Monitorización de trabajos mediante la interfaz de usuario web de Apache Spark
Puede utilizar la interfaz de usuario web de Apache Spark para monitorizar y depurar trabajos de ETL AWS Glue que se ejecutan en el sistema de trabajos AWS Glue, así como aplicaciones de Spark que se ejecutan en puntos de enlace de desarrollo AWS Glue. La interfaz de usuario de Spark le permite comprobar lo siguiente para cada trabajo:
-
La escala de tiempo del evento de cada etapa de Spark
-
Un gráfico acíclico dirigido (DAG) del trabajo
-
Planes físicos y lógicos para consultas de SparkSQL
-
Las variables de entorno de Spark subyacentes para cada trabajo
Para obtener más información sobre el uso de la interfaz de usuario web de Spark, consulta la Interfaz de usuario web
Puede ver la interfaz de usuario de Spark en la consola de AWS Glue. Está disponible cuando un trabajo de AWS Glue se ejecuta en la versión 3.0 o versiones posteriores de AWS Glue y los registros se generan en el formato estándar (en lugar del heredado), que es el predeterminado para los trabajos más recientes. Si tiene archivos de registro de más de 0,5 GB, puede activar la compatibilidad con el registro continuo para las ejecuciones de trabajos en la versión 4.0 o versiones posteriores de AWS Glue para simplificar el archivado de registros, el análisis y la solución de problemas.
Puede habilitar la interfaz de usuario de Spark mediante la consola de AWS Glue o la AWS Command Line Interface (AWS CLI). Al habilitar la interfaz de usuario de Spark, los trabajos de ETL de AWS Glue y las aplicaciones de Spark en puntos de conexión de desarrollo de AWS Glue pueden hacer una copia de seguridad de los registros de eventos de Spark en una ubicación que especifique en Amazon Simple Storage Service (Amazon S3). Los registros de eventos respaldados en Amazon S3 se pueden utilizar con la interfaz de usuario de Spark tanto en tiempo real mientras se está ejecutando el trabajo como después de que se haya completado el trabajo. Mientras los registros permanezcan en Amazon S3, la interfaz de usuario de Spark de la consola de AWS Glue puede verlos.
Permisos
Para utilizar la interfaz de usuario de Spark en la consola de AWS Glue, puede utilizar UseGlueStudio o agregar todas las API de servicios individuales. Para utilizar la interfaz de Spark, todas las API son necesarias; sin embargo, los usuarios pueden acceder a las características de la interfaz de Spark al agregar sus API de servicio en el permiso de IAM para un acceso detallado.
RequestLogParsing es la más importante, ya que realiza el análisis de los registros. Las API restantes realizan la lectura de los respectivos datos analizados. Por ejemplo, GetStages brinda acceso a los datos sobre las etapas de un trabajo de Spark.
La lista de las API de servicio de la interfaz de usuario de Spark elaboradas para UseGlueStudio se encuentra a continuación, en la política de muestra. La política a continuación brinda acceso para que solo se utilicen las características de la interfaz de Spark. Para agregar más permisos, como Amazon S3 e IAM, consulte Creación de políticas de IAM personalizadas para AWS Glue Studio.
La lista de las API de servicio de la interfaz de usuario de Spark elaboradas para UseGlueStudio se encuentra a continuación, en la política de muestra. Al utilizar una API de servicio de la interfaz de Spark, utilice el espacio de nombre glue:<ServiceAPI>.
Limitaciones
-
La interfaz de usuario de Spark en la consola de AWS Glue no está disponible para los trabajos ejecutados antes del 20 de noviembre de 2023, ya que están en el formato de registro heredado.
-
La interfaz de usuario de Spark en la consola de AWS Glue admite los registros continuos de la versión 4.0 de AWS Glue, como los que se generan de forma predeterminada en los trabajos de streaming. La suma máxima de todos los archivos de eventos de registro continuo generados es de 2 GB. Para los trabajos de AWS Glue que no admiten registros continuos, el tamaño máximo del archivo de eventos de registro que admite SparkUI es de 0,5 GB.
-
La interfaz de usuario de Spark sin servidor no está disponible para los registros de eventos de Spark almacenados en un bucket de Amazon S3 al que solo puede acceder su VPC.
Ejemplo: interfaz de usuario web de Apache Spark
Este ejemplo le muestra cómo utilizar la interfaz de usuario de Spark para entender su desempeño laboral. Las capturas de pantalla muestran la interfaz de usuario web de Spark proporcionada por un servidor de historial de Spark autogestionado. La interfaz de usuario de Spark en la consola de AWS Glue ofrece vistas similares. Para obtener más información sobre el uso de la interfaz de usuario web de Spark, consulta la Interfaz de usuario web
A continuación, se muestra un ejemplo de una aplicación Spark que lee desde dos orígenes de datos, realiza una transformación de combinación y la escribe en Amazon S3 en formato Parquet.
import sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job from pyspark.sql.functions import count, when, expr, col, sum, isnull from pyspark.sql.functions import countDistinct from awsglue.dynamicframe import DynamicFrame args = getResolvedOptions(sys.argv, ['JOB_NAME']) sc = SparkContext() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) job.init(args['JOB_NAME']) df_persons = spark.read.json("s3://awsglue-datasets/examples/us-legislators/all/persons.json") df_memberships = spark.read.json("s3://awsglue-datasets/examples/us-legislators/all/memberships.json") df_joined = df_persons.join(df_memberships, df_persons.id == df_memberships.person_id, 'fullouter') df_joined.write.parquet("s3://aws-glue-demo-sparkui/output/") job.commit()
La siguiente visualización del DAG muestra las diferentes etapas de este trabajo de Spark.
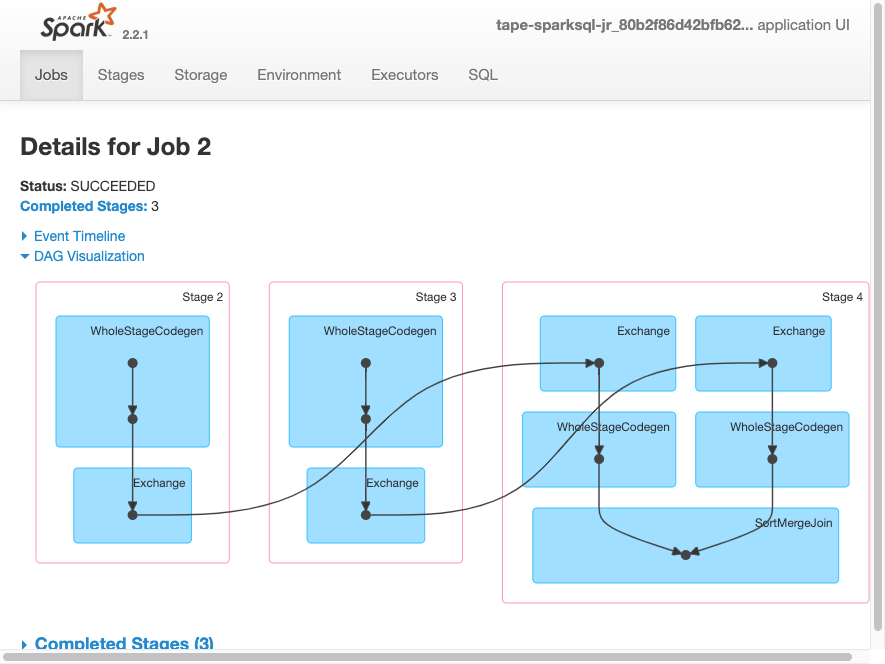
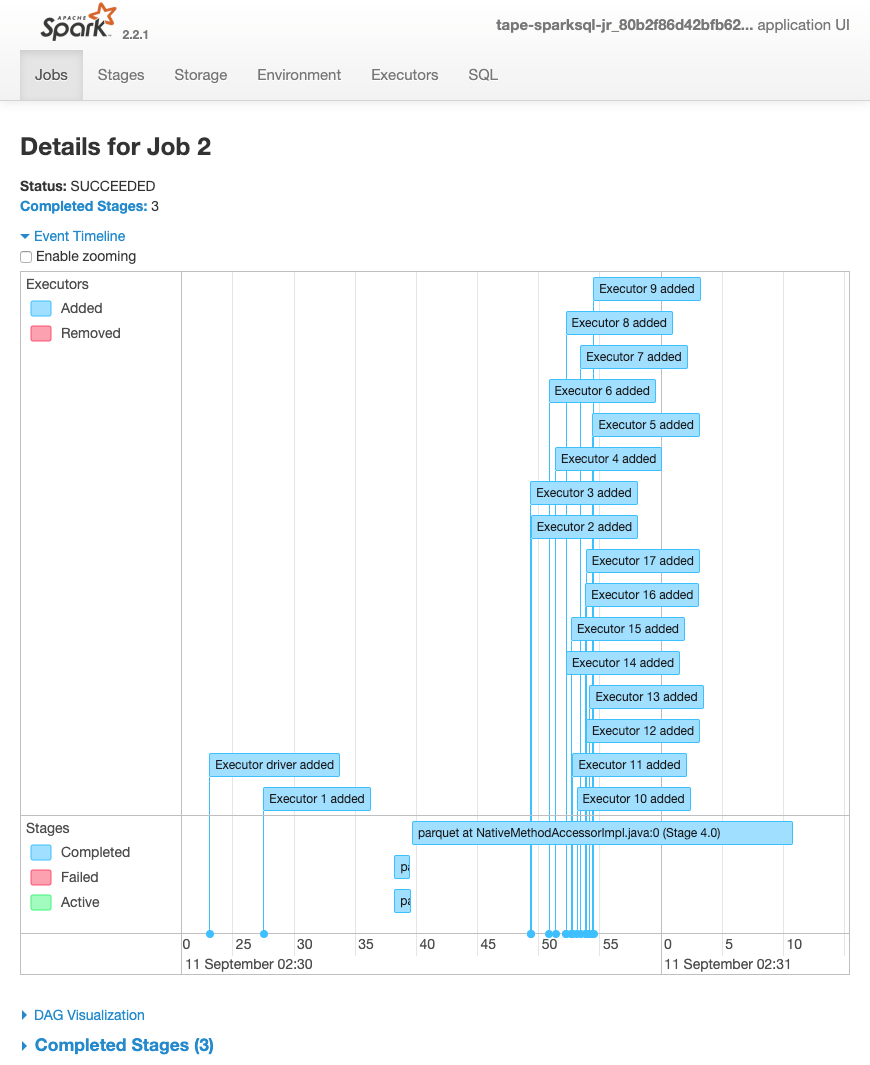
La siguiente escala de tiempo de eventos para un trabajo muestra el inicio, la ejecución y la terminación de diferentes ejecutores de Spark.
En la siguiente pantalla se muestran los detalles de los planes de consulta de SparkSQL:
-
Plan lógico examinado
-
Plan lógico analizado
-
Plan lógico optimizado
-
Plan físico para la ejecución

Temas
