Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Ajuste de las consultas de Gremlin mediante explain y profile
Con frecuencia, puede ajustar sus consultas de Gremlin en Amazon Neptune para obtener un mejor rendimiento, utilizando la información que tiene a su disposición en los informes que obtiene de la explicación y el perfil de Neptune. APIs Para ello, es útil entender cómo Neptune procesa los recorridos de Gremlin.
importante
En la TinkerPop versión 3.4.11 se realizó un cambio que mejora la exactitud del procesamiento de las consultas, pero por el momento a veces puede afectar gravemente al rendimiento de las consultas.
Por ejemplo, una consulta de este tipo podría ejecutarse de una forma mucho más lenta:
g.V().hasLabel('airport'). order(). by(out().count(),desc). limit(10). out()
Los vértices situados tras el paso límite ahora se obtienen de forma no óptima debido al cambio de la versión 3.4.11. TinkerPop Para evitarlo, puede modificar la consulta añadiendo el paso barrier() en cualquier punto después de order().by(). Por ejemplo:
g.V().hasLabel('airport'). order(). by(out().count(),desc). limit(10). barrier(). out()
TinkerPop La versión 3.4.11 estaba habilitada en la versión 1.0.5.0 del motor de Neptune.
Descripción del procesamiento de recorridos de Gremlin en Neptune
Cuando se envía un recorrido de Gremlin a Neptune, hay tres procesos principales que transforman el recorrido en un plan de ejecución subyacente para que el motor lo ejecute. Estos procesos son el análisis, la conversión y la optimización,
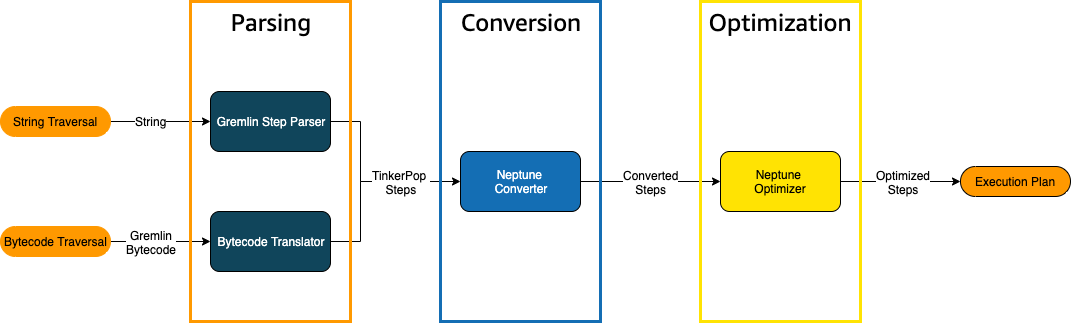
El proceso de análisis de recorridos
El primer paso para procesar un recorrido es analizarlo en un lenguaje común. En Neptune, ese lenguaje común es el conjunto de TinkerPop pasos que forman parte de la TinkerPop API.
Puede enviar un recorrido de Gremlin a Neptune como cadena o como código de bytes. El punto de conexión REST y el método submit() del controlador del cliente Java envían los recorridos como cadenas, como en este ejemplo:
client.submit("g.V()")
Las aplicaciones y los controladores de lenguaje que utilizan variantes del lenguaje Gremlin (GLV)
El proceso de conversión del recorrido
El segundo paso para procesar un recorrido es convertir sus TinkerPop pasos en un conjunto de pasos de Neptune convertidos y no convertidos. La mayoría de los pasos del lenguaje de consulta Apache TinkerPop Gremlin se convierten en pasos específicos de Neptuno que están optimizados para ejecutarse en el motor Neptune subyacente. Cuando se encuentra un TinkerPop paso sin un equivalente a Neptuno en un recorrido, el motor de consulta procesa ese paso y todos los pasos subsiguientes del recorrido. TinkerPop
Para obtener más información sobre qué pasos se pueden convertir y en qué circunstancias, consulte Compatibilidad con pasos de Gremlin.
El proceso de optimización de recorridos
El último paso del procesamiento de recorridos consiste en ejecutar la serie de pasos convertidos y no convertidos a través del optimizador para tratar de determinar el mejor plan de ejecución. El resultado de esta optimización es el plan de ejecución que procesa el motor de Neptune.
Uso de la API explain en un recorrido de Gremlin de Neptune para ajustar las consultas
La API de explain de Neptune no es lo mismo que el paso explain() de Gremlin. Devuelve el plan de ejecución final que el motor de Neptune procesaría al ejecutar la consulta. Dado que no realiza ningún procesamiento, devuelve el mismo plan independientemente de los parámetros utilizados y su resultado no contiene estadísticas sobre la ejecución real.
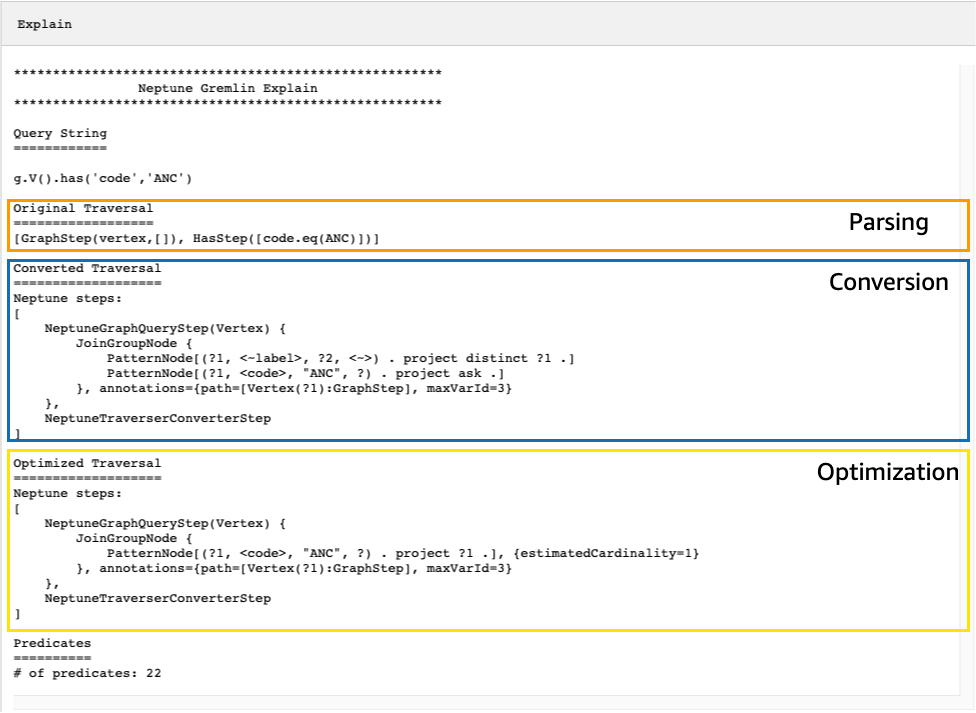
Considere el siguiente recorrido simple que encuentra todos los vértices de los aeropuertos de Anchorage:
g.V().has('code','ANC')
Hay dos formas de ejecutar este recorrido a través de la API explain de Neptune. La primera es hacer una llamada REST al punto de conexión de explain de la siguiente manera:
curl -X POST https://your-neptune-endpoint:port/gremlin/explain -d '{"gremlin":"g.V().has('code','ANC')"}'
La segunda forma es usar la magia de celda %%gremlin del entorno de trabajo de Neptune con el parámetro explain. Esto pasa el recorrido contenido en el cuerpo de la celda a la API explain de Neptune y, a continuación, muestra el resultado al ejecutar la celda:
%%gremlin explain g.V().has('code','ANC')
El resultado de la API explain resultante describe el plan de ejecución de Neptune para el recorrido. Como puede ver en la imagen siguiente, el plan incluye cada uno de los tres pasos de la canalización de procesamiento:
Ajuste de un recorrido observando los pasos que no se convierten
Una de las primeras cosas que hay que buscar en el resultado de la API explain de Neptune son los pasos de Gremlin que no se convierten en pasos nativos de Neptune. En un plan de consulta, cuando se encuentra un paso que no se puede convertir en un paso nativo de Neptune, el servidor de Gremlin procesa este paso y todos los pasos subsiguientes del plan.
En el ejemplo anterior, se convirtieron todos los pasos del recorrido. Examinemos el resultado de la API de explain para este recorrido:
g.V().has('code','ANC').out().choose(hasLabel('airport'), values('code'), constant('Not an airport'))
Como puede ver en la imagen de abajo, Neptune no pudo convertir el paso choose():
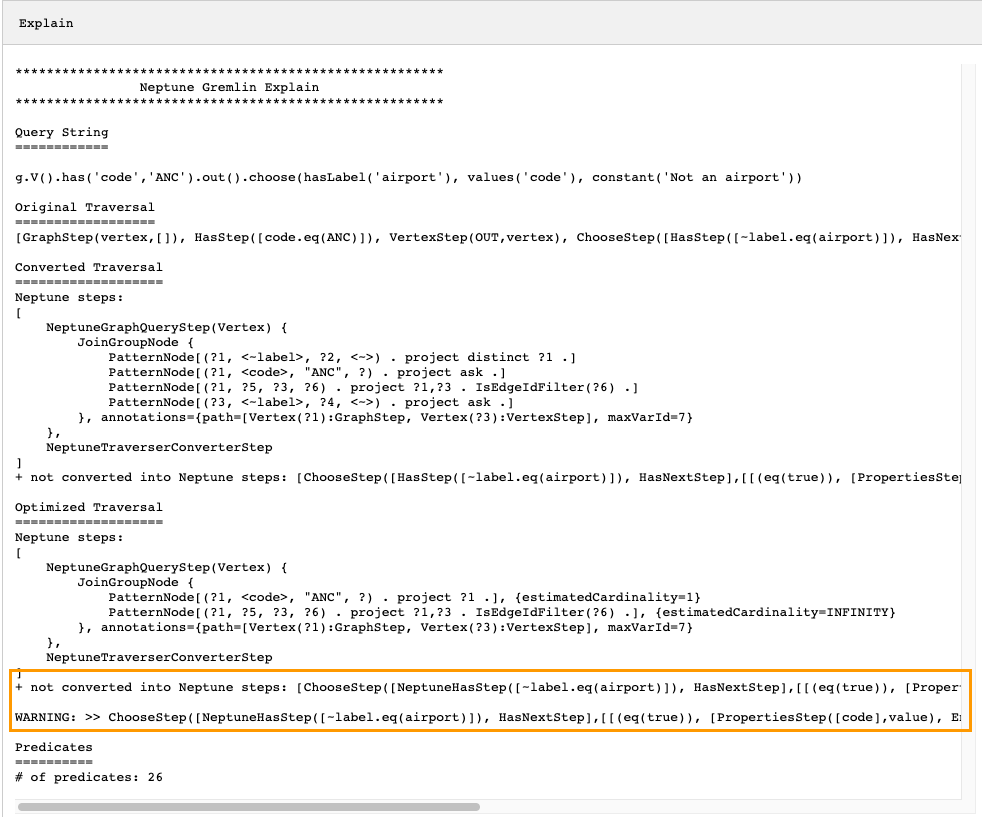
Hay varias cosas que puede hacer para ajustar el rendimiento del recorrido. La primera sería reescribirlo de tal manera que se elimine el paso que no se pudo convertir. Otra sería mover el paso al final del recorrido para que todos los demás pasos se puedan convertir en pasos nativos.
No siempre es necesario ajustar un plan de consultas con pasos que no estén convertidos. Si los pasos que no se pueden convertir se encuentran al final del recorrido y están relacionados con el formato de la salida y no con la forma en que se recorre el gráfico, es posible que no afecten mucho al rendimiento.
Otra cosa que hay que tener en cuenta al examinar los resultados de la API de explain de Neptune son los pasos que no utilizan índices. En el siguiente recorrido, se muestran todos los aeropuertos con vuelos que aterrizan en Anchorage:
g.V().has('code','ANC').in().values('code')
La salida de la API de explain para este recorrido es:
******************************************************* Neptune Gremlin Explain ******************************************************* Query String ============ g.V().has('code','ANC').in().values('code') Original Traversal ================== [GraphStep(vertex,[]), HasStep([code.eq(ANC)]), VertexStep(IN,vertex), PropertiesStep([code],value)] Converted Traversal =================== Neptune steps: [ NeptuneGraphQueryStep(PropertyValue) { JoinGroupNode { PatternNode[(?1, <~label>, ?2, <~>) . project distinct ?1 .] PatternNode[(?1, <code>, "ANC", ?) . project ask .] PatternNode[(?3, ?5, ?1, ?6) . project ?1,?3 . IsEdgeIdFilter(?6) .] PatternNode[(?3, <~label>, ?4, <~>) . project ask .] PatternNode[(?3, ?7, ?8, <~>) . project ?3,?8 . ContainsFilter(?7 in (<code>)) .] }, annotations={path=[Vertex(?1):GraphStep, Vertex(?3):VertexStep, PropertyValue(?8):PropertiesStep], maxVarId=9} }, NeptuneTraverserConverterStep ] Optimized Traversal =================== Neptune steps: [ NeptuneGraphQueryStep(PropertyValue) { JoinGroupNode { PatternNode[(?1, <code>, "ANC", ?) . project ?1 .], {estimatedCardinality=1} PatternNode[(?3, ?5, ?1, ?6) . project ?1,?3 . IsEdgeIdFilter(?6) .], {estimatedCardinality=INFINITY} PatternNode[(?3, ?7=<code>, ?8, <~>) . project ?3,?8 .], {estimatedCardinality=7564} }, annotations={path=[Vertex(?1):GraphStep, Vertex(?3):VertexStep, PropertyValue(?8):PropertiesStep], maxVarId=9} }, NeptuneTraverserConverterStep ] Predicates ========== # of predicates: 26 WARNING: reverse traversal with no edge label(s) - .in() / .both() may impact query performance
El mensaje WARNING en la parte inferior de la salida se produce porque el paso in() del recorrido no se puede gestionar con uno de los 3 índices que mantiene Neptune (consulte Cómo se indexan las instrucciones en Neptune y Instrucciones de Gremlin en Neptune). Como el paso in() no contiene ningún filtro de bordes, no se puede resolver mediante el índice SPOG, POGS o GPSO. En cambio, Neptune debe realizar un escaneo de unión para encontrar los vértices solicitados, lo cual es mucho menos eficiente.
Hay dos formas de ajustar el recorrido en esta situación. La primera consiste en añadir uno o más criterios de filtrado al paso in() para poder utilizar una búsqueda indexada para resolver la consulta. Para el ejemplo anterior, esto podría ser:
g.V().has('code','ANC').in('route').values('code')
La salida de la API explain de Neptune para el recorrido revisado ya no contiene el mensaje WARNING:
******************************************************* Neptune Gremlin Explain ******************************************************* Query String ============ g.V().has('code','ANC').in('route').values('code') Original Traversal ================== [GraphStep(vertex,[]), HasStep([code.eq(ANC)]), VertexStep(IN,[route],vertex), PropertiesStep([code],value)] Converted Traversal =================== Neptune steps: [ NeptuneGraphQueryStep(PropertyValue) { JoinGroupNode { PatternNode[(?1, <~label>, ?2, <~>) . project distinct ?1 .] PatternNode[(?1, <code>, "ANC", ?) . project ask .] PatternNode[(?3, ?5, ?1, ?6) . project ?1,?3 . IsEdgeIdFilter(?6) . ContainsFilter(?5 in (<route>)) .] PatternNode[(?3, <~label>, ?4, <~>) . project ask .] PatternNode[(?3, ?7, ?8, <~>) . project ?3,?8 . ContainsFilter(?7 in (<code>)) .] }, annotations={path=[Vertex(?1):GraphStep, Vertex(?3):VertexStep, PropertyValue(?8):PropertiesStep], maxVarId=9} }, NeptuneTraverserConverterStep ] Optimized Traversal =================== Neptune steps: [ NeptuneGraphQueryStep(PropertyValue) { JoinGroupNode { PatternNode[(?1, <code>, "ANC", ?) . project ?1 .], {estimatedCardinality=1} PatternNode[(?3, ?5=<route>, ?1, ?6) . project ?1,?3 . IsEdgeIdFilter(?6) .], {estimatedCardinality=32042} PatternNode[(?3, ?7=<code>, ?8, <~>) . project ?3,?8 .], {estimatedCardinality=7564} }, annotations={path=[Vertex(?1):GraphStep, Vertex(?3):VertexStep, PropertyValue(?8):PropertiesStep], maxVarId=9} }, NeptuneTraverserConverterStep ] Predicates ========== # of predicates: 26
Otra opción si ejecuta muchos recorridos de este tipo es ejecutarlos en un clúster de base de datos de Neptune que tenga habilitado el índice OSGP opcional (consulte Habilitación de un índice OSGP). Habilitar un índice OSGP tiene sus inconvenientes:
Debe habilitarse en un clúster de base de datos antes de cargar cualquier dato.
Las tasas de inserción de vértices y bordes pueden disminuir hasta un 23 %.
El uso del almacenamiento aumentará en torno a un 20 %.
Es posible que en las consultas de lectura que dispersan las solicitudes en todos los índices aumente la latencia.
Tener un índice OSGP tiene mucho sentido en un conjunto restringido de patrones de consulta, pero a menos que los utilice con frecuencia, suele ser preferible asegurarse de que los recorridos que escribe se puedan resolver utilizando los tres índices principales.
Uso de una gran cantidad de predicados
Neptune trata cada etiqueta de borde y cada nombre de propiedad de vértice o borde distinto del gráfico como un predicado y está diseñado de forma predeterminada para funcionar con un número relativamente bajo de predicados distintos. Cuando hay más de unos pocos miles de predicados en los datos de gráficos, el rendimiento podría degradarse.
La salida de explain de Neptune le avisará si es así:
Predicates ========== # of predicates: 9549 WARNING: high predicate count (# of distinct property names and edge labels)
Si no es conveniente reelaborar el modelo de datos para reducir el número de etiquetas y propiedades y, por lo tanto, el número de predicados, la mejor manera de ajustar los recorridos es ejecutarlos en un clúster de base de datos que tenga el índice OSGP habilitado, como se ha explicado anteriormente.
Uso de la API de profile de Gremlin de Neptune para ajustar los recorridos
La API profile de Neptune es muy diferente del paso profile() de Gremlin. Al igual que la API de explain, su salida incluye el plan de consultas que utiliza el motor de Neptune al ejecutar el recorrido. Además, la salida de profile incluye estadísticas de ejecución reales del recorrido, teniendo en cuenta cómo están configurados sus parámetros.
De nuevo, tomemos como ejemplo el recorrido simple que encuentra todos los vértices del aeropuerto de Anchorage:
g.V().has('code','ANC')
Al igual que con la API de explain, puede invocar a la API de profile mediante una llamada REST:
curl -X POST https://your-neptune-endpoint:port/gremlin/profile -d '{"gremlin":"g.V().has('code','ANC')"}'
También se puede usar la magia de celda %%gremlin del entorno de trabajo de Neptune con el parámetro profile. Esto pasa el recorrido contenido en el cuerpo de la celda a la API de profile de Neptune y, a continuación, muestra el resultado al ejecutar la celda:
%%gremlin profile g.V().has('code','ANC')
La salida de la API de profile resultante contiene tanto el plan de ejecución de Neptune para el recorrido como las estadísticas sobre la ejecución del plan, como puede ver en esta imagen:
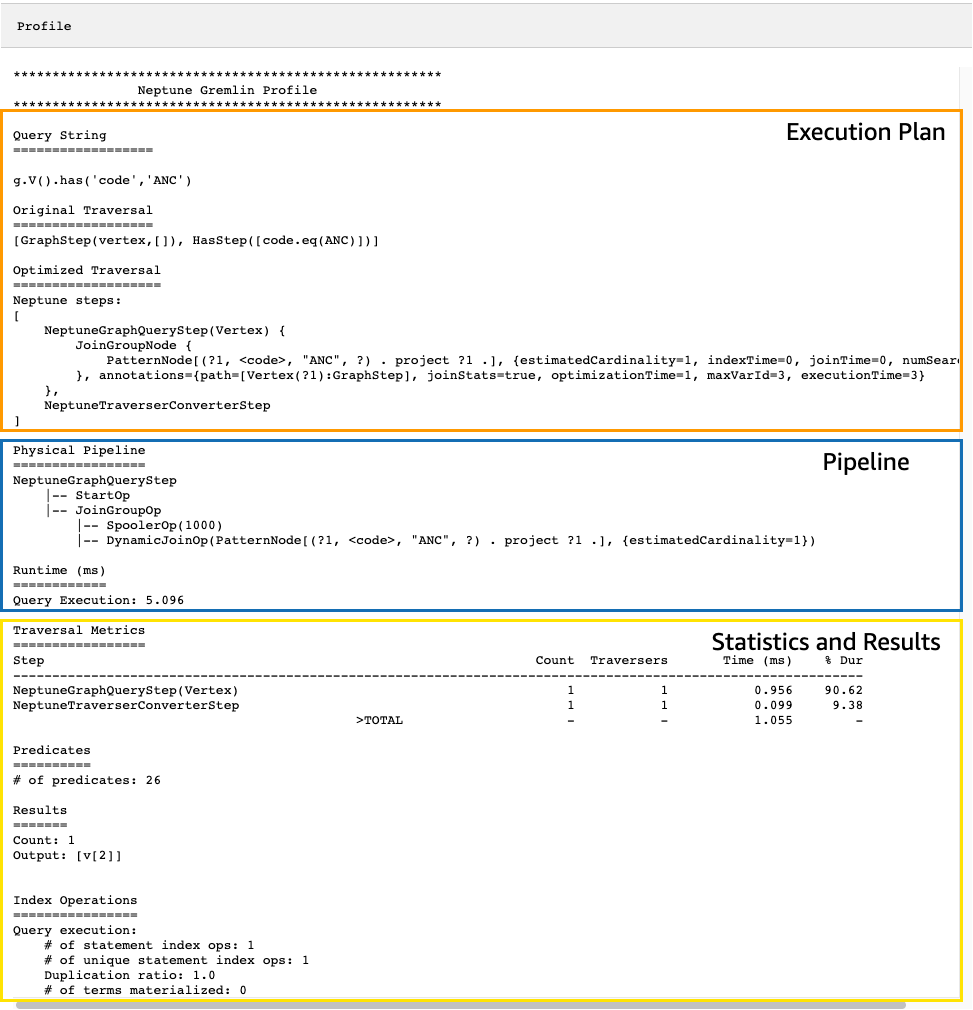
En la salida de profile, la sección del plan de ejecución solo contiene el plan de ejecución final para el recorrido, no los pasos intermedios. La sección de canalización contiene las operaciones físicas de la canalización que se realizaron, así como el tiempo real (en milisegundos) que ha tardado la ejecución del recorrido. La métrica del tiempo de ejecución es extremadamente útil para comparar los tiempos que tardan dos versiones diferentes de un recorrido a medida que se optimizan.
nota
El tiempo de ejecución inicial de un recorrido suele ser mayor que el de los tiempos de ejecución posteriores, ya que el primero hace que los datos relevantes se almacenen en caché.
La tercera sección de la salida de profile contiene las estadísticas de ejecución y los resultados del recorrido. Para ver cómo esta información puede resultar útil para ajustar un recorrido, considere el siguiente recorrido, en el que se encuentran todos los aeropuertos cuyo nombre comienza por "Anchora" y todos los aeropuertos a los que se puede llegar en dos saltos desde esos aeropuertos, y se devuelven los códigos del aeropuerto de vuelta, las rutas de los vuelos y las distancias:
%%gremlin profile g.withSideEffect("Neptune#fts.endpoint", "{your-OpenSearch-endpoint-URL"). V().has("city", "Neptune#fts Anchora~"). repeat(outE('route').inV().simplePath()).times(2). project('Destination', 'Route'). by('code'). by(path().by('code').by('dist'))
Métricas de recorrido en la salida de la API de profile de Neptune
El primer conjunto de métricas que está disponible en todas las salidas de profile es el de las métricas de recorrido. Son similares a las métricas de pasos de profile() de Gremlin, con algunas diferencias:
Traversal Metrics ================= Step Count Traversers Time (ms) % Dur ------------------------------------------------------------------------------------------------------------- NeptuneGraphQueryStep(Vertex) 3856 3856 91.701 9.09 NeptuneTraverserConverterStep 3856 3856 38.787 3.84 ProjectStep([Destination, Route],[value(code), ... 3856 3856 878.786 87.07 PathStep([value(code), value(dist)]) 3856 3856 601.359 >TOTAL - - 1009.274 -
La primera columna de la tabla de métricas de recorrido muestra los pasos que ha ejecutado el recorrido. Los dos primeros pasos son generalmente los pasos específicos de Neptune, NeptuneGraphQueryStep y NeptuneTraverserConverterStep.
NeptuneGraphQueryStep representa el tiempo de ejecución de toda la parte del recorrido que el motor de Neptune podría convertir y ejecutar de forma nativa.
NeptuneTraverserConverterSteprepresenta el proceso de convertir la salida de esos pasos convertidos en TinkerPop travesaños que permiten procesar los pasos que no se pudieron convertir, si los hubiera, o devolver los resultados en un formato compatible. TinkerPop
En el ejemplo anterior, tenemos varios pasos no convertidos, por lo que vemos que cada uno de estos TinkerPop pasos (ProjectStep,PathStep) aparece entonces como una fila en la tabla.
En nuestro ejemplo, hay 3856 vértices y 3856 recorridos que devuelve el NeptuneGraphQueryStep, y estos números permanecen iguales durante el resto del procesamiento, porque ProjectStep y PathStep están formateando los resultados, no filtrándolos.
nota
A diferencia TinkerPop, el motor Neptune no optimiza el rendimiento aumentando el volumen en sus NeptuneGraphQueryStep escalones. NeptuneTraverserConverterStep El aumento de volumen es la TinkerPop operación que combina los travesaños en el mismo vértice para reducir la sobrecarga operativa, y eso es lo que hace que los números y los números difieran. Count Traversers Como el aumento de volumen solo ocurre en los pasos en los que Neptuno delega TinkerPop y no en los pasos que Neptuno maneja de forma nativa, Count las columnas y rara vez difieren. Traverser
La columna de Tiempo indica el número de milisegundos que tardó el paso y la columna % Dur indica el porcentaje del tiempo total de procesamiento que tardó el paso. Estas son las métricas que indican dónde centrar el trabajo de ajuste, ya que muestran los pasos que han tardado más tiempo.
Métricas de operaciones de índice en la salida de la API de profile de Neptune
Otro conjunto de métricas en la salida de la API de profile de Neptune son las operaciones de índice:
Index Operations ================ Query execution: # of statement index ops: 23191 # of unique statement index ops: 5960 Duplication ratio: 3.89 # of terms materialized: 0
Estas métricas informan de lo siguiente:
El número total de búsquedas de índices.
El número de búsquedas de índices únicas realizadas.
La relación entre el total de búsquedas en el índice y las búsquedas únicas. Una relación más baja indica menos redundancia.
El número de términos materializados a partir del diccionario de términos.
Métricas de repetición en la salida de la API de profile de Neptune
Si el recorrido utiliza un paso repeat() como en el ejemplo anterior, en la salida de profile aparecerá una sección que contiene las métricas de repetición:
Repeat Metrics ============== Iteration Visited Output Until Emit Next ------------------------------------------------------ 0 2 0 0 0 2 1 53 0 0 0 53 2 3856 3856 3856 0 0 ------------------------------------------------------ 3911 3856 3856 0 55
Estas métricas informan de lo siguiente:
El recuento de bucles de una fila (la columna
Iteration).El número de elementos visitados por el bucle (la columna
Visited).El número de elementos generados por el bucle (la columna
Output).El último elemento generado por el bucle (la columna
Until).El número de elementos emitidos por el bucle (la columna
Emit).El número de elementos que se pasan del bucle al bucle siguiente (la columna
Next).
Estas métricas de repetición son muy útiles para comprender el factor de ramificación del recorrido y así tener una idea del trabajo que está realizando la base de datos. Puede utilizar estos números para diagnosticar problemas de rendimiento, especialmente cuando el mismo recorrido funciona de forma muy diferente con parámetros diferentes.
Métricas de búsqueda de texto completo en la salida de la API profile de Neptune
Cuando un recorrido utiliza una búsqueda de texto completo, como en el ejemplo anterior, en la salida de profile aparece una sección que contiene las métricas de búsqueda de texto completo (FTS):
FTS Metrics ============== SearchNode[(idVar=?1, query=Anchora~, field=city) . project ?1 .], {endpoint=your-OpenSearch-endpoint-URL, incomingSolutionsThreshold=1000, estimatedCardinality=INFINITY, remoteCallTimeSummary=[total=65, avg=32.500000, max=37, min=28], remoteCallTime=65, remoteCalls=2, joinTime=0, indexTime=0, remoteResults=2} 2 result(s) produced from SearchNode above
Aquí se muestra la consulta enviada al clúster ElasticSearch (ES) y se muestran varias métricas sobre la interacción ElasticSearch que pueden ayudarle a identificar los problemas de rendimiento relacionados con la búsqueda de texto completo:
-
Información resumida sobre las llamadas al ElasticSearch índice:
El número total de milisegundos que necesitan todas las remoteCalls para satisfacer la consulta (
total).El número medio de milisegundos empleados en una remoteCall (
avg).El número mínimo de milisegundos empleados en una remoteCall (
min).El número máximo de milisegundos empleados en una remoteCall (
max).
Tiempo total consumido por RemoteCalls to ElasticSearch ()
remoteCallTime.El número de llamadas remotas realizadas a (). ElasticSearch
remoteCallsEl número de milisegundos utilizados en las uniones de ElasticSearch los resultados ()
joinTime.El número de milisegundos empleados en las búsquedas de índices (
indexTime).El número total de resultados devueltos por ElasticSearch (
remoteResults).
