Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Administración de los permisos de los conjuntos de datos que utilizan metaalmacenes externos
Con la federación de AWS Glue Data Catalog metadatos (federación de catálogos de datos), puede conectar el catálogo de datos a metaalmacenes externos que almacenan los metadatos de sus datos de Amazon S3 y gestionar de forma segura los permisos de acceso a los datos mediante AWS Lake Formation. No tiene que migrar los metadatos del metaalmacén externo al Catálogo de datos.
El Catálogo de datos proporciona un repositorio de metadatos centralizado que facilita la administración y la detección de datos en sistemas dispares. Cuando su organización administra los datos del catálogo de datos, puede utilizarlos AWS Lake Formation para controlar el acceso a sus conjuntos de datos en Amazon S3.
nota
Actualmente, solo admitimos la federación de metaalmacenes Hive de Apache (versión 3 y superior).
Para configurar la federación del catálogo de datos, proporcionamos una aplicación AWS Serverless Application Model (AWS SAM) llamada GlueDataCatalogFederation- HiveMetastore
La implementación de referencia se proporciona GitHub como un proyecto de código abierto en AWS Glue Data Catalog Federation - Hive Metastore
La AWS SAM aplicación crea e implementa los siguientes recursos necesarios para conectar el catálogo de datos al metaalmacén de Hive:
Una AWS Lambda función: aloja la implementación del servicio de federación que se comunica entre el catálogo de datos y el metaalmacén de Hive. AWS Glue invoca esta función Lambda para recuperar objetos de metadatos del metabastore de Hive.
Amazon API Gateway: el punto de conexión del metaalmacén de Hive que actúa como proxy para enrutar todas las invocaciones a la función de Lambda.
Un rol de IAM: un rol con los permisos necesarios para crear la conexión entre el Catálogo de datos y el metaalmacén de Hive.
AWS Glue conexión: Amazon API Gateway tipo de AWS Glue conexión que almacena el Amazon API Gateway punto final y una función de IAM para invocarlo.
Al consultar tablas, el AWS Glue servicio realiza una llamada en tiempo de ejecución al metabastore de Hive y recupera los metadatos. La función de Lambda actúa como un traductor entre el metaalmacén de Hive y el Catálogo de datos.
Tras establecer la conexión, para sincronizar los metadatos del metaalmacén de Hive con el Catálogo de datos, debe crear una base de datos federada en el Catálogo de datos utilizando los detalles de conexión del metaalmacén de Hive y asignar esta base de datos a la base de datos de Hive. Una base de datos se denomina base de datos federada cuando apunta a una entidad ajena al Catálogo de datos.
Puede aplicar los permisos de Lake Formation mediante el control de acceso basado en etiquetas y el método de recurso con nombre en la base de datos federada, y compartirlos entre varias Cuentas de AWS unidades organizativas y ()OUs. AWS Organizations También puede compartir la base de datos federada directamente con las entidades principales de IAM desde otra cuenta.
Puede definir permisos específicos de columna, fila y celda utilizando los filtros de datos de Lake Formation en tablas de Hive externas. Puede usar Amazon Athena, Amazon Redshift o Amazon EMR para consultar las tablas de Hive externas administradas por Lake Formation.
Para obtener más información sobre el filtrado y el intercambio de datos entre cuentas, consulte:
Pasos básicos de la federación de metadatos del Catálogo de datos
-
Los usuarios y roles de IAM se crean con los permisos adecuados para implementar la aplicación de AWS SAM y crear bases de datos federadas.
-
Para registrar la ubicación de datos de Amazon S3 en Lake Formation, debe seleccionar la opción
Enable Data Catalog federationpara los conjuntos de datos que utilizan un metaalmacén de Hive externo. Debe configurar los ajustes de la AWS SAM aplicación (nombre de la AWS Glue conexión, URL al metabastore de Hive y parámetros de la función Lambda) e implementar la aplicación. AWS SAM
-
La AWS SAM aplicación despliega los recursos necesarios para conectar el metabastore externo de Hive con el catálogo de datos.
-
Para aplicar los permisos de Lake Formation en la base de datos y las tablas de Hive, crea una base de datos en el Catálogo de datos utilizando los datos de conexión del metaalmacén de Hive y asigna esta base de datos a la base de datos de Hive.
Conceda permisos en las bases de datos federadas a las entidades principales de su cuenta o de otra cuenta.
nota
Puede conectar el Catálogo de datos a un metaalmacén de Hive externo, crear bases de datos federadas y ejecutar consultas y scripts de ETL en bases de datos y tablas de Hive sin aplicar los permisos de Lake Formation. En el caso de los datos fuente de Amazon S3 que no estén registrados en Lake Formation, el acceso viene determinado por las políticas de permisos y AWS Glue acciones de IAM para Amazon S3.
Para conocer las limitaciones, consulte Consideraciones y limitaciones del uso compartido de datos del almacén de metadatos de Hive.
Temas
Flujo de trabajo
En el siguiente diagrama se muestra el flujo de trabajo para conectarlo AWS Glue Data Catalog a un metaalmacén de Hive externo.
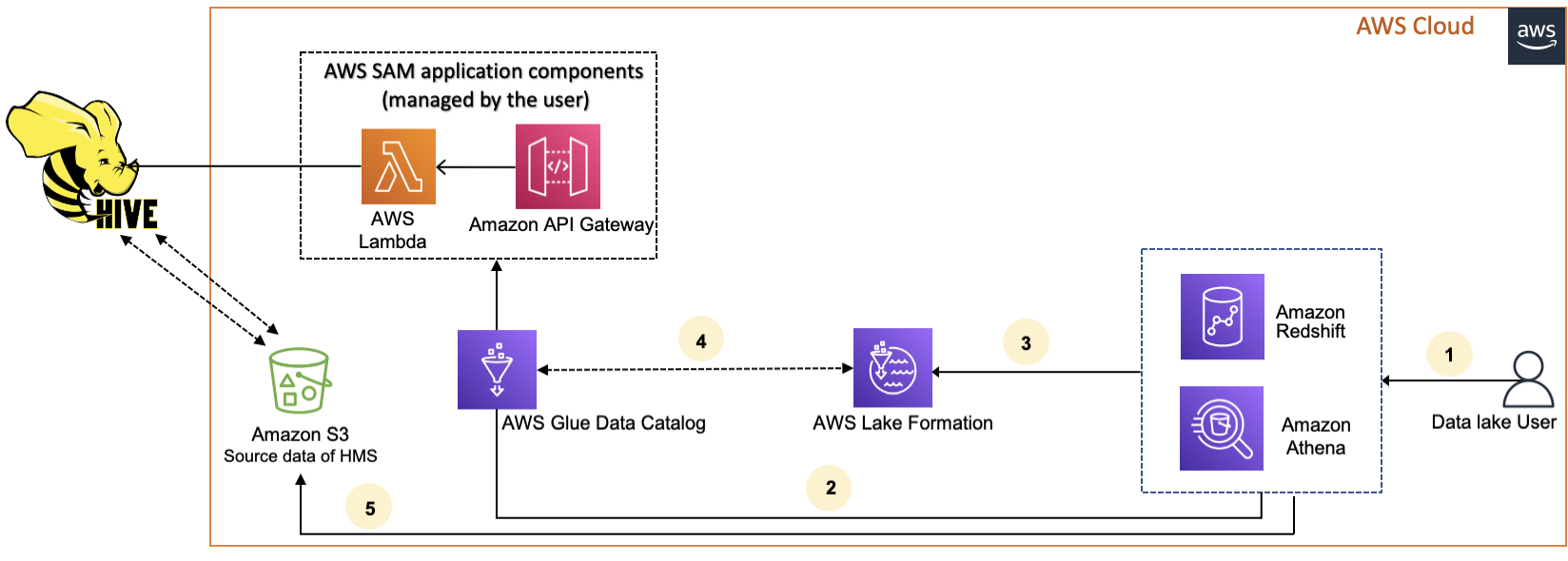
-
Una entidad principal envía una consulta mediante un servicio integrado como Athena o Redshift Spectrum.
El servicio integrado realiza una llamada al catálogo de datos para obtener los metadatos, que a su vez llama al punto final del metaalmacén de Hive disponible en la versión trasera Amazon API Gateway y recibe las respuestas a las solicitudes de metadatos.
-
El servicio integrado envía la solicitud a Lake Formation para verificar la información de la tabla y las credenciales para acceder a la tabla.
-
Lake Formation autoriza la solicitud y suministra credenciales temporales a la aplicación integrada, que permite el acceso a los datos.
Con las credenciales temporales recibidas de Lake Formation, el servicio integrado lee los datos de Amazon S3 y comparte los resultados con la entidad principal.
