Uso de la transformación de Procesamiento de autobalance para optimizar el tiempo de ejecución
La transformación de Procesamiento de autobalance redistribuye los datos entre los trabajadores para mejorar el rendimiento. Esto ayuda en los casos en que los datos están desequilibrados o, tal como provienen del origen, no permiten un procesamiento paralelo suficiente. Esto es común cuando el origen está comprimido con gzip o es JDBC. La redistribución de los datos tiene un costo de rendimiento modesto, por lo que es posible que la optimización no siempre compense ese esfuerzo si los datos ya estaban bien equilibrados. En la imagen inferior, la transformación utiliza la repartición de Apache Spark para reasignar datos de forma aleatoria entre un número de particiones óptimo para la capacidad del clúster. Para los usuarios avanzados, es posible ingresar varias particiones de forma manual. Además, se puede utilizar para optimizar la escritura de tablas particionadas al reorganizar los datos en función de columnas específicas. Esto da como resultado archivos de salida más consolidados.
-
Abra el panel de recursos y, a continuación, elija Procesamiento de autobalance para agregar una nueva transformación al diagrama de trabajo. El nodo seleccionado en el momento de agregar el nodo será el nodo principal.
-
(Opcional) En la pestaña Propiedades del nodo, puede ingresar un nombre para el nodo en el diagrama de trabajo. Si todavía no se ha seleccionado un nodo principal, elija un nodo de la lista Nodos principales para utilizar como origen de entrada para la transformación.
-
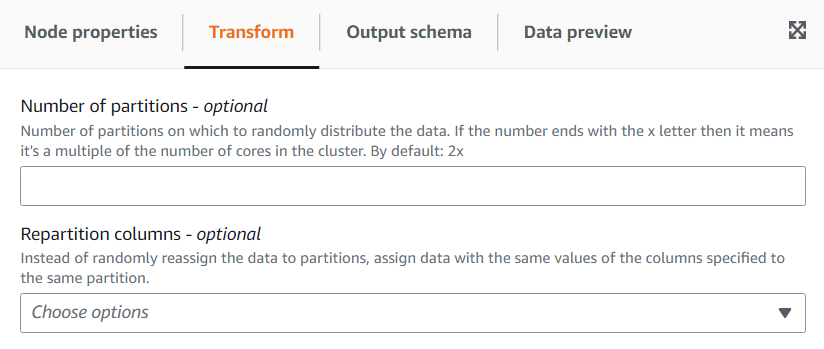
(Opcional) En la pestaña Transformación, puede ingresar varias particiones. En general, se recomienda dejar que el sistema decida este valor; sin embargo, puede ajustar el multiplicador o ingresar un valor específico si necesita controlarlo. Si va a guardar los datos particionados por columnas, puede elegir las mismas columnas como columnas de repartición. De esta forma, minimizará la cantidad de archivos en cada partición y evitará tener muchos archivos por partición, lo que dificultaría el rendimiento de las herramientas que consultan esos datos.