Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Generador de códigos de modelos de datos
Aprenda a usar el generador de código para el modelo de datos. El código generado se puede utilizar para serializar y deserializar los modelos de datos que se intercambian entre la nube y el dispositivo.
El repositorio del proyecto contiene una herramienta de generación de código para crear controladores de modelos de datos de código C. En los temas siguientes se describe el generador de código y el flujo de trabajo.
Proceso de generación de código
El generador de código crea archivos fuente en C a partir de tres entradas principales: AWS la implementación del Matter Data Model (archivo.matter) de la plataforma avanzada Zigbee Cluster Library (ZCL), un complemento de Python que gestiona el preprocesamiento y las plantillas Jinja2 que definen la estructura del código. Durante la generación, el complemento de Python procesa los archivos.matter añadiendo definiciones de tipos globales, organizando los tipos de datos en función de sus dependencias y formateando la información para la representación de plantillas.
La siguiente imagen describe el generador de código que crea los archivos fuente en C.
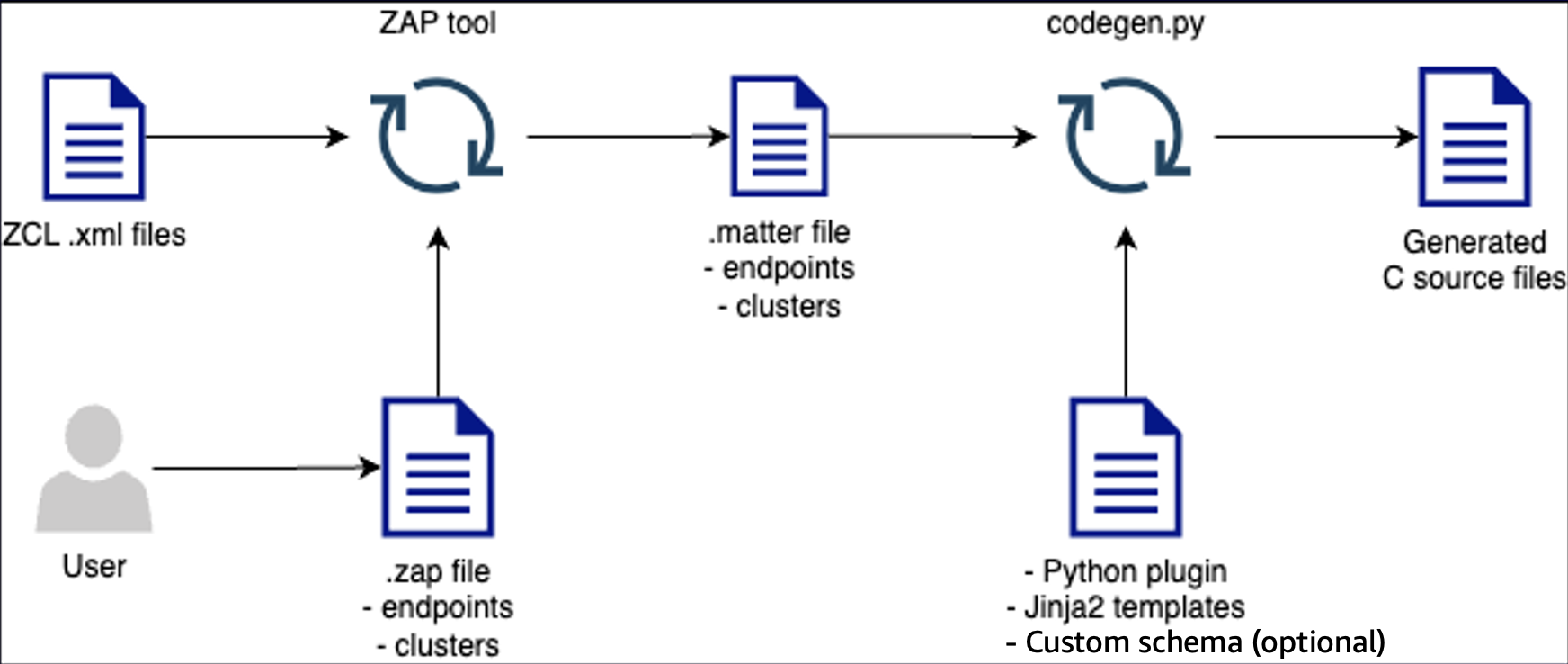
El SDK para dispositivos finales incluye complementos de Python y plantillas de Jinja2 que funcionan codegen.py
En los siguientes subtemas se describen estos archivos.
Complemento de Python
El generador de código analiza los archivos.matter y envía la información como objetos de Python al complemento. codegen.py El archivo del complemento iotmi_data_model.py preprocesa estos datos y representa las fuentes con las plantillas proporcionadas. El preprocesamiento incluye:
-
Agregar información que no está disponible en
codegen.py, como los tipos globales -
Realizar una ordenación topológica de los tipos de datos para establecer el orden de definición correcto
nota
La ordenación topológica garantiza que los tipos dependientes se definan después de sus dependencias, independientemente de su orden original.
Plantillas Jinja2
El SDK para dispositivos finales proporciona plantillas Jinja2 diseñadas para gestores de modelos de datos y funciones C de bajo nivel.
| Plantilla | Fuente generada | Observaciones |
|---|---|---|
cluster.h.jinja |
iotmi_device_<cluster>.h |
Crea archivos de encabezado de funciones C de bajo nivel. |
cluster.c.jinja |
iotmi_device_<cluster>.c |
Implemente y registre los punteros de las funciones de devolución de llamada con el controlador del modelo de datos. |
cluster_type_helpers.h.jinja |
iotmi_device_type_helpers_<cluster>.h |
Define prototipos de funciones para los tipos de datos. |
cluster_type_helpers.c.jinja |
iotmi_device_type_helpers_<cluster>.c |
Genera prototipos de funciones de tipos de datos para enumeraciones, mapas de bits, listas y estructuras específicas de clústeres. |
iot_device_dm_types.h.jinja |
iotmi_device_dm_types.h |
Define los tipos de datos C para los tipos de datos globales. |
iot_device_type_helpers_global.h.jinja |
iotmi_device_type_helpers_global.h |
Define los tipos de datos C para las operaciones globales. |
iot_device_type_helpers_global.c.jinja |
iotmi_device_type_helpers_global.c |
Declara los tipos de datos estándar, incluidos los booleanos, los enteros, los puntos flotantes, las cadenas, los mapas de bits, las listas y las estructuras. |
(Opcional) Esquema personalizado
El SDK para dispositivos finales combina el proceso de generación de código estandarizado con un esquema personalizado. Esto permite extender el modelo de datos de materia a sus dispositivos y al software de sus dispositivos. Los esquemas personalizados pueden ayudar a describir las capacidades de device-to-cloud comunicación del dispositivo.
Para obtener información detallada sobre los modelos de datos de integraciones gestionadas, incluidos el formato, la estructura y los requisitos, consulte. Modelo de datos de integraciones gestionadas
Utilice la codegen.py herramienta para generar archivos fuente en C para un esquema personalizado, de la siguiente manera:
nota
Cada clúster personalizado requiere el mismo ID de clúster para los tres archivos siguientes.
-
Cree un esquema personalizado en un
JSONformato que proporcione una representación de los clústeres para generar informes de capacidad a fin de crear nuevos clústeres personalizados en la nube. Encontrará un archivo de muestra encodegen/custom_schemas/custom.SimpleLighting@1.0. -
Cree un archivo de definición de ZCL (biblioteca de clústeres de Zigbee) en un
XMLformato que contenga la misma información que el esquema personalizado. Utilice la herramienta ZAP para generar sus archivos Matter IDL a partir de ZCL XML. Encontrará un archivo de muestra en.codegen/zcl/custom.SimpleLighting.xml -
El resultado de la herramienta ZAP es
Matter IDL File (.matter)y define los clústeres de materias correspondientes a su esquema personalizado. Esta es la entrada de lacodegen.pyherramienta para generar archivos fuente en C para el SDK de dispositivos finales. Encontrará un archivo de muestra encodegen/matter_files/custom-light.matter.
Para obtener instrucciones detalladas sobre cómo integrar modelos de datos de integraciones gestionadas personalizadas en su flujo de trabajo de generación de código, consulteGenera código para dispositivos.
