Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Catálogo centralizado
El siguiente diagrama muestra cómo el catálogo centralizado conecta a los productores y consumidores de datos en el lago de datos.
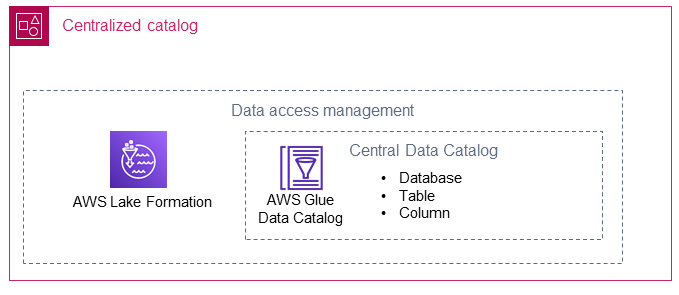
El catálogo centralizado almacena y administra el catálogo de datos compartido para las cuentas de los productores de datos. El catálogo centralizado también aloja los metadatos técnicos de los datos compartidos (por ejemplo, el nombre y el esquema de la tabla) y es el lugar donde los consumidores de datos acceden a los datos.
Los consumidores de datos pueden acceder a los datos de varios productores de datos del catálogo centralizado y, a continuación, mezclar estos datos con los suyos propios para su posterior procesamiento. El uso de un catálogo centralizado elimina la necesidad de que los consumidores de datos se conecten directamente con diferentes productores de datos y reduce la sobrecarga operativa.
Dado que el catálogo centralizado permite ver el intercambio y el consumo de datos por parte de los productores y consumidores de datos, puede ser un lugar ideal para aplicar las funciones de gobierno centralizado de los datos (por ejemplo, la auditoría de acceso).
En las siguientes secciones se describe cómo el catálogo centralizado utiliza AWS Lake Formation y AWS Glue.
AWS Lake Formation
AWS Lake Formationayuda a crear bases de AWS Glue datos en un catálogo de datos que apuntan a las ubicaciones de varios productores de datos en su lago de datos. Se crea un rol AWS Identity and Access Management (IAM) para Lake Formation en el catálogo centralizado. Al usar Lake Formation, el catálogo centralizado puede compartir recursos de datos de forma selectiva (por ejemplo, bases de datos, tablas o columnas) con los consumidores de datos. Los recursos gestionados por Lake Formation se comparten con los consumidores de datos mediante uno de los dos métodos siguientes:
-
Método de recurso con nombre asignado: este método comparte los recursos administrados entre las cuentas. Se deben especificar los nombres de las bases de datos, tablas o columnas y un recurso se puede compartir con una organización, unidad organizativa (OU) o Cuenta de AWS. Para reducir los gastos de uso compartido y administración, le recomendamos que comparta los recursos en niveles más altos siempre que sea posible (por ejemplo, en una organización o unidad organizativa en lugar de en una Cuenta de AWS). Sin embargo, debe asegurarse de que este enfoque cumpla con los requisitos de control de seguridad de los datos de su organización.
-
Nota: Este método funciona bien para los consumidores de datos con un tipo de aplicación, en el que los AWS servicios consumen datos del productor de datos. El requisito de acceso a los datos de este tipo de consumidor de datos depende de las aplicaciones, es prescriptivo y relativamente estático.
-
-
Método de control de acceso basado en etiquetas (LF-TBAC) de Lake Formation: el LF-TBAC es particularmente útil para los consumidores de datos con un tipo de servidor de datos. Sin embargo, los recursos etiquetados como Lake Formation actualmente solo se pueden compartir a Cuenta de AWS nivel y no a nivel de organización o unidad organizativa.
AWS Glue
Debe crear bases de datos AWS Glue para cada productor de datos de su catálogo centralizado. Como el catálogo centralizado suele AWS Glue alojar bases de datos de todos los productores de datos, debe asegurarse de que el nombre de la base de datos sea único en todos los productores de datos y de que refleje al productor de datos y su tipo de datos. Por ejemplo, puede usar la siguiente estructura de nomenclatura de bases de datos: <Data_Producer>–<Environment>–<Data_Group>
-
<Data_Producer>— El nombre del productor de datos. -
<Environment>— El entorno del lago de datos,devpor ejemplo, un entorno de desarrollo,situn entorno de pruebas de integración de sistemas oprodun entorno de producción. -
<Data_Group>— El nombre del grupo de datos que se utiliza para separar los datos de un productor de datos en grupos lógicos. Puede utilizar el nombre, el identificador o la abreviatura del sistema de origen como nombre. Una descripción de la base de datos también ayuda a describir el contenido y el propósito de la base de datos.
Puede utilizar un AWS Glue rastreador de los datos del productor de datos para mantener su esquema en la base de datos del catálogo centralizado. Si un productor de datos crea datos con regularidad con la misma frecuencia, puede utilizar un único AWS Glue rastreador. En todos los demás casos, debe utilizar varios AWS Glue rastreadores para adaptarse a diferentes frecuencias de rastreo. Según el caso de uso empresarial, el rastreador puede programarse para una frecuencia predefinida o iniciarse a partir de eventos.
También puedes mantener el esquema de la tabla AWS Glue llamando a la AWS Glue API para crear o actualizar el esquema. Si bien esto puede proporcionar flexibilidad, se requiere un esfuerzo adicional para el desarrollo y el mantenimiento del código. Asegúrese de evaluar el caso de uso y el valor empresarial y, a continuación, elija la opción que cumpla con sus requisitos y tenga los menores gastos generales.
