Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Supervise el rendimiento de las instancias de Lightsail con métricas
Tras lanzar una instancia en Amazon Lightsail, puede ver sus gráficos de métricas en la pestaña Métricas de la página de administración de la instancia. La monitorización de métricas es una parte importante del mantenimiento de la fiabilidad, la disponibilidad y el desempeño de sus recursos. Supervise y recopile datos de métricas de sus recursos con regularidad para que pueda depurar con mayor facilidad un error de múltiples puntos, si ocurre alguno. Para obtener más información sobre las métricas, consulte Métricas en Amazon Lightsail.
Al supervisar los recursos, debe establecer una línea basal para el rendimiento normal de los recursos en su entorno. A continuación, puede configurar alarmas en la consola de Lightsail para que le notifiquen cuando sus recursos estén funcionando fuera de los umbrales especificados. Para obtener más información, consulte Notificaciones y Alarmas.
Contenido
Métricas de instancia disponibles
Las siguientes métricas de instancias están disponibles:
-
Uso de la CPU (
CPUUtilization): porcentaje de unidades de computación asignadas que están actualmente en uso en la instancia. Esta métrica identifica la potencia de procesamiento para ejecutar las aplicaciones en la instancia. Las herramientas de su sistema operativo pueden mostrar un porcentaje inferior al de Lightsail cuando la instancia no tiene asignado un núcleo de procesador completo.Al ver los gráficos de métricas de uso de la CPU de sus instancias en la consola Lightsail, verá zonas sostenibles y con capacidad de ráfaga. Para obtener más información acerca de lo que significan estas zonas, consulte Zonas sostenibles y con ráfagas de utilización de CPU.
-
Capacidad de ampliación en minutos (
BurstCapacityTime) y porcentaje (BurstCapacityPercentage): los minutos de capacidad de ampliación representan la cantidad de tiempo disponible para que la instancia se amplíe al 100 % de uso de la CPU. El porcentaje de capacidad de ampliación es el porcentaje de rendimiento de la CPU disponible para su instancia. La instancia consume y acumula capacidad de ráfaga continuamente. Los minutos de capacidad de ampliación se consumen plenamente solo cuando la instancia funciona con una utilización de la CPU del 100 %. Para obtener más información acerca de la capacidad de ampliación de la instancia, consulte Visualización de la capacidad de ampliación de una instancia. -
Tráfico de red entrante (
NetworkIn): número de bytes que la instancia recibe en todas las interfaces de red. Esta métrica identifica el volumen de tráfico de red entrante de la instancia. El número registrado es el número de bytes recibidos durante el periodo. Dado que esta métrica se notifica en intervalos de 5 minutos, divida el número notificado por 300 para buscar bytes/segundo. -
Tráfico de red saliente (
NetworkOut): número de bytes que la instancia envía en todas las interfaces de red. Esta métrica identifica el volumen de tráfico de red saliente de la instancia. El número registrado es el número de bytes enviados durante el periodo. Dado que esta métrica se notifica en intervalos de 5 minutos, divida el número notificado por 300 para buscar bytes/segundo. -
Errores de verificación de estado (
StatusCheckFailed): indica si la instancia ha superado o no tanto la comprobación de su estado como la comprobación de estado del sistema. Esta métrica puede ser 0 (superada) o 1 (no superada). Esta métrica está disponible con una frecuencia de 1 minuto. -
Errores de verificación del estado de la instancia (
StatusCheckFailed_Instance): indica si la instancia ha superado o no la comprobación de su estado. Esta métrica puede ser 0 (superada) o 1 (no superada). Esta métrica está disponible con una frecuencia de 1 minuto. -
Errores de verificación del estado de sistema (
StatusCheckFailed_System): indica si la instancia ha superado o no la comprobación de estado del sistema. Esta métrica puede ser 0 (superada) o 1 (no superada). Esta métrica está disponible con una frecuencia de 1 minuto. -
No hay solicitudes de metadatos de tokens (
MetadataNoToken): el número de veces que se ha accedido correctamente al servicio de metadatos de instancia sin un token. Esta métrica determina si hay procesos que acceden a metadatos de instancia mediante el servicio de metadatos de instancia versión 1, el cual no usa un token. Si todas las solicitudes usan sesiones basadas en token, como por ejemplo el servicio de metadatos de instancia versión 2, el valor es 0. Para obtener más información, consulte Metadatos de instancia y datos de usuario.
Zonas sostenibles y ráfagas del uso de la CPU
Lightsail utiliza instancias de ráfaga que proporcionan una cantidad básica de rendimiento de la CPU, pero también tienen la capacidad de proporcionar temporalmente un rendimiento de la CPU adicional por encima de la línea base según sea necesario. Esto se conoce como ampliación ("bursting" en inglés). Con las instancias de ráfagas, no tiene que aprovisionar excesivamente su instancia para manejar picos de rendimiento ocasionales; no tiene que pagar por la capacidad que nunca usa.
En el gráfico de métrica de utilización de CPU para las instancias, verá una zona sostenible y una zona de ráfagas. Su instancia de Lightsail puede operar en la zona sostenible indefinidamente sin afectar el funcionamiento de su sistema.
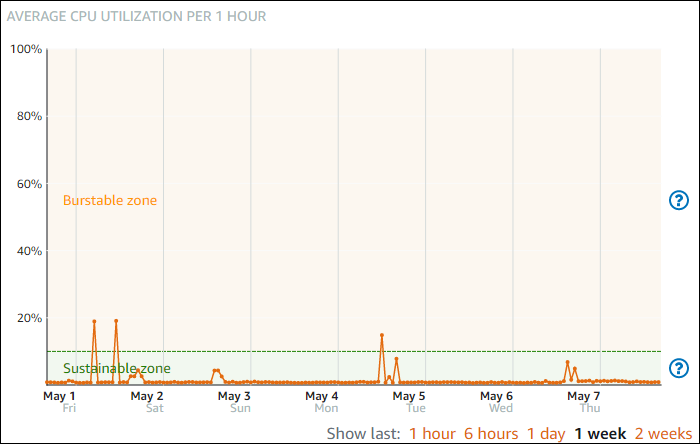
Es posible que su instancia comience a funcionar en la zona de ráfagas cuando esté bajo carga pesada, como al compilar código, instalar software nuevo, ejecutar un trabajo por lotes o atender solicitudes de carga máxima. Mientras opera en la zona de ráfagas, la instancia consume una mayor cantidad de ciclos de CPU. Por lo tanto, solo puede operar en esta zona durante un periodo de tiempo limitado.
El periodo de tiempo que su instancia puede operar en la zona de ráfagas depende de cuán lejos se encuentre en la zona de ráfagas. Una instancia que opera en el extremo inferior de la zona de ráfagas puede reventar durante un periodo de tiempo más largo que una instancia que opera en el extremo superior de la zona de ráfagas. Sin embargo, una instancia que esté en cualquier lugar de la zona de ráfagas durante un periodo de tiempo sostenido eventualmente consumará toda la capacidad de la CPU hasta que vuelva a funcionar en la zona sostenible.
Supervise la métrica de utilización de la CPU de su instancia para ver cómo se distribuye su rendimiento entre las zonas sostenibles y las zonas de ráfagas. Si el sistema solo se mueve ocasionalmente a la zona de ráfagas, debería estar bien continuar usando la instancia que está ejecutando. Sin embargo, si ves que tu instancia pasa un tiempo considerable en la zona de ráfaga, es posible que desees cambiarte a un plan más grande para tu instancia (usa el plan de 12$). USD/month plan instead of the $5 USD/month Puede cambiar a un plan más grande creando una nueva instantánea de la instancia y, a continuación, creando una nueva instancia a partir de la instantánea.
Vea las métricas de las instancias en la consola de Lightsail
Complete los siguientes pasos para ver las métricas de la instancia en la consola de Lightsail.
-
Inicie sesión en la consola de Lightsail
. -
En el panel de navegación izquierdo, elija instancias.
-
Elija el nombre de la instancia para la que desea ver las métricas.
-
Elija la pestaña Metrics (Métricas) de la página Instance management (Gestión de instancias).
-
Seleccione la métrica que desea ver en el menú desplegable bajo el encabezado Metrics graphs (Gráficos de métricas) .
El gráfico muestra una representación visual de los puntos de datos para la métrica elegida.
nota
Al ver los gráficos de métricas de uso de la CPU de sus instancias en la consola Lightsail, verá zonas sostenibles y con capacidad de ráfaga. Para obtener más información acerca de estas zonas, vea Zonas sostenibles y ráfagas del uso de la CPU.
-
Puede realizar las siguientes acciones en el gráfico de métricas:
-
Cambie la vista del gráfico para mostrar datos de 1 hora, 6 horas, 1 día, 1 semana y 2 semanas.
-
Detenga el cursor en un punto de datos para ver información detallada sobre ese punto de datos.
-
Agregue una alarma para que la métrica seleccionada se notifique cuando la métrica cruce un umbral especificado. Para obtener más información, consulte Alarmas y Creación de alarmas de métricas de instancias.
-
Pasos a seguir a continuación
Hay algunas tareas adicionales que puede realizar para las métricas de instancia:
-
Agregue una alarma para que la métrica seleccionada se notifique cuando la métrica cruce un umbral especificado. Para obtener más información, consulte Alarmas de métricas y Creación de alarmas de métricas de instancias.
-
Cuando se activa una alarma, aparece un cartel de notificación en la consola Lightsail. Para recibir una notificación por correo electrónico o mensaje de texto SMS, debe añadir su dirección de correo electrónico y su número de teléfono móvil como contactos de notificación en cada uno de los Región de AWS lugares en los que desee supervisar sus recursos. Para obtener más información, consulte Adición de contactos de notificación.
-
Para dejar de recibir notificaciones, puede eliminar el correo electrónico y el teléfono móvil de Lightsail. Para obtener más información, consulte Eliminación o deshabilitación de alarmas de métricas. También puede desactivar o eliminar una alarma para dejar de recibir notificaciones para una alarma específica. Para obtener más información, consulte Eliminación o deshabilitación de alarmas de métricas.
