Tras considerarlo detenidamente, hemos decidido retirar las aplicaciones de Amazon Kinesis Data Analytics para SQL en dos pasos:
1. A partir del 15 de octubre de 2025, no podrá crear nuevas aplicaciones de Kinesis Data Analytics para SQL.
2. Eliminaremos sus aplicaciones a partir del 27 de enero de 2026. No podrá iniciar ni utilizar sus aplicaciones de Amazon Kinesis Data Analytics para SQL. A partir de ese momento, el servicio de soporte de Amazon Kinesis Data Analytics para SQL dejará de estar disponible. Para obtener más información, consulte Retirada de las aplicaciones de Amazon Kinesis Data Analytics para SQL.
Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Paso 2: Cree una aplicación
En esta sección va a crear una aplicación de análisis de datos de Amazon Kinesis Data Analytics de la siguiente manera:
-
Configure la entrada de la aplicación para que utilice el flujo de datos de Kinesis que ha creado en Paso 1: Preparación como origen de streaming.
-
Utilice la plantilla Anomaly Detection (Detección de anomalías) en la consola.
Para crear una aplicación
-
Siga los pasos 1, 2 y 3 del ejercicio de Introducción a Kinesis Data Analytics (consulte Paso 3.1: Cree una aplicación).
-
En la configuración fuente, haga lo siguiente:
-
Especifique el origen de streaming que ha creado en la sección anterior.
-
Después de que la consola infiera el esquema, edite este y establezca el tipo de columna de
heartRateenINTEGER.La mayor parte de los valores de la frecuencia cardíaca son normales y el proceso de detección probablemente asignará el tipo
TINYINTa esta columna. Pero un pequeño porcentaje de valores muestran una frecuencia cardíaca alta. Si estos valores no encajan en el tipoTINYINT, Kinesis Data Analytics envía estas filas a una secuencia de errores. Actualice el tipo de datos aINTEGERpara que pueda adaptarse a todos los datos de frecuencia cardíaca que se han generado.
-
-
Utilice la plantilla Anomaly Detection (Detección de anomalías) en la consola. A continuación, actualice el código de la plantilla para proporcionar el nombre de columna apropiado.
-
-
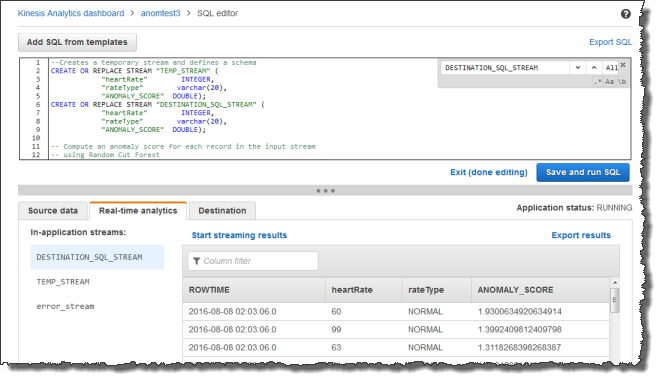
Actualice el código de la aplicación al proporcionar los nombres de columnas. El código de la aplicación resultante se muestra a continuación (pegue este código en el editor de SQL):
--Creates a temporary stream. CREATE OR REPLACE STREAM "TEMP_STREAM" ( "heartRate" INTEGER, "rateType" varchar(20), "ANOMALY_SCORE" DOUBLE); --Creates another stream for application output. CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" ( "heartRate" INTEGER, "rateType" varchar(20), "ANOMALY_SCORE" DOUBLE); -- Compute an anomaly score for each record in the input stream -- using Random Cut Forest CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "TEMP_STREAM" SELECT STREAM "heartRate", "rateType", ANOMALY_SCORE FROM TABLE(RANDOM_CUT_FOREST( CURSOR(SELECT STREAM * FROM "SOURCE_SQL_STREAM_001"))); -- Sort records by descending anomaly score, insert into output stream CREATE OR REPLACE PUMP "OUTPUT_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" SELECT STREAM * FROM "TEMP_STREAM" ORDER BY FLOOR("TEMP_STREAM".ROWTIME TO SECOND), ANOMALY_SCORE DESC; -
Ejecute el código SQL y revise los resultados en la consola de Kinesis Data Analytics:
Paso siguiente
Paso 3: Configurar la salida de la aplicación
