Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Arquitectura de referencia
El siguiente diagrama muestra el flujo de trabajo después de aplicar la solución automatizada de esta guía a un informe de operaciones diario. Cuando se ingieren nuevos archivos en Amazon Simple Storage Service (Amazon S3), se pueden visualizar inmediatamente en QuickSight un panel de control una vez procesados.
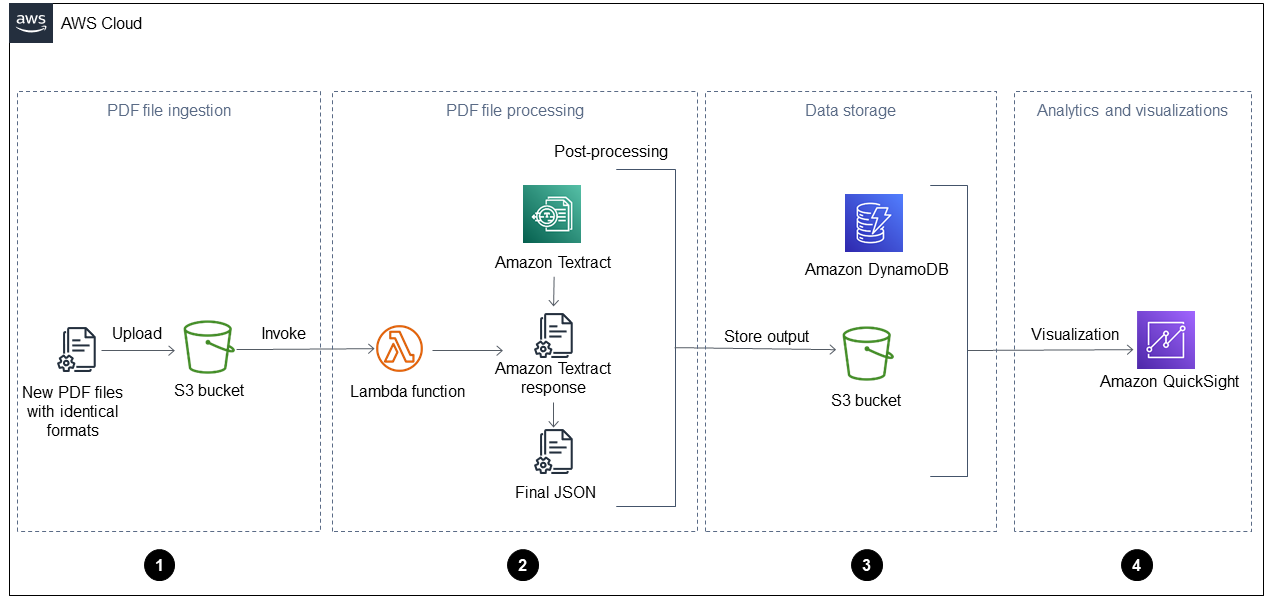
El diagrama muestra las cuatro fases siguientes:
-
Ingesta de archivos PDF: la aplicación ingiere automáticamente nuevos archivos PDF con un formato idéntico (por ejemplo, un informe de operaciones diario) en un bucket de Amazon Simple Storage Service (Amazon S3). Amazon S3 inicia un
ObjectCreatedevento cuando se añaden nuevos archivos PDF al bucket y esto invoca una AWS Lambda función. Para obtener más información al respecto, consulte Uso de un disparador de Amazon S3 para invocar una función Lambda en la documentación de Amazon S3. -
Procesamiento de archivos PDF: la función Lambda envía un archivo PDF a Amazon Textract, que extrae el contenido. Un script de posprocesamiento ejecuta y analiza la respuesta de Amazon Textract y utiliza una plantilla predefinida para este tipo de archivo PDF. Esta plantilla contiene los atributos correctos y ayuda a extraer correctamente todos los pares clave-valor, las tablas y otro texto sin procesar. Para obtener más información al respecto, consulte el patrón Extraer contenido automáticamente de archivos PDF con Amazon Textract en el sitio web de orientación AWS prescriptiva.
-
Almacenamiento de datos: los datos extraídos y corregidos se almacenan en una tabla de Amazon DynamoDB, además de en un archivo JSON para cada archivo PDF. Los archivos JSON se almacenan en un depósito de S3 que pueden utilizar los servicios de procesamiento y análisis posteriores, como Amazon Athena QuickSighto Amazon SageMaker AI.
-
Análisis y visualizaciones: QuickSight analiza los datos y crea visualizaciones que ayudan a generar información sobre todos los archivos PDF procesados. Una vez creados los paneles QuickSight, puede compartirlos con sus usuarios finales y equipos empresariales.
Consideraciones
La solución de esta guía es adecuada para procesar archivos PDF con un formato idéntico y un diseño uniforme de formularios y tablas. Sin embargo, debe definir una plantilla y editarla con antelación para automatizar completamente el proceso y hacer que los datos extraídos estén disponibles para su análisis. A continuación, esta plantilla se utiliza durante el procesamiento con la función Lambda.
Aunque esta solución se puede aplicar a distintos tipos de archivos PDF al mismo tiempo, debe crear y definir plantillas independientes para cada tipo de archivo PDF y almacenarlas en una ubicación accesible (por ejemplo, Amazon S3). Le recomendamos que utilice un identificador único para cada tipo de archivo PDF, como el nombre de un archivo PDF o distintas carpetas del bucket de S3. La función Lambda puede entonces llamar a la plantilla adecuada al procesar el tipo de archivo PDF.
