Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Proceso de migración sin conexión: de Apache Cassandra a Amazon Keyspaces
Las migraciones sin conexión son adecuadas cuando se pueda permitir un tiempo de inactividad para llevarlas a cabo. Es habitual que las empresas tengan períodos de mantenimiento para la aplicación de parches o lanzamientos de gran tamaño, o tiempos de inactividad para llevar a cabo actualizaciones de hardware o cambios principales. La migración sin conexión puede aprovechar estos periodos para copiar datos y transferir el tráfico de aplicaciones de Apache Cassandra a Amazon Keyspaces.
La migración sin conexión reduce las modificaciones en la aplicación porque no requiere la comunicación simultánea con Cassandra y Amazon Keyspaces. Además, dado que el flujo de datos está pausado, se puede copiar el estado exacto sin mantener las mutaciones.
En este ejemplo, utilizamos Amazon Simple Storage Service (Amazon S3) como espacio provisional para los datos durante la migración sin conexión con el objetivo de minimizar el tiempo de inactividad. Puede importar automáticamente los datos que ha almacenado en formato Parquet en Amazon S3 a una tabla de Amazon Keyspaces mediante Spark Cassandra Connector y AWS Glue. En la siguiente sección se mostrará información general de alto nivel del proceso. Puede encontrar ejemplos de código para este proceso en Github
El proceso de migración sin conexión de Apache Cassandra a Amazon Keyspaces mediante Amazon S3 requiere AWS Glue los AWS Glue siguientes trabajos.
Un trabajo ETL que extraiga y transforme los datos de CQL y los almacena en un bucket de Amazon S3.
Un segundo trabajo que importe los datos del bucket a Amazon Keyspaces.
Un tercer trabajo que importe datos incrementales.
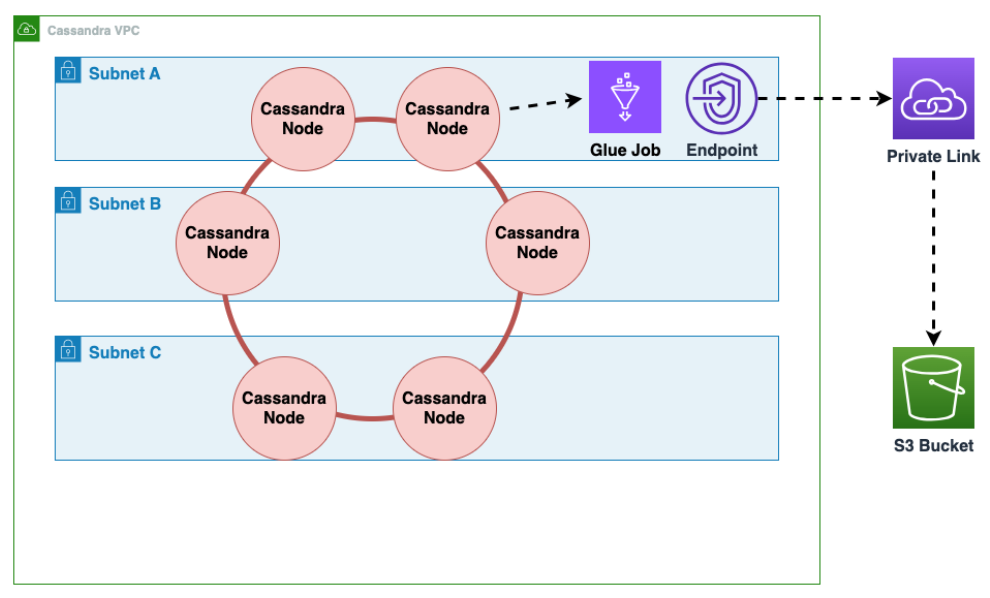
Cómo realizar una migración offline a Amazon Keyspaces desde Cassandra que se ejecuta en Amazon EC2 en una Amazon Virtual Private Cloud
Primero se exportan AWS Glue los datos de las tablas de Cassandra en formato Parquet y se guardan en un bucket de Amazon S3. Debe ejecutar un AWS Glue trabajo mediante un AWS Glue conector a una VPC en la que resida la EC2 instancia de Amazon que ejecuta Cassandra. A continuación, con el punto de conexión privado de Amazon S3, puede guardar los datos en el bucket de Amazon S3.
En el siguiente diagrama se muestran estos pasos.
Mezcla de los datos en el bucket de Amazon S3 para mejorar la asignación al azar de los datos. Los datos importados de manera uniforme permiten distribuir más el tráfico en la tabla de destino.
Este paso es obligatorio cuando se exportan datos de Cassandra con particiones grandes (particiones con más de 1000 filas) para evitar patrones de claves sobrecargadas al insertar los datos en Amazon Keyspaces. Los problemas por claves sobrecargadas provocan
WriteThrottleEventsen Amazon Keyspaces y causan un aumento del tiempo de carga.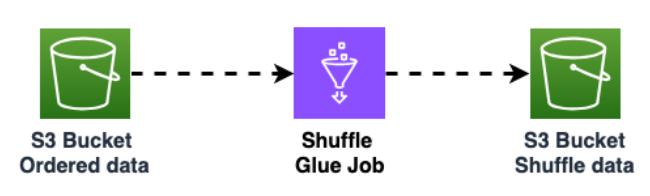
Utilice otro AWS Glue trabajo para importar datos del bucket de Amazon S3 a Amazon Keyspaces. Los datos mezclados en el bucket de Amazon S3 se almacenan en formato Parquet.
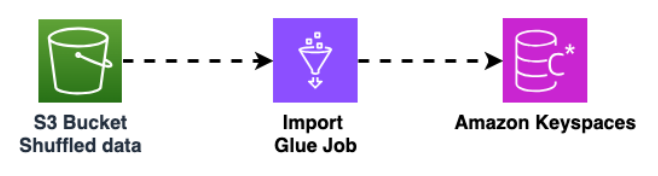
Para obtener más información sobre el proceso de migración fuera de línea, consulte el taller Amazon Keyspaces with AWS Glue
