Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Formato de carga para los datos de openCypher
Para cargar datos de openCypher con el formato CSV de OpenCypher, debe especificar los nodos y las relaciones en archivos independientes. El programa de carga puede cargar desde varios de estos archivos de nodos y archivos de relaciones en un solo trabajo de carga.
Para cada comando de carga, el conjunto de archivos que se va a cargar debe tener el mismo prefijo de ruta en un bucket de Amazon Simple Storage Service. Debe especificar ese prefijo en el parámetro de origen. Los nombres de archivo y sus extensiones no son importantes.
En Amazon Neptune, el formato CSV de openCypher cumple la especificación CSV de la RFC 4180. Para obtener más información, consulte Formato común y tipo MIME para archivos CSV
nota
Estos archivos deben estar codificados en formato UTF-8.
Cada archivo tiene una fila de encabezados separada por comas que contiene los encabezados de las columnas del sistema y los encabezados de las columnas de propiedades.
Encabezados de columnas del sistema en archivos de carga de datos de openCypher
Una columna del sistema determinada solo puede aparecer una vez en cada archivo. Todas las etiquetas de encabezado de columna del sistema distinguen entre mayúsculas y minúsculas.
Los encabezados de columna del sistema que son obligatorios y están permitidos son diferentes para los archivos de carga de nodos de openCypher y los archivos de carga de relaciones:
Encabezados de columnas del sistema en los archivos de nodos
-
:ID: (obligatorio) Un identificador para el nodo.Se puede añadir un espacio de identificación opcional al encabezado de la columna
:IDdel nodo de la siguiente manera::ID(. Un ejemplo esID Space):ID(movies).Al cargar las relaciones que conectan los nodos de este archivo, utilice los mismos espacios de identificación en las columnas de los archivos de relaciones.
:START_IDand/or:END_IDLa columna
:IDde los nodos se puede almacenar opcionalmente como una propiedad en el formatoproperty name:IDname:ID.El nodo IDs debe ser único en todos los archivos de nodos de la carga actual y anterior. Si se utiliza un espacio de ID, el nodo IDs debe ser único en todos los archivos de nodos que utilizan el mismo espacio de ID en las cargas actuales y anteriores.
-
:LABEL: etiqueta del nodo.Cuando se utilizan varios valores de etiqueta para un solo nodo, cada etiqueta debe estar separada por punto y coma ()
;.
Encabezados de columnas del sistema en archivos de relaciones
-
:ID: identificador de la relación. Es obligatorio cuandouserProvidedEdgeIdses true (el valor predeterminado), pero no es válido cuandouserProvidedEdgeIdsesfalse.La relación IDs debe ser única en todos los archivos de relaciones de las cargas actuales y anteriores.
-
:START_ID: (obligatorio) el identificador de nodo del nodo desde el que se inicia esta relación.Opcionalmente, se puede asociar un espacio de identificador a la columna del identificador inicial en el formato
:START_ID(. El espacio de identificador asignado al identificador del nodo inicial debe coincidir con el espacio de identificador asignado al nodo en su archivo de nodos.ID Space) -
:END_ID: (obligatorio) el identificador de nodo del nodo en el que termina esta relación.Opcionalmente, se puede asociar un espacio de identificador a la columna del identificador final en el formato
:END_ID(. El espacio de identificador asignado al identificador del nodo final debe coincidir con el espacio de identificador asignado al nodo en su archivo de nodos.ID Space) -
:TYPE: tipo de la relación. Las relaciones solo pueden tener un tipo.
nota
Consulte Carga de datos de openCypher para obtener información sobre cómo gestiona el proceso de carga masiva los nodos o relaciones IDs duplicados.
Encabezados de columnas de propiedades en archivos de carga de datos de openCypher
Puede especificar que una columna contenga los valores de una propiedad concreta mediante un encabezado de columna de propiedades con el siguiente formato:
propertyname:type
En los encabezados de las columnas no se permiten el uso de espacios, comas, volantes y líneas nuevas, por lo que los nombres de las propiedades no pueden incluir estos caracteres. A continuación, se muestra un ejemplo de encabezado de columna para una propiedad denominada age del tipo Int:
age:Int
La columna con age:Int como encabezado de columna tendría entonces que contener un número entero o un valor vacío en cada fila.
Tipos de datos en archivos de carga de datos de openCypher de Neptune
-
BooloBoolean: campo booleano. Los valores permitidos sontrueyfalse.Cualquier valor que no sea
truese trata comofalse. -
Byte: número entero comprendido en el rango de-128a127. -
Short: número entero comprendido en el rango de-32,768a32,767. -
Int: número entero comprendido en el rango de-2^31a2^31 - 1. -
Long: número entero comprendido en el rango de-2^63a2^63 - 1. -
Float: número de coma flotante IEEE 754 de 32 bits. Se admiten tanto la notación decimal como la notación científica.Infinity,-InfinityyNaNse reconocen, pero noINF.Los valores que tienen demasiados dígitos y no caben se redondean al valor más cercano (un valor intermedio se redondea a 0 para el último dígito restante en el nivel de bits).
-
Double: número de coma flotante IEEE 754 de 64 bits. Se admiten tanto la notación decimal como la notación científica.Infinity,-InfinityyNaNse reconocen, pero noINF.Los valores que tienen demasiados dígitos y no caben se redondean al valor más cercano (un valor intermedio se redondea a 0 para el último dígito restante en el nivel de bits).
-
String: el uso de las comillas es opcional. Los caracteres de coma, nueva línea y retorno de carro se escapan automáticamente si se incluyen en una cadena rodeada de comillas dobles (") como"Hello, World".Puede incluir comillas en una cadena entre comillas usando dos seguidas; por ejemplo
"Hello ""World""". -
DateTime: fecha Java en uno de los siguientes formatos ISO-8601:yyyy-MM-ddyyyy-MM-ddTHH:mmyyyy-MM-ddTHH:mm:ssyyyy-MM-ddTHH:mm:ssZ
Tipos de datos de conversión automática en archivos de carga de datos de openCypher de Neptune
Los tipos de datos de conversión automática sirven para cargar tipos de datos que Neptune no admite actualmente de forma nativa. Los datos de estas columnas se almacenan en forma de cadenas, textualmente, sin necesidad de compararlos con los formatos previstos. Se permiten los siguientes tipos de datos de conversión automática:
-
Char: campoChar. Almacenado como una cadena. -
Date,LocalDateyLocalDateTime: consulte Neo4j Temporal Instantspara ver una descripción de los tipos date,localdateylocaldatetime. Los valores se cargan textualmente como cadenas, sin validación. -
Duration: consulte Neo4j Duration format. Los valores se cargan textualmente como cadenas, sin validación. -
Punto: campo de puntos para almacenar datos espaciales. Consulte Spatial instants
. Los valores se cargan textualmente como cadenas, sin validación.
Ejemplo del formato de carga de openCypher
El siguiente diagrama, tomado del gráfico TinkerPop moderno, muestra un ejemplo de dos nodos y una relación:
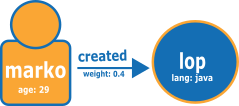
A continuación, se muestra el gráfico en el formato de carga de openCypher normal de Neptune.
Archivo de nodos:
:ID,name:String,age:Int,lang:String,:LABEL v1,"marko",29,,person v2,"lop",,"java",software
Archivo de relaciones:
:ID,:START_ID,:END_ID,:TYPE,weight:Double e1,v1,v2,created,0.4
Como alternativa, puede utilizar los espacios de identificador y el identificador como una propiedad, de la siguiente manera:
Primer archivo de nodo:
name:ID(person),age:Int,lang:String,:LABEL "marko",29,,person
Segundo archivo de nodo:
name:ID(software),age:Int,lang:String,:LABEL "lop",,"java",software
Archivo de relaciones:
:ID,:START_ID(person),:END_ID(software),:TYPE,weight:Double e1,"marko","lop",created,0.4
