Amazon Managed Service for Apache Flink (Amazon MSF) se denominaba anteriormente Amazon Kinesis Data Analytics for Apache Flink.
Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Puntos de control
Los puntos de control son el mecanismo de Flink para garantizar que el estado de una aplicación sea tolerante a errores. El mecanismo permite a Flink recuperar el estado de los operadores si el trabajo falla y proporciona a la aplicación la misma semántica que cuando se ejecuta sin errores. Con Managed Service para Apache Flink, el estado de una aplicación se almacena en RockSDB, un almacén de claves/valores integrado que mantiene su estado de funcionamiento en el disco. Cuando se toma un punto de control, el estado también se carga en Amazon S3, por lo que, incluso si se pierde el disco, el punto de control se puede utilizar para restaurar el estado de la aplicación.
Para obtener más información, consulte How does State Snapshotting Work?
Fases de creación de punto de comprobación
La subtarea de un operador de puntos de control en Flink consta de 5 etapas principales:
Espera [Desfase de inicio]: Flink utiliza barreras de puntos de control que se insertan en el flujo, por lo que el tiempo en esta fase es el tiempo que el operador espera a que la barrera del punto de control llegue a ella.
Alineación [Duración de la alineación]: en esta fase, la subtarea ha alcanzado una barrera, pero está esperando a que aparezcan barreras de otros flujos de entrada.
Puntos de control de sincronización [Duración de la sincronización]: en esta fase, la subtarea toma la instantánea del estado del operador y bloquea el resto de las actividades de la subtarea.
Puntos de control asíncronos [Duración asíncrona]: la mayor parte de esta fase consiste en que la subtarea carga el estado a Amazon S3. Durante esta fase, la subtarea ya no está bloqueada y puede procesar registros.
Confirmación: por lo general, se trata de una etapa corta y consiste simplemente en la subtarea de enviar un acuse de recibo JobManager y también de ejecutar cualquier mensaje de confirmación (por ejemplo, con los sumideros de Kafka).
Cada una de estas fases (aparte de la Confirmación) se asigna a una métrica de duración de los puntos de comprobación que está disponible en la WebUI de Flink, que puede ayudar a aislar la causa del punto de control largo.
Para ver una definición exacta de cada una de las métricas disponibles en los puntos de control, vaya a la pestaña Historial
Investigación
Al investigar la duración prolongada de los puntos de control, lo más importante es determinar el cuello de botella del punto de control, es decir, qué operador y subtarea están tardando más en llegar al punto de control y qué fase de esa subtarea está tardando más tiempo. Esto se puede determinar mediante la WebUI de Flink en la tarea de punto de comprobación de trabajos. La interfaz web de Flink proporciona datos e información que ayudan a investigar los problemas relacionados con los puntos de control. Para obtener un desglose completo, consulte Monitoring Checkpointing
Lo primero que hay que tener en cuenta es la Duración de principio a fin de cada operador en el gráfico de tareas para determinar qué operador está tardando en llegar al punto de comprobación y merece una investigación más profunda. Según la documentación de Flink, la definición de la duración es:
La duración desde la marca de tiempo de activación hasta la última confirmación (o n/a si aún no se ha recibido ninguna confirmación). La duración de un punto de control completo de principio a fin viene determinada por la última subtarea que confirma el punto de comprobación. Este tiempo suele ser superior al que necesitan las subtareas individuales para comprobar realmente el estado.
Las demás duraciones del punto de comprobación también proporcionan información más detallada sobre a qué se dedica el tiempo.
Si la Duración de la sincronización es alta, esto indica que algo está sucediendo durante la captura de pantalla. Durante esta fase se utiliza snapshotState() para clases que implementan la interfaz SnapshotState; puede ser código de usuario, por lo que los volcados de subprocesos pueden resultar útiles para investigar este aspecto.
Una Duración asíncrona prolongada sugeriría que se está dedicando mucho tiempo a cargar el estado en Amazon S3. Esto puede ocurrir si el estado es grande o si se están cargando muchos archivos de estado. Si este es el caso, vale la pena investigar cómo utiliza la aplicación el estado y asegurarse de que se utilizan las estructuras de datos nativas de Flink siempre que sea posible (con el estado clave
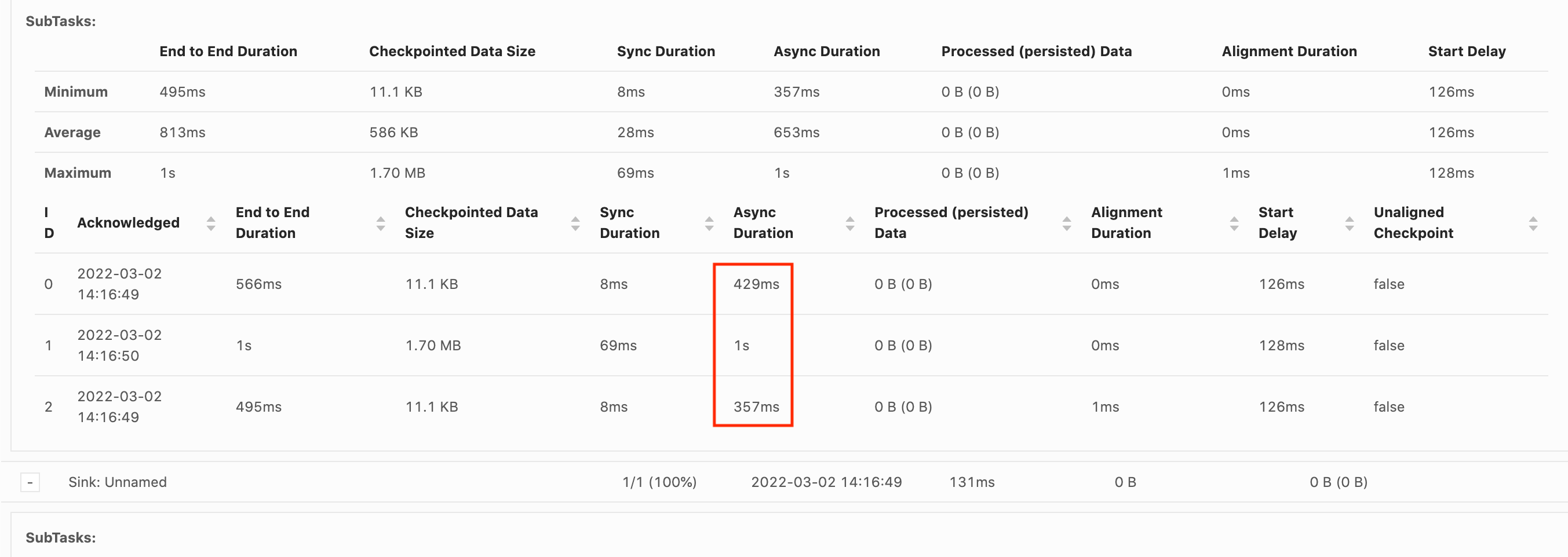
Si el Desfase de inicio es alto, indicaría que la mayor parte del tiempo se dedica a esperar a que la barrera del punto de control llegue al operador. Esto indica que la solicitud está tardando un tiempo en procesar los registros, lo que significa que la barrera está pasando lentamente por el gráfico de tareas. Este suele ser el caso si el Trabajo tiene resistencia o si un operador está constantemente ocupado. El siguiente es un ejemplo en el JobGraph que el segundo KeyedProcess operador está ocupado.
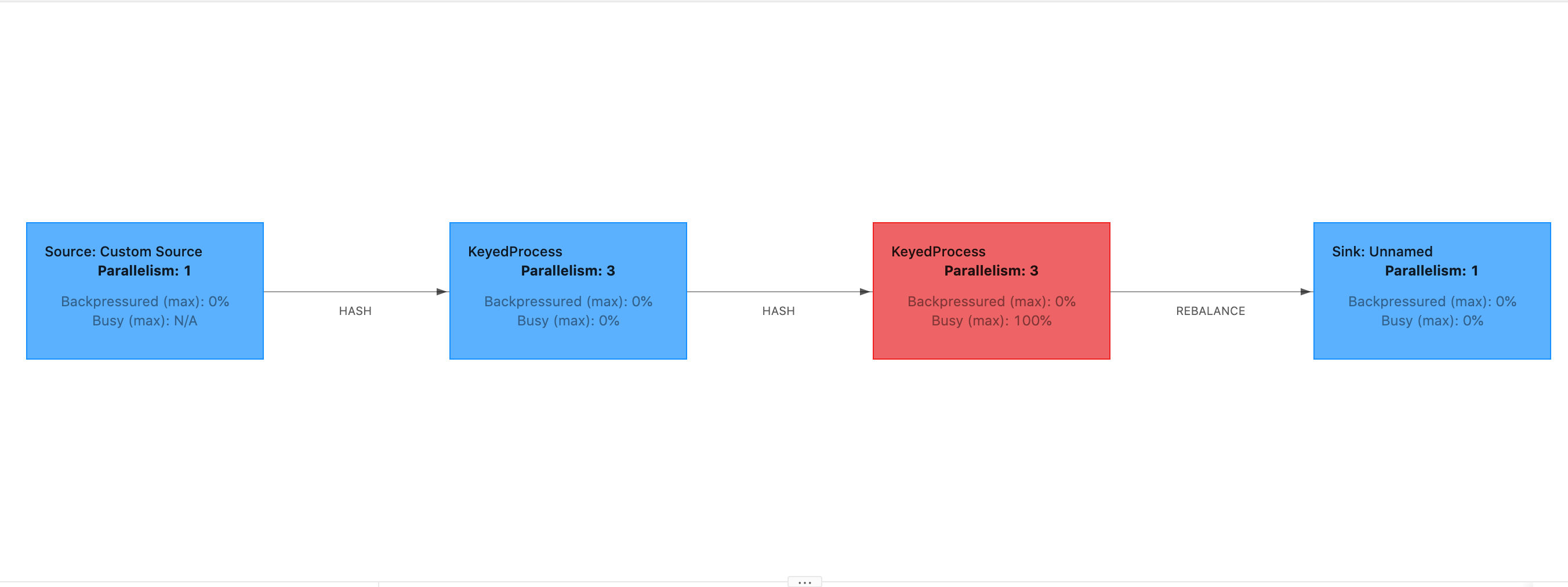
Puedes investigar qué está tardando tanto utilizando Flink Flame Graphs o volcando TaskManager hilos. Una vez identificado el cuello de botella, se puede investigar más a fondo utilizando gráficos tipo llama o volcados de subprocesos.
Volcados de subprocesos
Los volcados de subprocesos son otra herramienta de depuración que se encuentra en un nivel ligeramente inferior al de los gráficos tipo llama. Un volcado de subprocesos genera el estado de ejecución de todos los subprocesos en un momento dado. Flink toma un volcado de subprocesos de JVM, que es un estado de ejecución de todos los subprocesos del proceso de Flink. El estado de un subproceso se presenta mediante un seguimiento de la pila del subproceso, así como información adicional. En realidad, los gráficos tipo llama se crean utilizando múltiples seguimientos de la pila tomados en rápida sucesión. El gráfico es una visualización hecha a partir de estos seguimientos que facilita la identificación de las rutas de código más comunes.
"KeyedProcess (1/3)#0" prio=5 Id=1423 RUNNABLE at app//scala.collection.immutable.Range.foreach$mVc$sp(Range.scala:154) at $line33.$read$$iw$$iw$ExpensiveFunction.processElement(<console>>19) at $line33.$read$$iw$$iw$ExpensiveFunction.processElement(<console>:14) at app//org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:83) at app//org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:205) at app//org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.processElement(AbstractStreamTaskNetworkInput.java:134) at app//org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.emitNext(AbstractStreamTaskNetworkInput.java:105) at app//org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:66) ...
Arriba hay un fragmento de un volcado de subprocesos tomado de la interfaz de usuario de Flink para un solo subproceso. La primera línea contiene información general sobre este subproceso, que incluye:
El nombre del hilo KeyedProcess (1/3) #0
Prioridad del subproceso prio=5
Un identificador de subproceso único Id=1423
Estado del subproceso: EJECUTABLE
El nombre de un subproceso generalmente proporciona información sobre el propósito general del subproceso. Los subprocesos del operador se pueden identificar por su nombre, ya que los subprocesos del operador tienen el mismo nombre que el operador, así como una indicación de la subtarea con la que están relacionados, por ejemplo, el subproceso KeyedProcess (1/3) #0 proviene del KeyedProcessoperador y pertenece a la primera subtarea (de 3).
Los subprocesos pueden tener uno de los siguientes estados:
NUEVO: el subproceso se ha creado pero aún no se ha procesado
EJECUTABLE: el subproceso se está ejecutando en la CPU
BLOQUEADO: el subproceso está esperando a que otro subproceso libere su bloqueo
ESPERANDO: el subproceso está en espera mediante un método
wait(),join(), opark()PROGRAMADO_ESPERANDO: el subproceso está en espera mediante el método dormir, esperar, unirse o ubicar, pero con un tiempo de espera máximo.
nota
En Flink 1.13, la profundidad máxima de un único stacktrace en el volcado de subprocesos está limitada a 8.
nota
Los volcados de subprocesos deberían ser el último recurso para depurar problemas de rendimiento en una aplicación de Flink, ya que pueden resultar difíciles de leer y requieren la toma de múltiples muestras y su análisis manual. Si es posible, es preferible utilizar gráficos tipo llama.
Volcados de subprocesos en Flink
En Flink, se puede realizar un volcado de subprocesos seleccionando la opción Administradores de tareas en la barra de navegación izquierda de la interfaz de usuario de Flink, seleccionando un administrador de tareas específico y, a continuación, navegando a la pestaña Volcado de subprocesos. El volcado de subprocesos se puede descargar, copiar a su editor de texto favorito (o analizador de volcado de subprocesos) o analizar directamente dentro de la vista de texto de la interfaz de usuario web de Flink (sin embargo, esta última opción puede resultar un poco torpe).
Para determinar qué administrador de tareas utilizar, se puede utilizar un volcado de subprocesos de la TaskManagerspestaña cuando se elige un operador en particular. Esto muestra que el operador se ejecuta diferentes subtareas de un operador y se puede ejecutar diferentes Administradores de tareas.
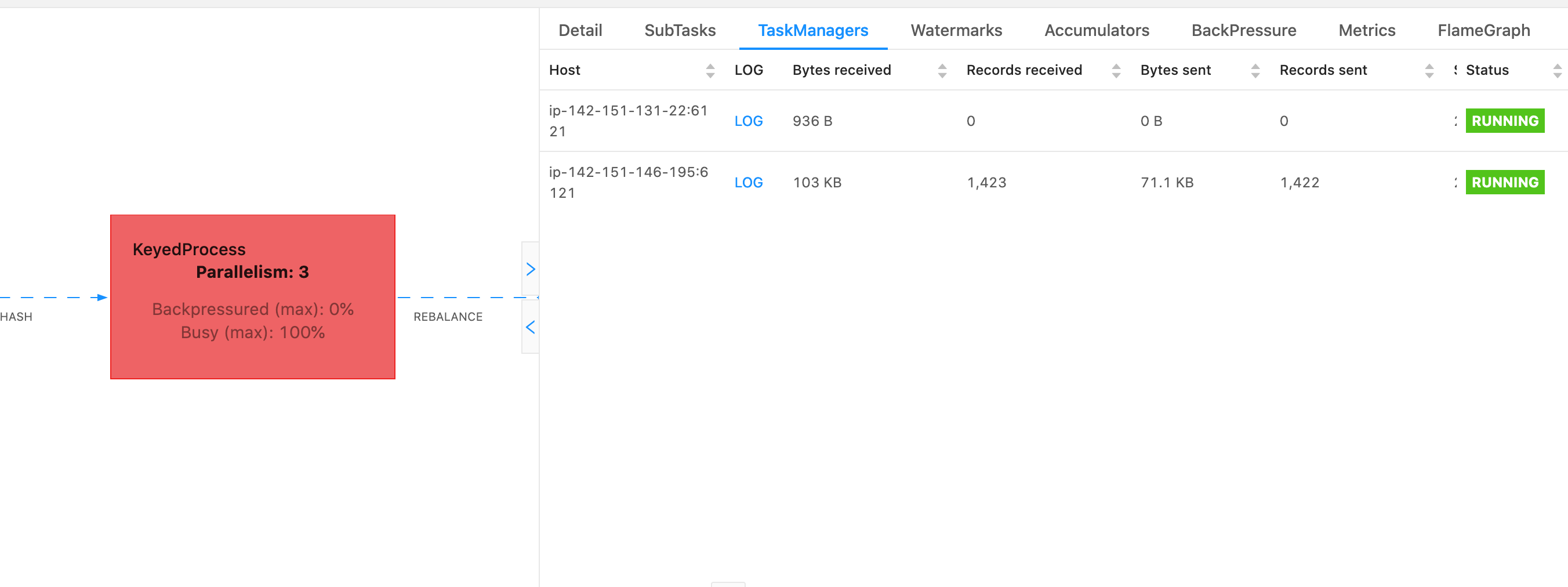
El volcado estará compuesto por múltiples seguimientos de pila. Sin embargo, cuando se investiga el volcado, lo más importante es lo que está relacionado con un operador. Se pueden encontrar fácilmente, ya que los subprocesos del operador tienen el mismo nombre que el operador, así como una indicación de la subtarea con la que están relacionados. Por ejemplo, el siguiente rastreo de pila proviene del KeyedProcessoperador y es la primera subtarea.
"KeyedProcess (1/3)#0" prio=5 Id=595 RUNNABLE at app//scala.collection.immutable.Range.foreach$mVc$sp(Range.scala:155) at $line360.$read$$iw$$iw$ExpensiveFunction.processElement(<console>:19) at $line360.$read$$iw$$iw$ExpensiveFunction.processElement(<console>:14) at app//org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:83) at app//org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:205) at app//org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.processElement(AbstractStreamTaskNetworkInput.java:134) at app//org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.emitNext(AbstractStreamTaskNetworkInput.java:105) at app//org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:66) ...
Esto puede resultar confuso si hay varios operadores con el mismo nombre, pero podemos ponerle nombre a los operadores para evitarlo. Por ejemplo:
.... .process(new ExpensiveFunction).name("Expensive function")
Gráficos Flame
Los gráficos tipo llama son una útil herramienta de depuración que visualiza los seguimientos de pila del código objetivo, lo que permite identificar las rutas de código más frecuentes. Se crean muestreando los seguimientos de las pilas varias veces. El eje x de un gráfico tipo llama muestra los diferentes perfiles de la pila, mientras que el eje y muestra la profundidad de la pila e incluye el seguimiento de la pila. Un único rectángulo en un gráfico tipo llama representa un marco de pila, y el ancho de un marco muestra la frecuencia con la que aparece en las pilas. Para obtener más información acerca de los gráficos tipo llama y cómo usarlos, consulte Gráficos Flame
En Flink, se puede acceder al gráfico de llama de un operador a través de la interfaz de usuario web seleccionando un operador y, a continuación, eligiendo la FlameGraphpestaña. Una vez que se hayan recolectado suficientes muestras, se mostrará el gráfico tipo llama. A continuación se muestra FlameGraph el ProcessFunction punto de control que tardó mucho en llegar.
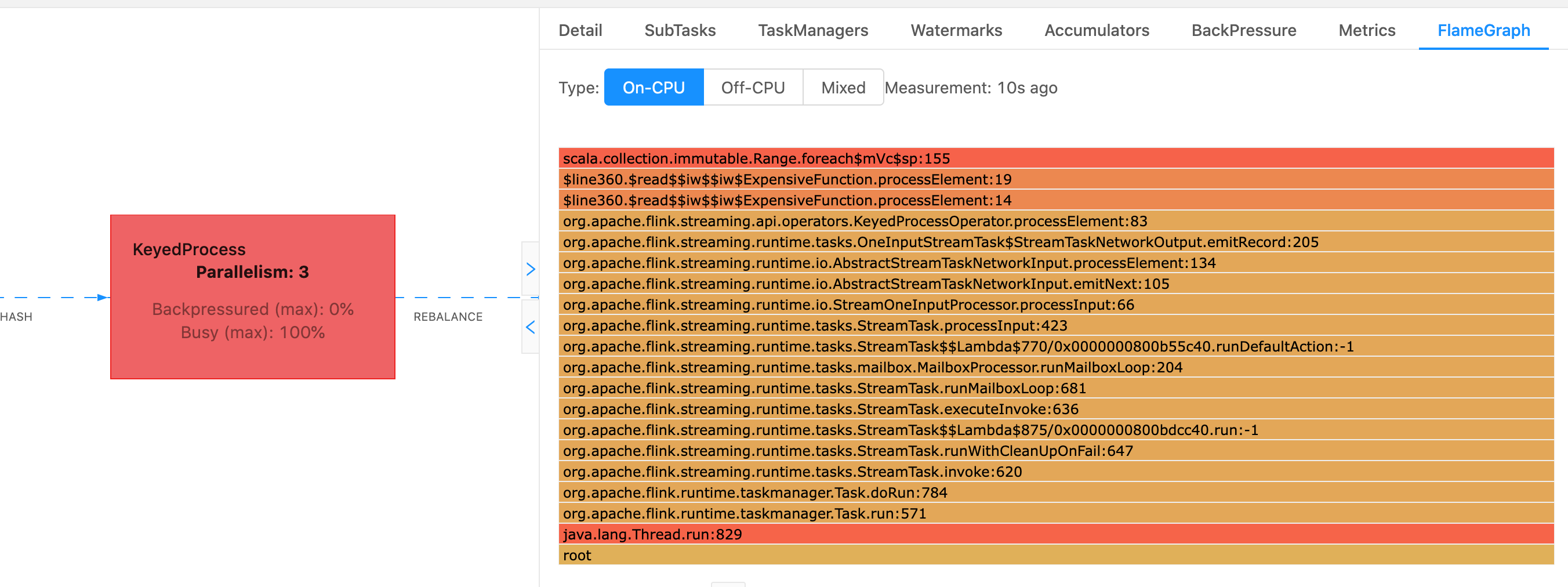
Este es un gráfico de llama muy simple y muestra que todo el tiempo de la CPU se está gastando al alcance processElement de la mano del ExpensiveFunction operador. También se obtiene el número de línea para ayudar a determinar en qué parte de la ejecución código se está realizando.
