Ya no actualizamos el servicio Amazon Machine Learning ni aceptamos nuevos usuarios para él. Esta documentación está disponible para los usuarios actuales, pero ya no la actualizamos. Para obtener más información, consulte Qué es Amazon Machine Learning.
Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Paso 2: cree una fuente de datos de entrenamiento
Después de cargar el conjunto de datos de banking.csv a su ubicación de Amazon Simple Storage Service (Amazon S3), la utilizará para crear un origen de datos de entrenamiento. Una fuente de datos es un objeto de Amazon Machine Learning (Amazon ML) que contiene la ubicación de los datos de entrada y metadatos importantes sobre los datos de entrada. Amazon ML utiliza la fuente de datos para operaciones como el entrenamiento y la evaluación del modelo de ML.
Para crear una fuente de datos, proporcione los siguientes datos:
-
Ubicación de Amazon S3 de sus datos de y permisos para obtener acceso a ellos
-
El esquema, que incluye los nombres de los atributos en los datos y el tipo de cada atributo (Numeric, Text, Categorical o Binary)
-
El nombre del atributo que contiene la respuesta que desea que aprenda a predecir Amazon ML el atributo de destino
nota
La fuente de datos realmente no almacena sus datos, sino que solo les hace referencia. Evite mover o cambiar los archivos almacenados en Amazon S3. Si los mueve o los cambia, Amazon ML no puede obtener acceso a ellos para crear un modelo de ML, generar evaluaciones o generar predicciones.
Creación de la fuente de datos de entrenamiento
Abra la consola Amazon Machine Learning en https://console.aws.amazon.com/machinelearning/
. -
Elija Comenzar.
nota
Este tutorial supone que es la primera vez que utiliza Amazon ML. Si ha usado Amazon ML antes, puede utilizar la lista desplegable Crear nuevo… en el panel de Amazon ML para crear un origen de datos nuevo.
-
En la página Introducción a Amazon Machine Learning, seleccione Lanzar.
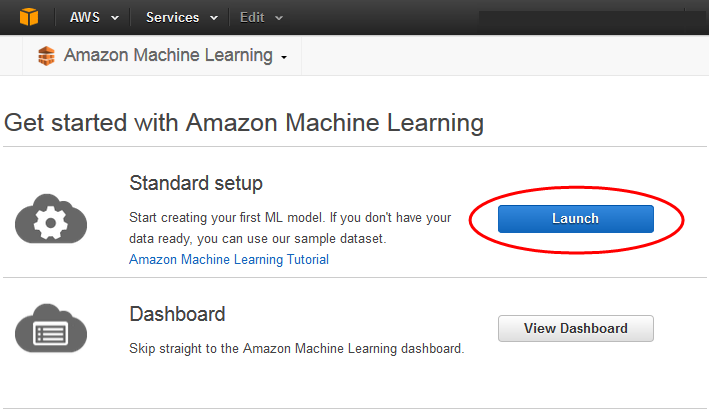
-
En la página Input Data (Datos de entrada), para Where is your data located? (¿Dónde están sus datos?), asegúrese de que está marcado S3.

-
Para S3 Location (Ubicación de S3), escriba la ubicación completa del archivo
banking.csvdel paso 1: prepare los datos. Por ejemplo:your-bucket/banking.csv. Amazon ML añade s3:// al nombre de su bucket por usted. -
En Datasource name (Nombre de origen de datos), escriba
Banking Data 1.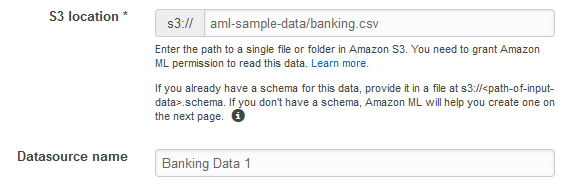
-
Seleccione Verificar.
-
En el cuadro de diálogo S3 permissions (Permisos de S3), elija Yes (Sí).
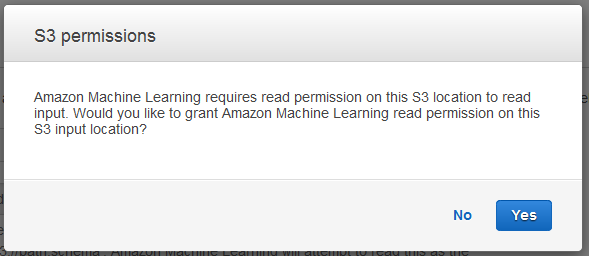
-
Si Amazon ML puede obtener acceso al archivo de datos y leerlo en la ubicación de S3, verá una página similar a la siguiente. Revise las propiedades y, a continuación, elija Continue (Continuar).

A continuación, establezca un esquema. Un esquema es la información que necesita Amazon ML para interpretar los datos de entrada de un modelo de ML, incluidos los nombres de los atributos y sus tipos de datos asignados, así como los nombres de los atributos especiales. Hay dos formas de proporcionar un esquema a Amazon ML:
-
Proporcione un archivo de esquema independiente al cargar los datos de Amazon S3.
-
Permitir que Amazon ML infiera los tipos de atributo y cree un esquema por usted.
En este tutorial, pediremos a Amazon ML que infiera el esquema.
Para obtener información sobre la creación de archivo de esquema independiente, consulte Creación de un esquema de datos para Amazon ML.
Permisos para que Amazon ML infiera el esquema
-
En la página Esquema, Amazon ML muestra el esquema que infirió. Revise los tipos de datos que ha inferido Amazon ML para los atributos. Es importante que los atributos estén señalados con el tipo de datos correcto para ayudar a que Amazon ML reciba los datos correctamente y habilitar el procesamiento de características correcto en los atributos.
-
Los atributos que solo tienen dos estados posibles, como sí o no, deberían estar marcados como Binary (Binario).
-
Los atributos que son números o cadenas que se utilizan para denotar una categoría deberían estar marcados como Categorical (Categórico).
-
Los atributos que son cantidades numéricas cuyo orden es relevante deberían estar marcados como Numeric (Numérico).
-
Los atributos que son cadenas que desea tratar como palabras delimitadas por espacios deberían estar marcados como Text (Texto).

-
-
En este tutorial, Amazon ML ha identificado correctamente los tipos de datos para todos los atributos. Por lo tanto, seleccione Continuar.
A continuación, seleccione un atributo de destino.
Recuerde que el destino es el atributo que el modelo de ML debe aprender a predecir. El atributo y indica si un individuo se ha suscrito a una campaña en el pasado: 1 (sí) o 0 (no).
nota
Elija un atributo de destino solo si utilizará la fuente de datos para entrenar y evaluar modelos de ML.
Selección de "y" como el atributo de destino
-
En la parte inferior derecha de la tabla, elija la flecha simple para avanzar a la última página de la tabla, donde aparece el atributo con el nombre
y.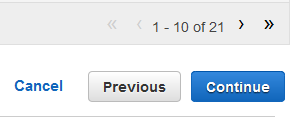
-
En la columna Target (Destino), seleccione
y.
Amazon ML confirma que y está seleccionado en el destino.
-
Elija Continuar.
-
En la página Row ID (ID de fila), en Does your data contain an identifier? (Los datos contienen un identificador?), asegúrese de que está seleccionado No, el valor predeterminado.
-
Seleccione Review (Revisar) y, a continuación, Continue (Continuar).
Ahora que tiene un origen de datos de entrenamiento, está listo para crear su modelo.
