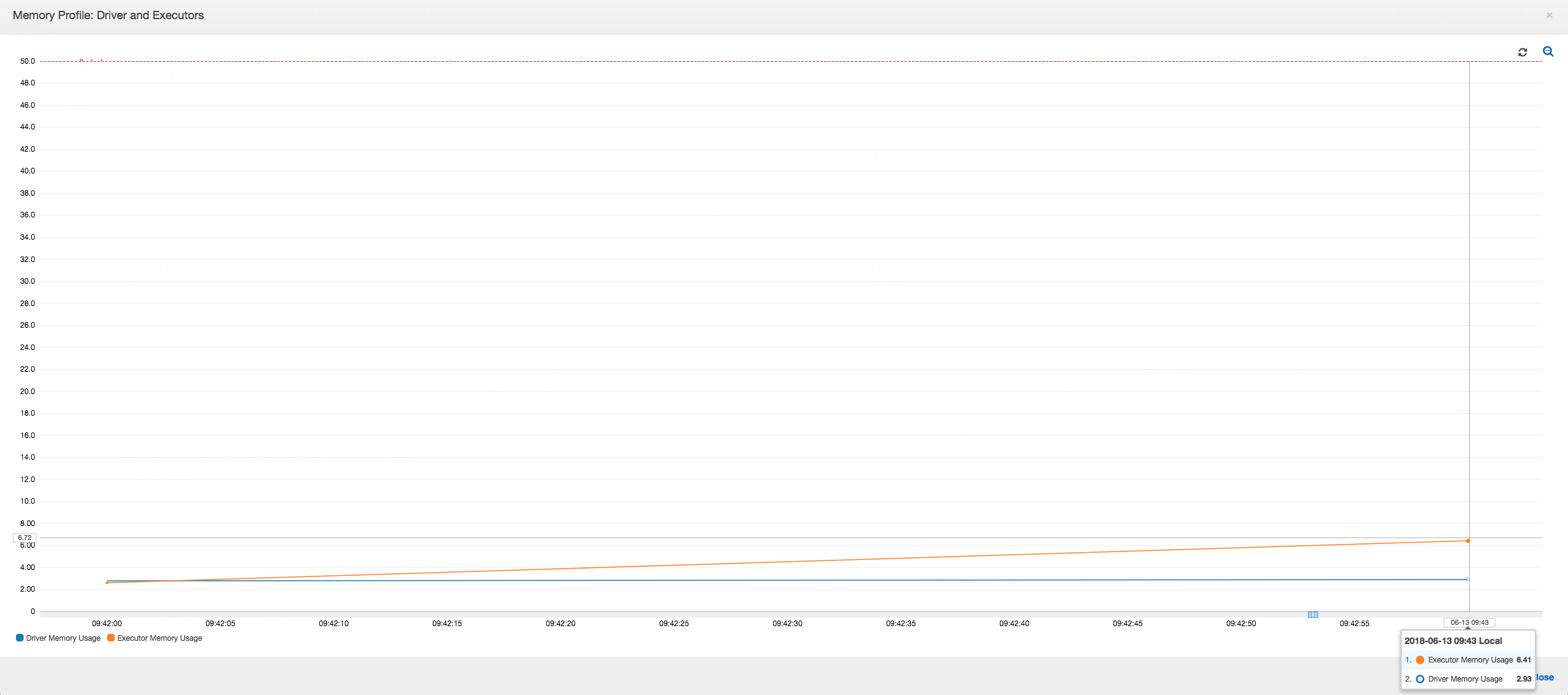
En el siguiente gráfico se muestra el uso de la memoria como porcentaje del controlador y los ejecutores. Este uso se traza como un punto de datos que se promedia a lo largo de los valores notificados en el último minuto. En el perfil de la memoria del trabajo, puede ver que la memoria del controlador cruza el umbral seguro del 50 % de uso con rapidez. Por otra parte, el uso medio de la memoria en todos los ejecutores sigue siendo inferior al 4 %. Esto es una clara muestra de irregularidad en la ejecución del controlador en el trabajo de Spark.
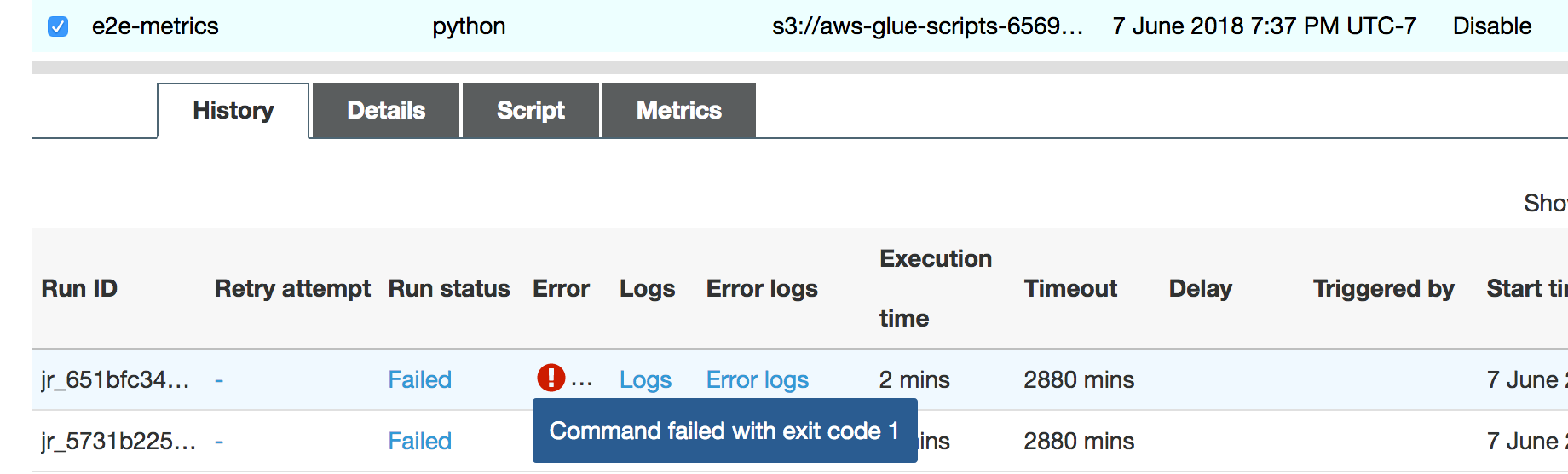
La ejecución del trabajo produce un error enseguida y aparece el siguiente error en la pestaña History (Historial) de la consola de AWS Glue: Command Failed with Exit Code 1. Esta cadena de error significa que el trabajo falló debido a un error sistémico, que en este caso se trata de la falta de memoria del controlador.
En la consola, elija el enlace Error logs (Registros de error) en la pestaña History (Historial) para confirmar el hallazgo relativo a la falta de memoria del controlador desde CloudWatch Logs. Busque "Error" en los registros de errores del trabajo para confirmar que se trató, sin duda, de una excepción de memoria insuficiente que imposibilitó la realización del trabajo:
# java.lang.OutOfMemoryError: Java heap space # -XX:OnOutOfMemoryError="kill -9 %p" # Executing /bin/sh -c "kill -9 12039"...
En la pestaña History (Historial) del trabajo, elija Logs (Registros). Puede encontrar el siguiente rastro de la ejecución del controlador en CloudWatch Logs al empezar el trabajo. El controlador Spark intenta listar todos los archivos en todos los directorios, crea InMemoryFileIndex y lanza una tarea por archivo. Esto, a su vez, hace que el controlador Spark tenga que mantener una gran cantidad de estado en memoria para realizar un seguimiento de todas las tareas. Almacena en caché la lista completa de un gran número de archivos para el índice en memoria, lo que da lugar a la falta de memoria de un controlador.
Corregir el procesamiento de varios archivos mediante su agrupación
Puede corregir el procesamiento de los numerosos archivos mediante la capacitación de agrupación en AWS Glue. La agrupación se habilita automáticamente al usar marcos dinámicos y cuando el conjunto de datos de entrada tiene un gran número de archivos (más de 50 000). La agrupación le permite fusionar varios archivos en un grupo y deja que una tarea procese todo el grupo en vez de un solo archivo. Como resultado, la cantidad de estado en memoria que almacena el controlador Spark es considerablemente más baja para realizar un seguimiento de menos tareas. Para obtener más información acerca de cómo habilitar manualmente la agrupación de su conjunto de datos, consulte Lectura de archivos de entrada en grupos más grandes.
Para comprobar el perfil de la memoria del trabajo de AWS Glue, genere perfiles en el siguiente código con la agrupación habilitada:
df = glueContext.create_dynamic_frame_from_options("s3", {'paths': ["s3://input_path"], "recurse":True, 'groupFiles': 'inPartition'}, format="json") datasink = glueContext.write_dynamic_frame.from_options(frame = df, connection_type = "s3", connection_options = {"path": output_path}, format = "parquet", transformation_ctx = "datasink")
Puede monitorear el perfil de la memoria y el movimiento de datos de ETL en el perfil de trabajo de AWS Glue.
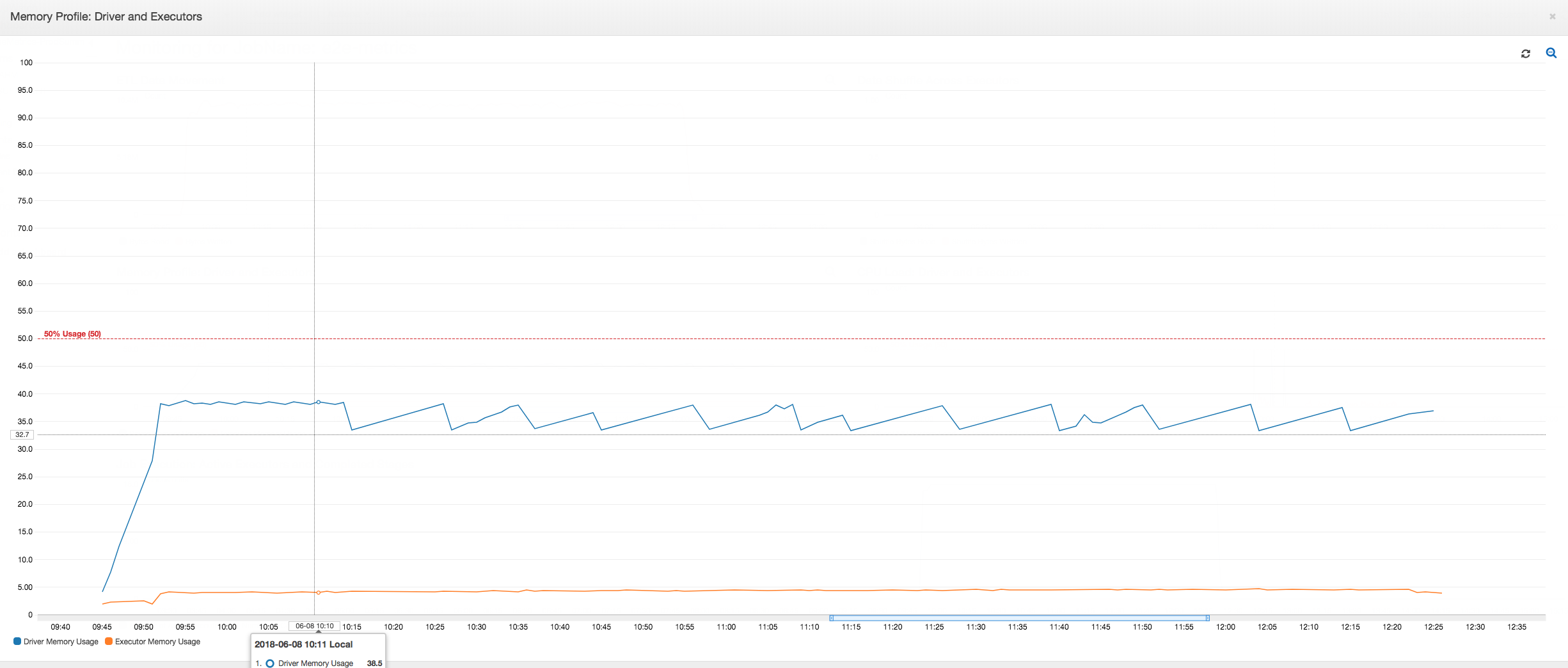
El controlador se ejecuta por debajo del umbral del 50 % de uso de la memoria durante todo el trabajo de AWS Glue. Los ejecutores transmiten los datos desde Amazon S3, los procesan y los escriben en Amazon S3. Como resultado, consumen un porcentaje de memoria inferior al 5 % en cualquier momento.
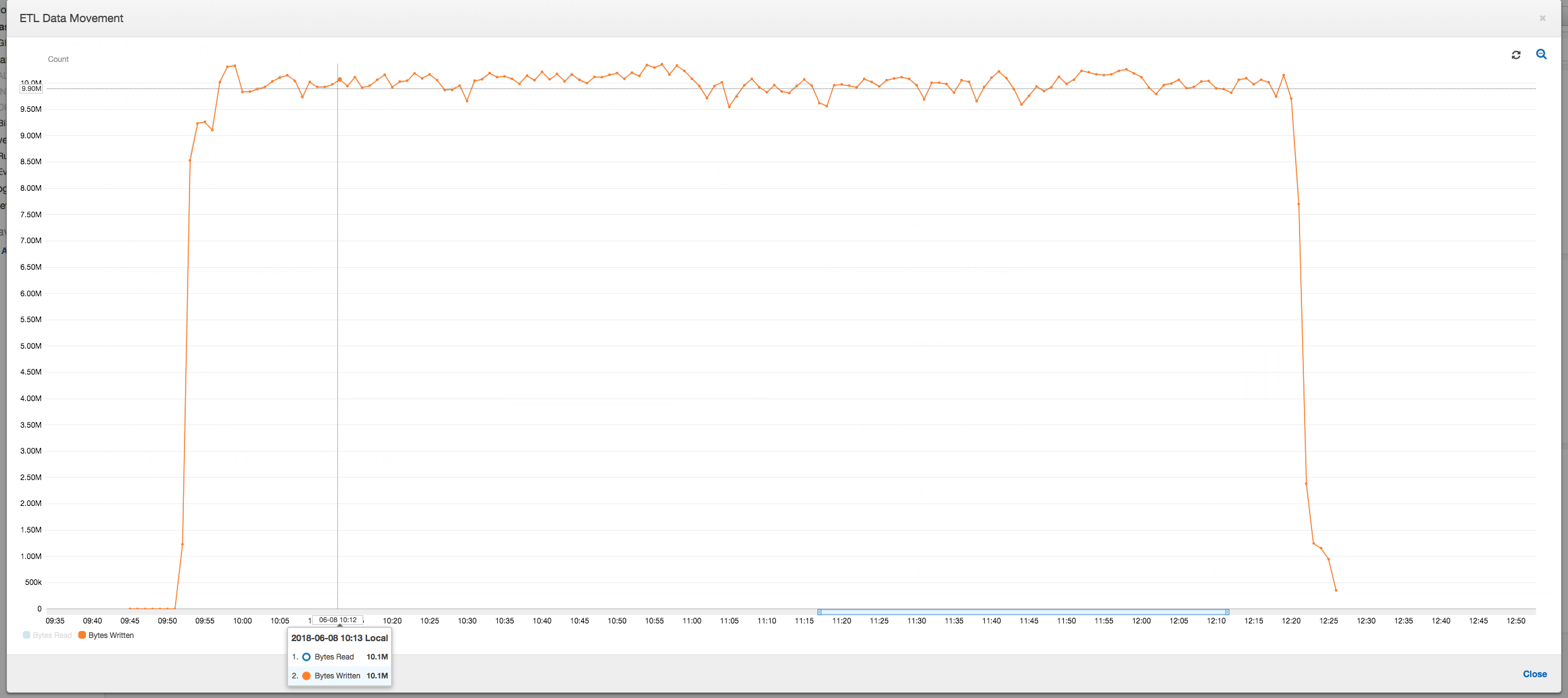
El perfil de movimiento de datos a continuación muestra el número total de bytes de Amazon S3 que todos los ejecutores leen y escriben en el último minuto a medida que progresa el trabajo. Ambos siguen un patrón similar, puesto que todos los ejecutores transmiten los datos. El trabajo termina de procesar el millón de archivos en menos de tres horas.
Depuración de una excepción de memoria insuficiente del ejecutor
En esta situación, puede aprender a depurar excepciones de memoria insuficiente que podrían producirse en los ejecutores Apache Spark. El siguiente código usa el lector de Spark MySQL para leer una gran tabla de unos 34 millones de filas en un DataFrame de Spark. A continuación, la escribe en Amazon S3 en formato Parquet. Puede proporcionar las propiedades de la conexión y usar las configuraciones de Spark predeterminadas para leer la tabla.
val connectionProperties = new Properties() connectionProperties.put("user", user) connectionProperties.put("password", password) connectionProperties.put("Driver", "com.mysql.jdbc.Driver") val sparkSession = glueContext.sparkSession val dfSpark = sparkSession.read.jdbc(url, tableName, connectionProperties) dfSpark.write.format("parquet").save(output_path)
Visualizar las métricas con perfil en la consola de AWS Glue
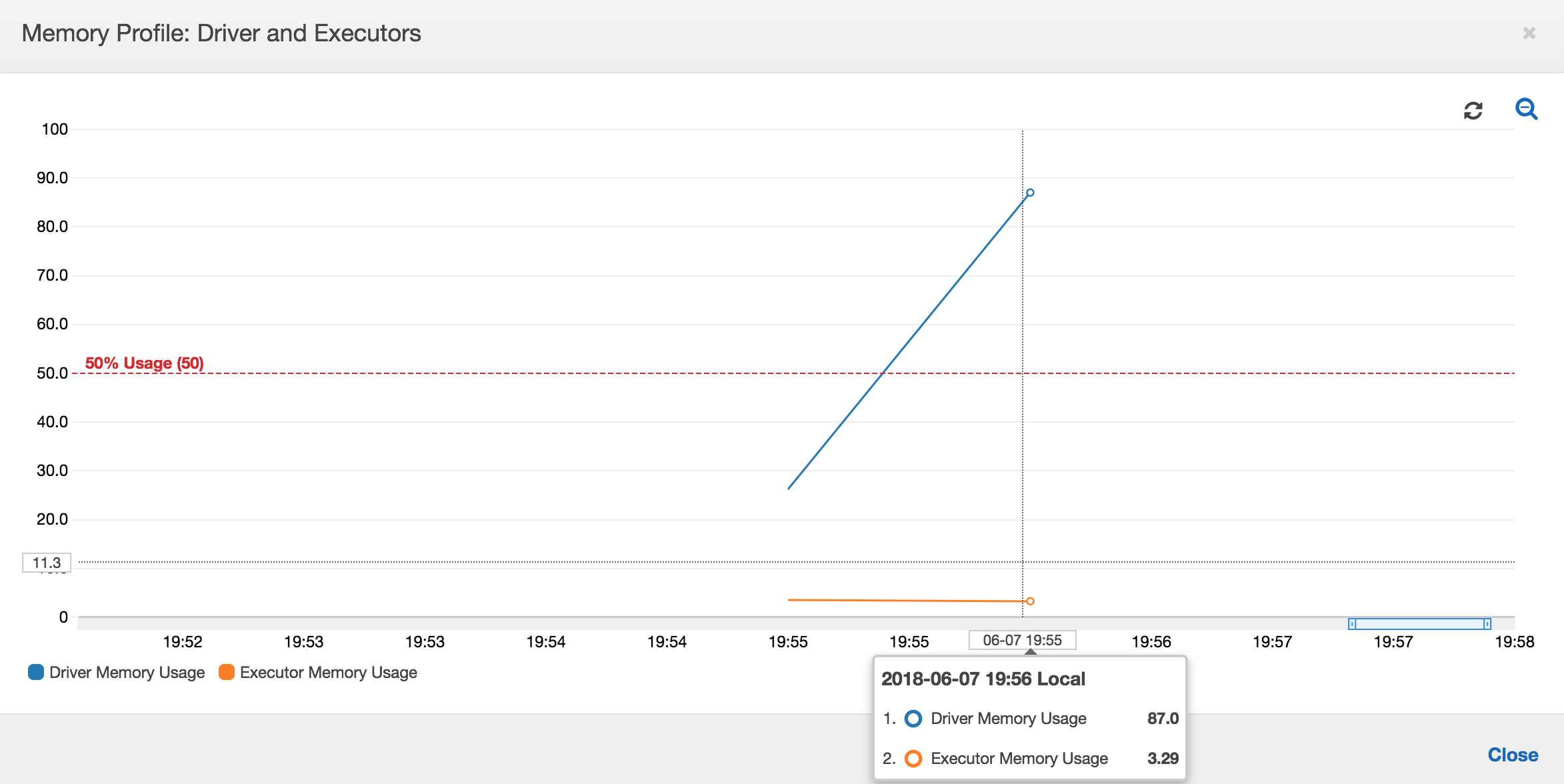
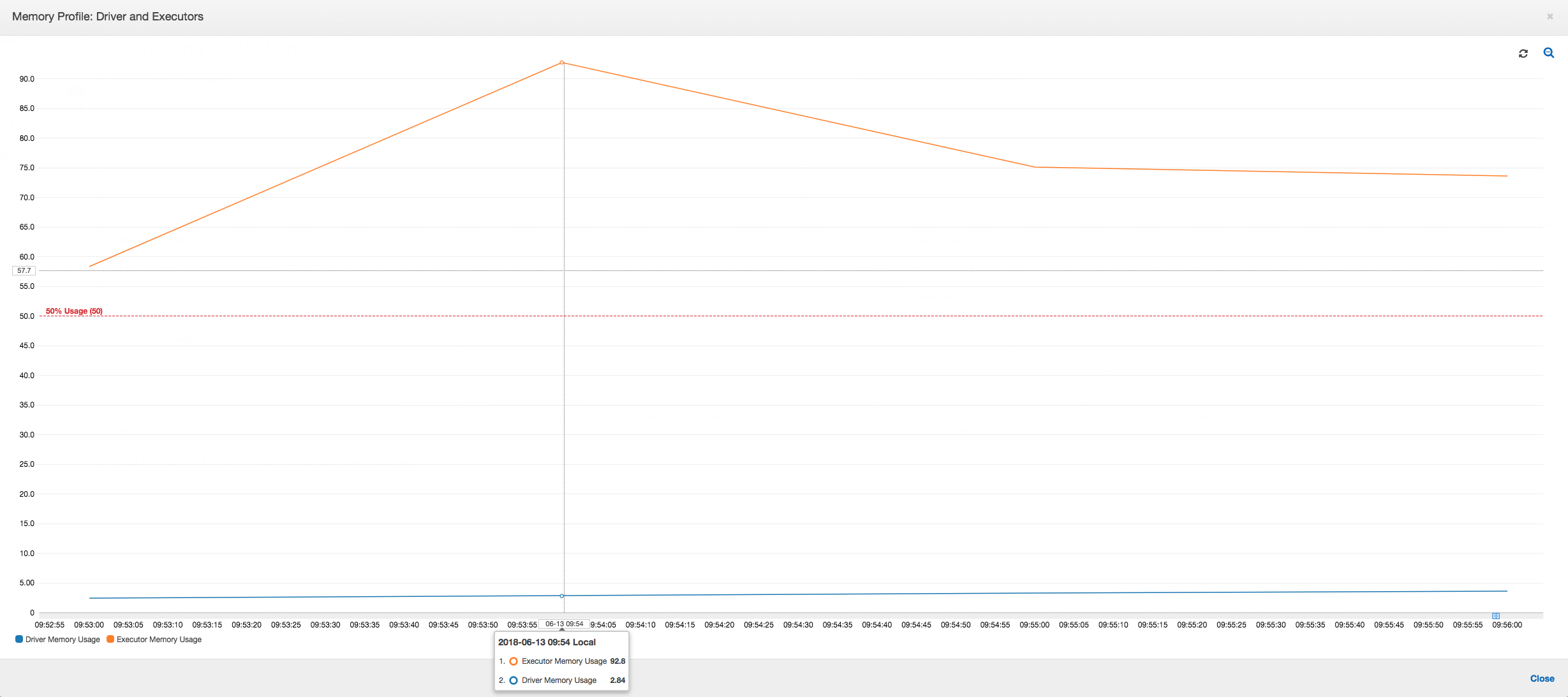
Si la pendiente del gráfico de uso de memoria es positiva y supera el 50 por ciento, si se produce un error en el trabajo antes de que se emita la siguiente métrica, la causa bien se puede deber al agotamiento de memoria. En el siguiente gráfico se muestra que, transcurrido un minuto desde el inicio de la ejecución, el uso medio de la memoria en todos los ejecutores aumenta rápidamente por encima del 50 %. El uso llega a alcanzar el 92 % y Apache Hadoop YARN cancela el contenedor que ejecuta el ejecutor.
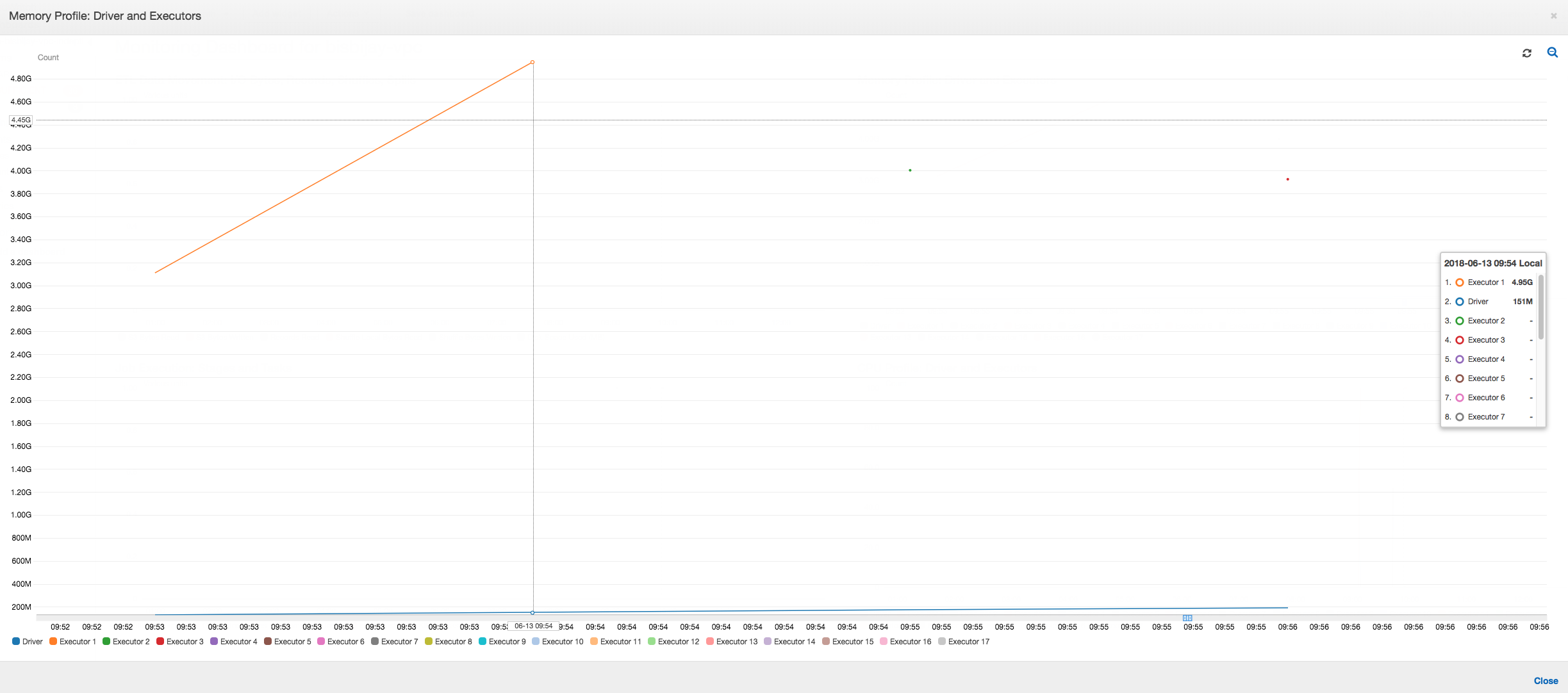
Tal como aparece en el siguiente gráfico, siempre hay un único ejecutor en ejecución hasta que el trabajo produce un error. Esto se debe al lanzamiento de un nuevo ejecutor para reemplazar el ejecutor cancelado. Las lecturas del origen de datos JDBC no se paralelizan de forma predeterminada, ya que requeriría que se particionara la tabla en una columna y que se abrieran varias conexiones. Como resultado, solo un ejecutor lee la tabla completa de forma secuencial.

Tal como se muestra en el siguiente gráfico, Spark intenta lanzar una nueva tarea cuatro veces antes de producir el trabajo el error. Puede ver el perfil de la memoria de tres ejecutores. Cada ejecutor usa rápidamente toda su memoria. El cuarto ejecutor se queda sin memoria y el trabajo produce un error. Como resultado, su métrica no se notifica inmediatamente.
Puede confirmar desde la cadena de error de la consola de AWS Glue que el trabajo produjo un error debido a excepciones de memoria insuficiente, como se muestra en la siguiente imagen.

Registros de salida del trabajo: para confirmar aún más su hallazgo de una excepción de memoria insuficiente, examine CloudWatch Logs. Al buscar Error, verá cómo se cancelan los cuatro ejecutores casi al mismo tiempo como se muestra en el panel de métricas. YARN termina todos, ya que superan sus límites de memoria.
Ejecutor 1
18/06/13 16:54:29 WARN YarnAllocator: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:54:29 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:54:29 ERROR YarnClusterScheduler: Lost executor 1 on ip-10-1-2-175.ec2.internal: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:54:29 WARN TaskSetManager: Lost task 0.0 in stage 0.0 (TID 0, ip-10-1-2-175.ec2.internal, executor 1): ExecutorLostFailure (executor 1 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
Ejecutor 2
18/06/13 16:55:35 WARN YarnAllocator: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:55:35 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:55:35 ERROR YarnClusterScheduler: Lost executor 2 on ip-10-1-2-16.ec2.internal: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:55:35 WARN TaskSetManager: Lost task 0.1 in stage 0.0 (TID 1, ip-10-1-2-16.ec2.internal, executor 2): ExecutorLostFailure (executor 2 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
Ejecutor 3
18/06/13 16:56:37 WARN YarnAllocator: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:56:37 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:56:37 ERROR YarnClusterScheduler: Lost executor 3 on ip-10-1-2-189.ec2.internal: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:56:37 WARN TaskSetManager: Lost task 0.2 in stage 0.0 (TID 2, ip-10-1-2-189.ec2.internal, executor 3): ExecutorLostFailure (executor 3 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 5.8 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
Ejecutor 4
18/06/13 16:57:18 WARN YarnAllocator: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:57:18 WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:57:18 ERROR YarnClusterScheduler: Lost executor 4 on ip-10-1-2-96.ec2.internal: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead. 18/06/13 16:57:18 WARN TaskSetManager: Lost task 0.3 in stage 0.0 (TID 3, ip-10-1-2-96.ec2.internal, executor 4): ExecutorLostFailure (executor 4 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 5.5 GB of 5.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
Corregir la configuración del tamaño de búsqueda mediante marcos dinámicos de AWS Glue
El ejecutor se quedó sin memoria durante la lectura de la tabla de JDBC, ya que la configuración predeterminada del tamaño de búsqueda de JDBC de Spark es cero. Esto significa que el controlador JDBC del ejecutor de Spark intenta recuperar los 34 millones de filas de la base de datos de forma conjunta y almacenarlas en caché, aunque Spark se transmita a través de las filas de una en una. Con Spark, puede evitar esta situación estableciendo el parámetro de tamaño de búsqueda en un valor predeterminado distinto de cero.
También puede solucionar este problema con marcos dinámicos de AWS Glue en su lugar. De forma predeterminada, los marcos dinámicos utilizan un tamaño de captura de 1000 filas, que suele ser un valor suficiente. Como resultado, el ejecutor no usa más del 7 % de su memoria total. El trabajo de AWS Glue finaliza en menos de dos minutos con un único ejecutor solamente. Aunque el enfoque recomendado es utilizar los marcos dinámicos de AWS Glue, también se puede definir el tamaño de captura con la propiedad fetchsize de Apache Spark. Consulte la guía de Spark SQL, DataFrames y Datasets
val (url, database, tableName) = { ("jdbc_url", "db_name", "table_name") } val source = glueContext.getSource(format, sourceJson) val df = source.getDynamicFrame glueContext.write_dynamic_frame.from_options(frame = df, connection_type = "s3", connection_options = {"path": output_path}, format = "parquet", transformation_ctx = "datasink")
Métricas con perfil normales: la memoria del ejecutor con marcos dinámicos de AWS Glue nunca supera el umbral seguro, como se muestra en la siguiente imagen. Se transmite en las filas de la base de datos y almacena en caché solo 1000 filas en el controlador JDBC en cualquier momento. No se producen excepciones de memoria insuficiente.