Tutorial: Cree su primera carga de trabajo de transmisión con los cuadernos de AWS Glue Studio
En este tutorial, explorará cómo aprovechar los cuadernos de AWS Glue Studio a fin de crear y refinar de forma interactiva sus trabajos de ETL para el procesamiento de datos casi en tiempo real. Si acaba de empezar a usar AWS Glue o si desea mejorar sus habilidades, esta guía le mostrará el proceso y le permitirá aprovechar todo el potencial de los cuadernos de las sesiones interactivas de AWS Glue.
Con la transmisión de AWS Glue, puede crear trabajos de extracción, transformación y carga (ETL) de transmisión que se ejecuten de forma continua y consuman datos de los orígenes de transmisión como Amazon Kinesis Data Streams, Apache Kafka y Amazon Managed Streaming para Apache Kafka (Amazon MSK).
Requisitos previos
Para seguir este tutorial, necesitará un usuario con permisos de consola de AWS para usar AWS Glue, Amazon Kinesis, Amazon S3, Amazon Athena, AWS CloudFormation, AWS Lambda y Amazon Cognito.
Consumir datos de transmisión desde Amazon Kinesis
Temas
Generación de datos simulados con Kinesis Data Generator
nota
Si ya ha completado la sección anterior Tutorial: Cree su primera carga de trabajo de transmisión con AWS Glue Studio, ya tiene Kinesis Data Generator instalado en su cuenta, por lo que puede omitir los pasos 1 a 8 que aparecen a continuación y pasar a la sección Creación de un trabajo de transmisión de AWS Glue con AWS Glue Studio.
Puede generar sintéticamente datos de muestra en formato JSON mediante Kinesis Data Generator (KDG). Encontrará instrucciones y detalles completos en la documentación de la herramienta
Para empezar, haga clic en

para ejecutar una plantilla de AWS CloudFormation en su entorno de AWS. nota
Es posible que se produzca un error en la plantilla de CloudFormation porque algunos recursos, como el usuario de Amazon Cognito para Kinesis Data Generator, ya existen en su cuenta de AWS. Esto puede deberse a que ya la configuró en otro tutorial o blog. Para solucionar este problema, puede probar la plantilla en una cuenta de AWS nueva para empezar de cero o explorar una región de AWS diferente. Estas opciones le permiten ejecutar el tutorial sin que entre en conflicto con los recursos existentes.
La plantilla aprovisiona un flujo de datos de Kinesis y una cuenta de Kinesis Data Generator.
Introduzca un nombre de usuario y una contraseña que KDG usará para autenticarse. Tome nota del nombre de usuario y la contraseña para su uso posterior.
Seleccione Siguiente hasta el último paso. Acepte la creación de recursos de IAM. Compruebe si hay algún error en la parte superior de la pantalla, como que la contraseña no cumple los requisitos mínimos, e implemente la plantilla.
Navegue hasta la pestaña Salidas de la pila. Una vez implementada la plantilla, mostrará la propiedad generada KinesisDataGeneratorUrl. Haga clic en esa URL.
Ingrese el nombre de usuario y la contraseña que anotó.
Seleccione la región que está usando y elija Kinesis Stream
GlueStreamTest-{AWS::AccountId}.Escriba la siguiente plantilla:
{ "ventilatorid": {{random.number(100)}}, "eventtime": "{{date.now("YYYY-MM-DD HH:mm:ss")}}", "serialnumber": "{{random.uuid}}", "pressurecontrol": {{random.number( { "min":5, "max":30 } )}}, "o2stats": {{random.number( { "min":92, "max":98 } )}}, "minutevolume": {{random.number( { "min":5, "max":8 } )}}, "manufacturer": "{{random.arrayElement( ["3M", "GE","Vyaire", "Getinge"] )}}" }Ahora puede ver los datos simulados con la plantilla de prueba e incorporarlos a Kinesis con Enviar datos.
Haga clic en Enviar datos y genere entre 5 y 10 000 registros en Kinesis.
Creación de un trabajo de transmisión de AWS Glue con AWS Glue Studio
AWS Glue Studio es una interfaz visual que simplifica el proceso de diseño, organización y supervisión de las canalizaciones de integración de datos. Permite a los usuarios crear canalizaciones de transformación de datos sin necesidad de escribir un código extenso. Además de la experiencia visual de creación de trabajos, AWS Glue Studio también incluye un cuaderno de Jupyter respaldado por sesiones interactivas de AWS Glue, que usará en el resto de este tutorial.
Configure el trabajo de sesiones interactivas de la transmisión de AWS Glue
Descargue el archivo del cuaderno
proporcionado y guárdelo en un directorio local. Abra la consola de AWS Glue y, en el panel izquierdo, haga clic en Cuadernos > Cuaderno de Jupyter > Cargar y editar un cuaderno existente. Cargue el cuaderno del paso anterior y haga clic en Crear.
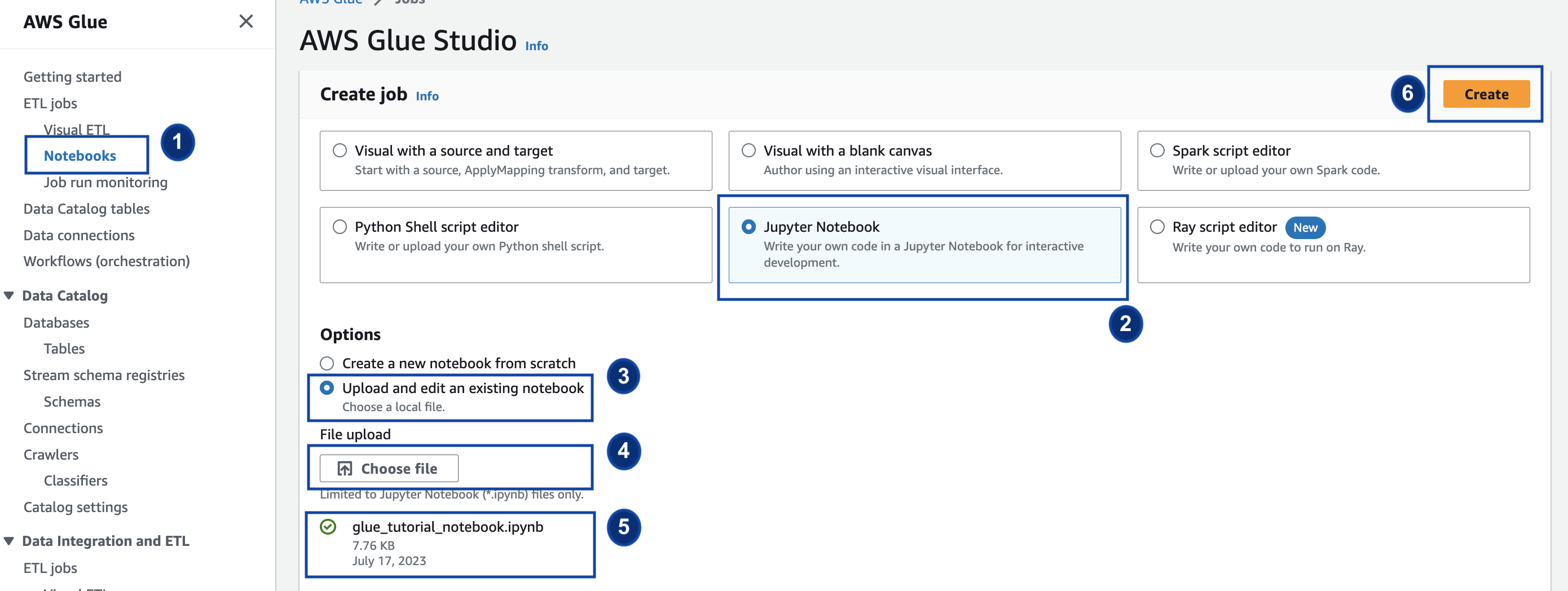
Proporcione un nombre y un rol al trabajo y seleccione el kernel de Spark predeterminado. A continuación, haga clic en Iniciar cuaderno. Para el rol de IAM, seleccione el rol aprovisionado en la plantilla de CloudFormation. Puede verlo en la pestaña Salidas de CloudFormation.
El cuaderno tiene todas las instrucciones necesarias para continuar con el tutorial. Puede ejecutar las instrucciones en el cuaderno o seguir este tutorial para continuar con el desarrollo del trabajo.
Ejecute las celdas del cuaderno
(Opcional) La primera celda de código
%helpmuestra todos los comandos mágicos disponibles del cuaderno. Puede saltarse esta celda por ahora, pero no dude en explorarla.Empiece con el siguiente bloque de código
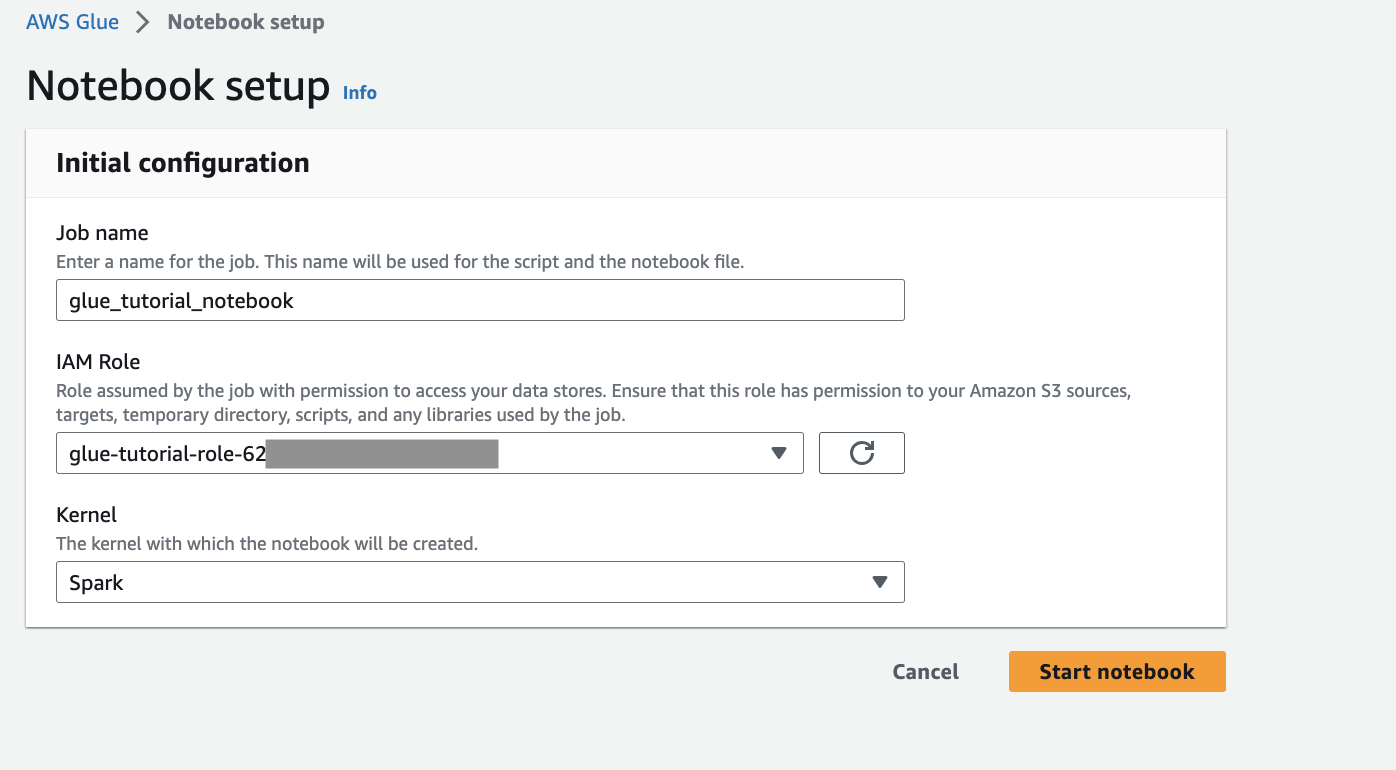
%streaming. Este comando mágico define el tipo de trabajo como transmisión, lo que le permite desarrollar, depurar e implementar un trabajo de ETL de transmisión de AWS Glue.Ejecute la siguiente celda para crear una sesión interactiva de AWS Glue. La celda de salida tiene un mensaje que confirma la creación de la sesión.
La siguiente celda define las variables. Sustituya los valores por otros adecuados para su trabajo y ejecute la celda. Por ejemplo:

Como los datos ya se están transmitiendo a Kinesis Data Streams, la siguiente celda consumirá los resultados del flujo. Ejecute la siguiente celda. Como no hay instrucciones de impresión, no se espera ningún resultado de esta celda.
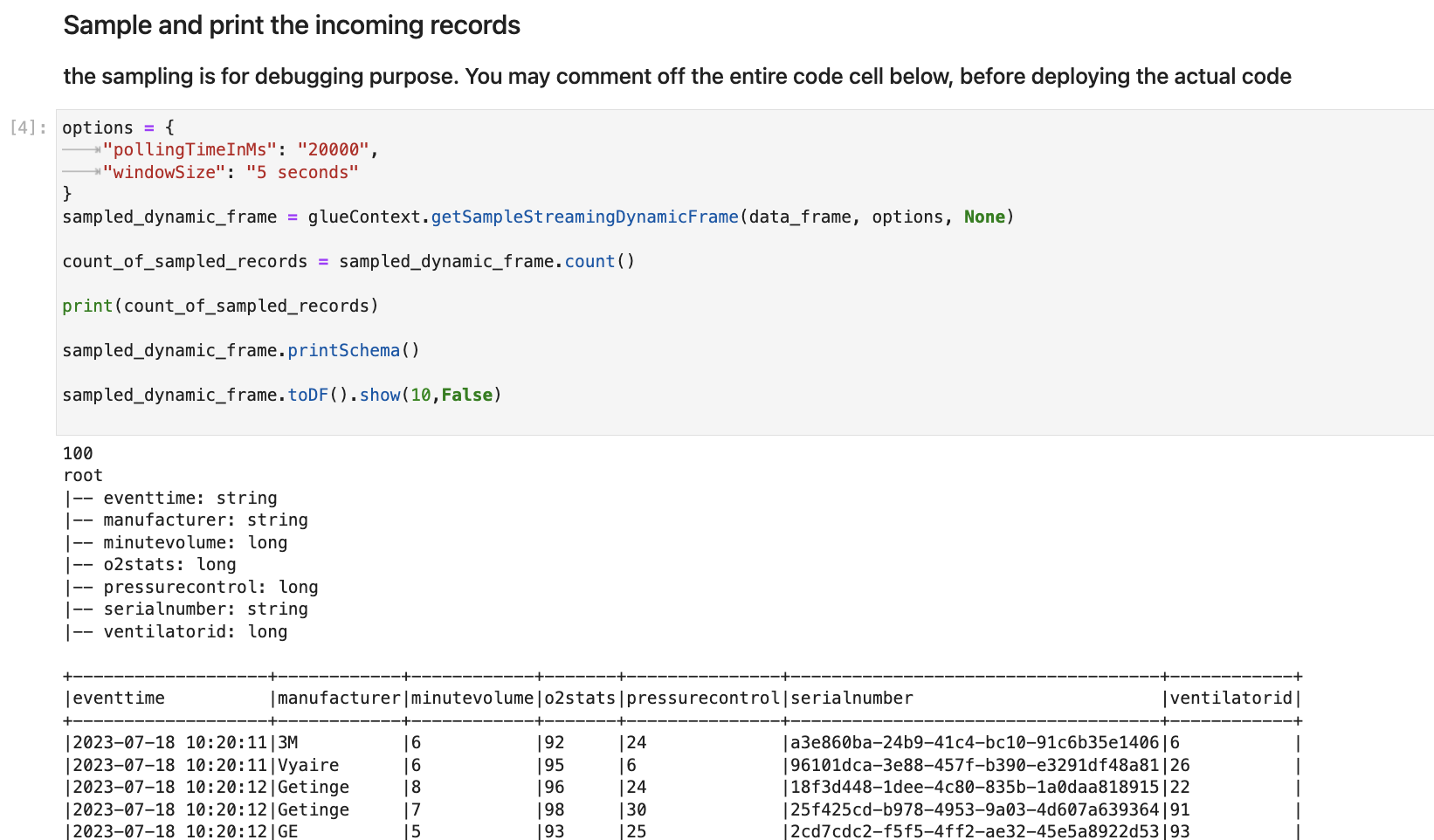
En la siguiente celda, se explora el flujo entrante tomando un conjunto de muestra e imprimiendo su esquema y los datos reales. Por ejemplo:
A continuación, defina la lógica de transformación de datos real. La celda consiste en el método
processBatchque se activa durante cada microlote. Ejecute la celda. En un nivel superior, haga lo siguiente con el flujo entrante:Seleccione un subconjunto de las columnas de entrada.
Cambie el nombre de una columna (o2stats a oxygen_stats).
Derive columnas nuevas (serial_identifier, ingest_year, ingest_month e ingest_day).
Almacene los resultados en un bucket de Amazon S3 y también cree una tabla de catálogo de AWS Glue particionada.
En la última celda, active el proceso por lotes cada 10 segundos. Ejecute la celda y espere unos 30 segundos para que llene el bucket de Amazon S3 y la tabla del catálogo de AWS Glue.
Por último, explore los datos almacenados con el editor de consultas de Amazon Athena. Puede ver la columna a la que se le ha cambiado el nombre y también las nuevas particiones.
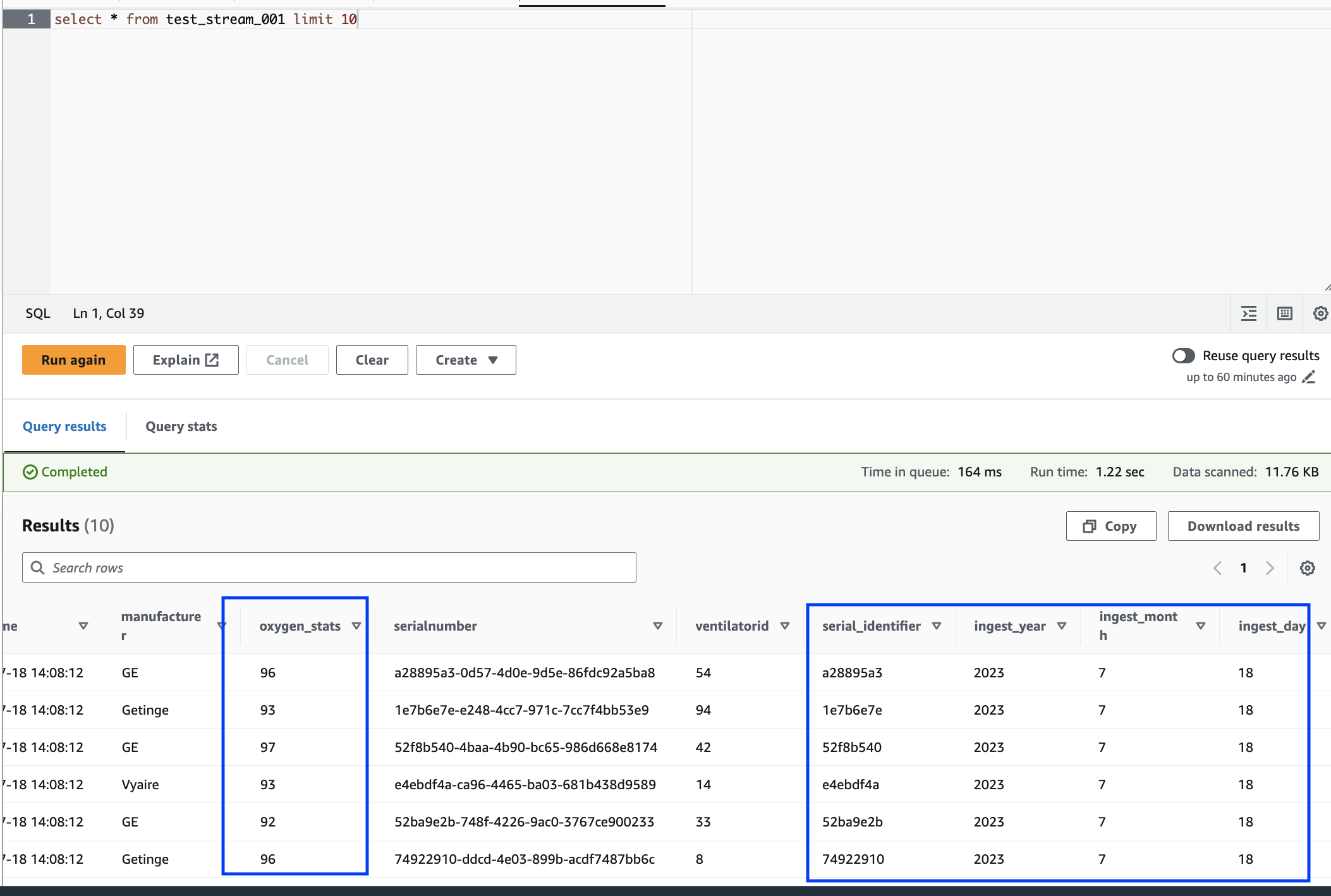
El cuaderno tiene todas las instrucciones necesarias para continuar con el tutorial. Puede ejecutar las instrucciones en el cuaderno o seguir este tutorial para continuar con el desarrollo del trabajo.
Guarde y ejecute el trabajo de AWS Glue
Una vez que haya completado el desarrollo y las pruebas de su aplicación con el cuaderno de sesiones interactivas, haga clic en Guardar en la parte superior de la interfaz del cuaderno. Una vez guardado, también puede ejecutar la aplicación como un trabajo.

Limpieza
Para evitar incurrir en cargos adicionales en su cuenta, detenga el trabajo de transmisión que inició siguiendo las instrucciones. Puede hacerlo cerrando el cuaderno, lo que finalizará la sesión. Vacíe el bucket de Amazon S3 y elimine la pila de AWS CloudFormation que aprovisionó anteriormente.
Conclusión
En este tutorial, mostramos cómo usar el cuaderno de AWS Glue Studio para hacer lo siguiente:
Crear un trabajo de ETL de transmisión con cuadernos
Previsualizar los flujos de datos entrantes
Codificar y solucionar problemas sin tener que publicar los trabajos de AWS Glue
Revisar el código de trabajo de principio a fin, eliminar cualquier error e imprimir las instrucciones o celdas del cuaderno
Publicar el código como un trabajo de AWS Glue
El objetivo de este tutorial es proporcionarle experiencia práctica al trabajar con la transmisión de AWS Glue y las sesiones interactivas. Le recomendamos que lo use como referencia para sus casos de uso individuales de transmisión de AWS Glue. Para obtener más información, consulte Introducción a las sesiones interactivas de AWS Glue.
