Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Arquitecturas de referencia para Apache Iceberg en AWS
En esta sección se proporcionan ejemplos de cómo aplicar las mejores prácticas en diferentes casos de uso, como la ingesta por lotes y un lago de datos que combina la ingesta de datos por lotes y en streaming.
Ingestión nocturna por lotes
Para este hipotético caso de uso, supongamos que su mesa Iceberg ingiere transacciones con tarjetas de crédito todas las noches. Cada lote contiene solo actualizaciones incrementales, que deben combinarse en la tabla de destino. Varias veces al año, se reciben datos históricos completos. Para este escenario, recomendamos la arquitectura y las configuraciones siguientes.
Nota: Esto es solo un ejemplo. La configuración óptima depende de sus datos y requisitos.
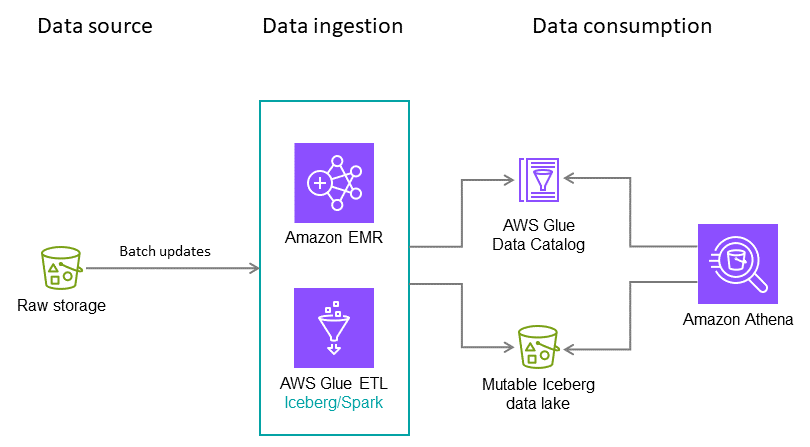
Recomendaciones:
-
Tamaño del archivo: 128 MB, porque las tareas de Apache Spark procesan los datos en fragmentos de 128 MB.
-
Tipo de escritura: copy-on-write. Como se detalló anteriormente en esta guía, este enfoque ayuda a garantizar que los datos se escriban de forma optimizada para la lectura.
-
Variables de partición: año/mes/día. En nuestro caso de uso hipotético, consultamos los datos recientes con mayor frecuencia, aunque en ocasiones realizamos escaneos completos de tablas de los datos de los últimos dos años. El objetivo del particionamiento es impulsar las operaciones de lectura rápida en función de los requisitos del caso de uso.
-
Orden de clasificación: marca de tiempo
-
Catálogo de datos: AWS Glue Data Catalog
Lago de datos que combina la ingesta por lotes y la ingesta casi en tiempo real
Puede aprovisionar un lago de datos en Amazon S3 que comparta datos por lotes y en streaming entre cuentas y regiones. Para ver un diagrama de arquitectura y detalles, consulte la entrada del AWS blog Cree un lago de datos transaccional con Apache Iceberg y comparta datos entre cuentas con Amazon AWS Lake Formation Athena
