Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Características y límites de la búsqueda vectorial
Disponibilidad de búsqueda vectorial
La configuración de MemoryDB, que permite la búsqueda vectorial, es compatible con los tipos de nodos R6g, R7g y T4g y está disponible en todas las regiones donde está disponible MemoryDB. AWS
Los clústeres existentes no se pueden modificar para habilitar la búsqueda. Sin embargo, los clústeres habilitados para la búsqueda se pueden crear a partir de instantáneas de clústeres con la búsqueda deshabilitada.
Restricciones paramétricas
En la siguiente tabla se muestran los límites de varios elementos de búsqueda vectorial:
| Elemento | Valor máximo |
|---|---|
| Cantidad de dimensiones de un vector | 32768 |
| Cantidad de índices que se pueden crear | 10 |
| Cantidad de campos de un índice | 50 |
| Cláusula de tiempo de espera FT.SEARCH y FT.AGGREGATE (milisegundos) | 10000 |
| Cantidad de etapas de canalización en el comando FT.AGGREGATE | 32 |
| Cantidad de campos de la cláusula FT.AGGREGATE LOAD | 1024 |
| Cantidad de campos de la cláusula FT.AGGREGATE GROUPBY | 16 |
| Cantidad de campos de la cláusula FT.AGGREGATE SORTBY | 16 |
| Cantidad de parámetros en la cláusula FT.AGGREGATE PARAM | 32 |
| Parámetro HNSW M | 512 |
| Parámetro HNSW EF_CONSTRUCTION | 4096 |
| Parámetro HNSW EF_RUNTIME | 4096 |
Límites de escalado
La búsqueda vectorial de MemoryDB está limitada actualmente a una única partición y no se admite el escalado horizontal. La búsqueda vectorial admite el escalado vertical y de réplica.
Restricciones operativas
Persistencia y reposición de índices
La característica de búsqueda vectorial conserva la definición de los índices y el contenido del índice. Esto significa que, durante cualquier solicitud o evento operativo que provoque el inicio o el reinicio de un nodo, la definición y el contenido del índice se restauran a partir de la última instantánea y cualquier transacción pendiente se reproduce desde el diario. Para iniciar esta operación no se requiere ninguna acción por parte del usuario. La reconstrucción se realiza como una operación de reposición tan pronto como se restauran los datos. Esto equivale funcionalmente a que el sistema ejecute automáticamente un comando FT.CREATE para cada índice definido. Tenga en cuenta que el nodo estará disponible para las operaciones de la aplicación tan pronto como se restauren los datos, pero probablemente antes de que se complete la reposición del índice, lo que significa que las aplicaciones volverán a estar visibles para las aplicaciones. Por ejemplo, es posible que se rechacen los comandos de búsqueda que utilicen índices de reposición. Para obtener más información sobre la reposición, consulte Información general de la búsqueda vectorial.
La finalización de la reposición del índice no se sincroniza entre una reposición principal y una réplica. Esta falta de sincronización puede pasar a ser visible para las aplicaciones de forma inesperada, por lo que se recomienda que las aplicaciones verifiquen que esté finalizada la reposición en las principales y todas las réplicas antes de iniciar las operaciones de búsqueda.
Migración instantánea import/export y en vivo
La presencia de índices de búsqueda en un archivo RDB limita la transportabilidad compatible de esos datos. El formato de los índices vectoriales definido por la funcionalidad de búsqueda vectorial de MemoryDB solo lo entiende otro clúster de MemoryDB habilitado para vectores. Además, los archivos RDB de los clústeres de vista previa se pueden importar desde la versión de GA de los clústeres de MemoryDB, que reconstruirá el contenido del índice al cargar el archivo RDB.
Sin embargo, los archivos RDB que no contienen índices no están restringidos de esta manera. Por lo tanto, los datos de un clúster de vista previa se pueden exportar a clústeres que no sean de vista previa mediante la eliminación de los índices antes de la exportación.
Consumo de memoria
El consumo de memoria se basa en el número de vectores, el número de dimensiones, el valor M y la cantidad de datos no vectoriales, como los metadatos asociados al vector u otros datos almacenados en la instancia.
La memoria total necesaria es una combinación del espacio necesario para los datos vectoriales reales y el espacio necesario para los índices vectoriales. El espacio necesario para los datos vectoriales se calcula midiendo la capacidad real necesaria para almacenar los vectores dentro de las estructuras de datos HASH o JSON y la sobrecarga a los slabs de memoria más cercanos, para lograr asignaciones de memoria óptimas. Cada uno de los índices vectoriales utiliza referencias a los datos vectoriales almacenados en estas estructuras de datos y utiliza optimizaciones de memoria eficientes para eliminar cualquier copia duplicada de los datos vectoriales del índice.
El número de vectores depende de cómo se decida representar los datos como vectores. Por ejemplo, puede elegir representar un único documento en varios fragmentos, donde cada fragmento represente un vector. Como alternativa, puede optar por representar todo el documento como un único vector.
El número de dimensiones de los vectores depende del modelo de incrustación que se elija. Por ejemplo, si opta por utilizar el modelo de incrustación AWS Titan
El parámetro M representa el número de enlaces bidireccionales creados para cada elemento nuevo durante la construcción del índice. MemoryDB establece este valor de forma predeterminada en 16, pero puede anular este valor. Un parámetro M más alto funciona mejor para requisitos de alta dimensionalidad y and/or alta recuperación, mientras que los parámetros M bajos funcionan mejor para requisitos de baja dimensionalidad y and/or baja recuperación. El valor M aumenta el consumo de memoria a medida que el índice aumenta, lo que aumenta el consumo de memoria.
En la experiencia de la consola, MemoryDB ofrece una forma sencilla de elegir el tipo de instancia adecuado en función de las características de la carga de trabajo vectorial, tras seleccionar la opción Habilitar la búsqueda vectorial en la configuración del clúster.
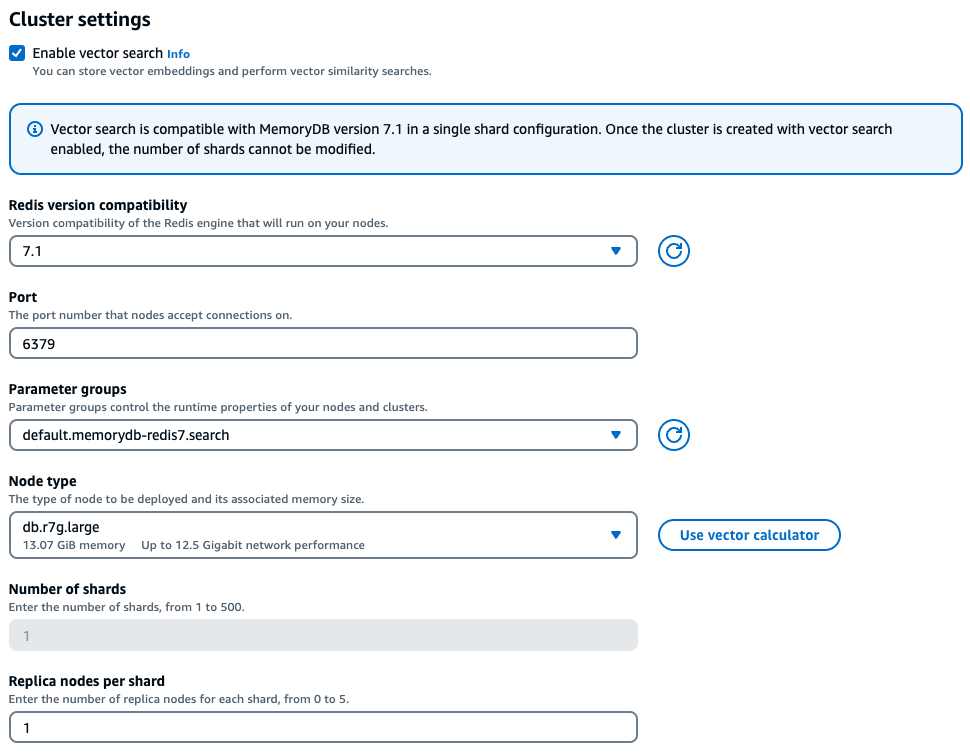
Ejemplo de carga de trabajo
Un cliente desea crear un motor de búsqueda semántica basado en sus documentos financieros internos. Actualmente tiene un millón de documentos financieros divididos en 10 vectores por documento utilizando el modelo de incrustación Titan con 1536 dimensiones y no tiene datos que no sean vectoriales. El cliente decide usar el valor predeterminado de 16 como parámetro M.
Vectores: 1 M * 10 fragmentos = 10 M vectores
Dimensiones: 1536
Datos no vectoriales (GB): 0 GB
Parámetro M: 16
Con estos datos, el cliente puede hacer clic en el botón Usar calculadora vectorial de la consola para obtener un tipo de instancia recomendado en función de sus parámetros:
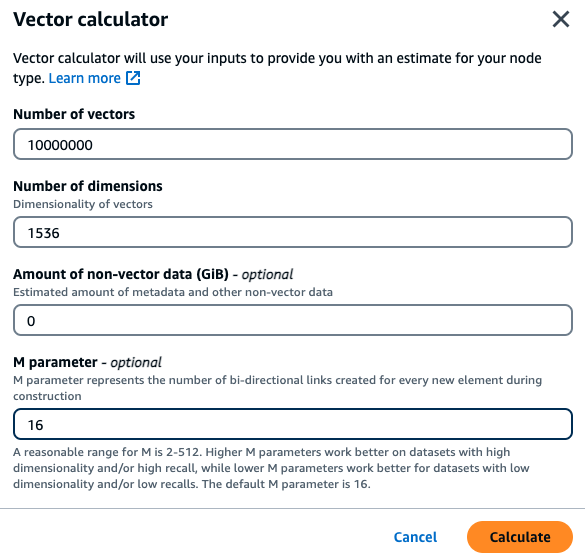

En este ejemplo, la calculadora vectorial buscará el tipo de nodo MemoryDB r7g
Según el método de cálculo anterior y los parámetros de la carga de trabajo de la muestra, estos datos vectoriales necesitarían 104,9 GB para almacenar los datos y un índice único. En este caso, se recomendaría el tipo de instancia db.r7g.4xlarge, ya que tiene 105,81 GB de memoria útil. El siguiente tipo de nodo más pequeño sería demasiado pequeño para contener la carga de trabajo vectorial.
Como cada uno de los índices vectoriales utiliza referencias a los datos vectoriales almacenados y no crea copias adicionales de los datos vectoriales en el índice vectorial, los índices también consumirán relativamente menos espacio. Esto resulta muy útil para crear varios índices y también en situaciones en las que se han eliminado partes de los datos vectoriales y la reconstrucción del gráfico HNSW ayudaría a crear conexiones de nodos óptimas para obtener resultados de búsqueda vectorial de alta calidad.
Falta de memoria durante la reposición
Al igual que las operaciones de escritura en OSS de Valkey y Redis, el relleno de índices está sujeto a limitaciones. out-of-memory Si la memoria del motor se llena mientras hay una reposición en curso, todas las reposiciones se pausan. Si queda memoria disponible, se reanuda el proceso de reposición. También es posible eliminar e indexar cuando la reposición está en pausa por falta de memoria.
Transacciones
Los comandosFT.CREATE,, FT.DROPINDEX FT.ALIASADDFT.ALIASDEL, y FT.ALIASUPDATE no se pueden ejecutar en un contexto transaccional, es decir, no dentro de un MULTI/EXEC bloque o dentro de un script LUA o FUNCTION.
