Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Desafíos de escalado comunes
Un lago de datos pasa por varias etapas cuando sus datos crecen después de la implementación inicial. Si no utilizó una arquitectura escalable para diseñar su lago de datos, su organización podría enfrentarse a desafíos y verse perjudicada por el crecimiento del lago de datos.
En las siguientes secciones se explica cómo el crecimiento de un lago de datos típico puede provocar problemas de escalado.
Despliegue inicial de un lago de datos
El siguiente diagrama muestra la arquitectura de un lago de datos después de su implementación inicial por parte de la línea de negocio A.
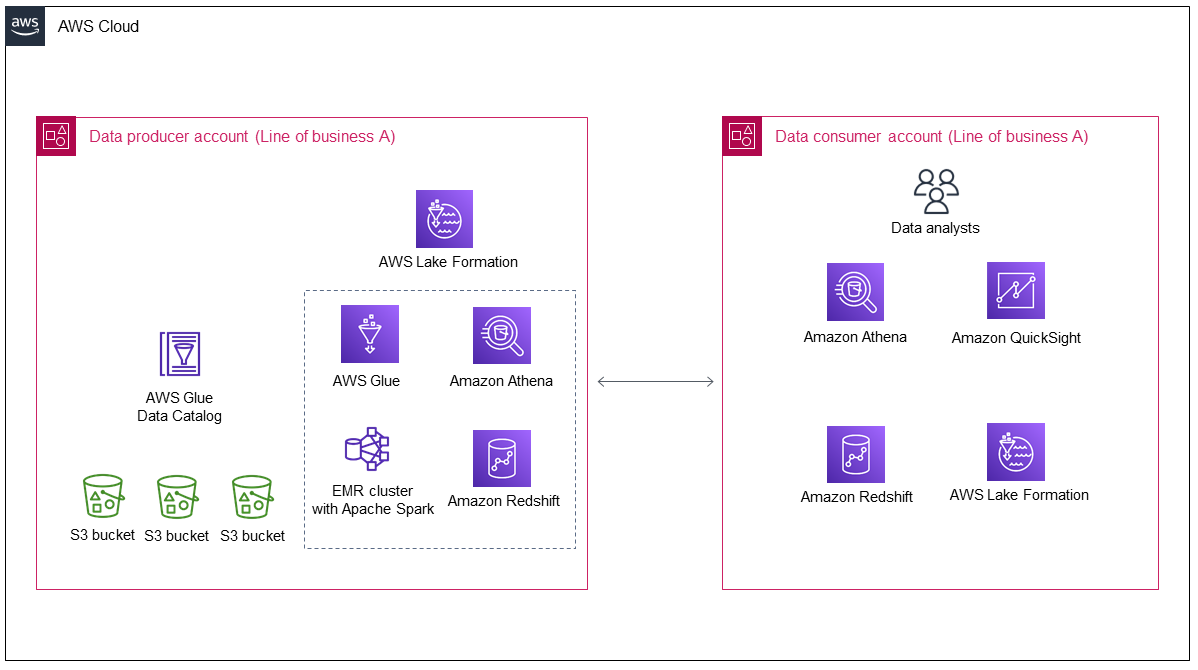
El diagrama muestra los siguientes componentes:
-
La cuenta del productor de datos recopila y procesa los datos, almacena los datos procesados y los prepara para su consumo.
-
Los datos de la cuenta del productor de datos se almacenan en depósitos de Amazon Simple Storage Service (Amazon S3), que pueden tener varias capas de datos.
-
Puede utilizar AWS servicios para el procesamiento de datos (por ejemplo, AWS GlueAmazon EMR).
-
El productor de datos no solo produce y almacena datos en el lago de datos, sino que también debe decidir qué datos compartir con un consumidor de datos y cómo compartirlos. AWS Lake Formation gestiona el lago de datos en la cuenta del productor de datos, además de gestionar el intercambio de datos entre cuentas desde el productor hasta el consumidor de datos.
-
La cuenta del consumidor de datos consume los datos compartidos de la cuenta del productor de datos para casos de uso empresarial específicos.
Los consumidores de datos aumentan
El siguiente diagrama muestra que se incorporan más datos al lago de datos cuando aumentan los datos de la línea de negocio A. Luego, el lago de datos atrae a más consumidores de datos para aprovecharlos y obtener valor de los datos.
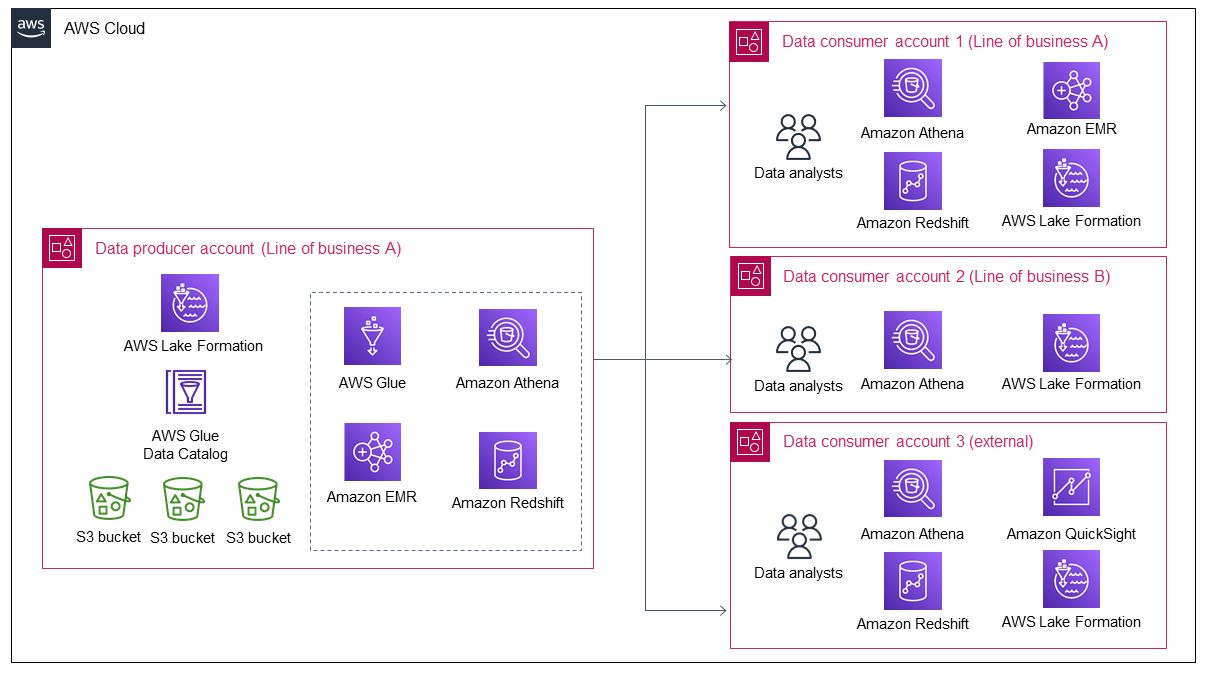
El diagrama muestra cómo una organización genera valor casi continuo a partir de un activo de datos existente y cómo esto atrae a más consumidores de datos. Sin embargo, cuando los consumidores de datos aumentan, el productor de datos solo tiene las dos opciones siguientes para adaptarse a este crecimiento:
-
Gestione manualmente el intercambio de datos y el acceso por parte de los consumidores de datos individuales, lo que no es un enfoque escalable.
-
Desarrolle un proceso automatizado o semiautomatizado para compartir datos y administrar el acceso a los datos. Si bien esta podría ser una opción escalable, su diseño y construcción requieren mucho tiempo y esfuerzo, ya que los consumidores de datos internos y externos tienen diferentes requisitos de control de seguridad. En el futuro, también se requerirán más tiempo y esfuerzos para cualquier mejora de la solución.
Los productores de datos aumentan
El siguiente diagrama muestra la arquitectura del lago de datos cuando varias líneas de negocio se unen como productoras de datos.
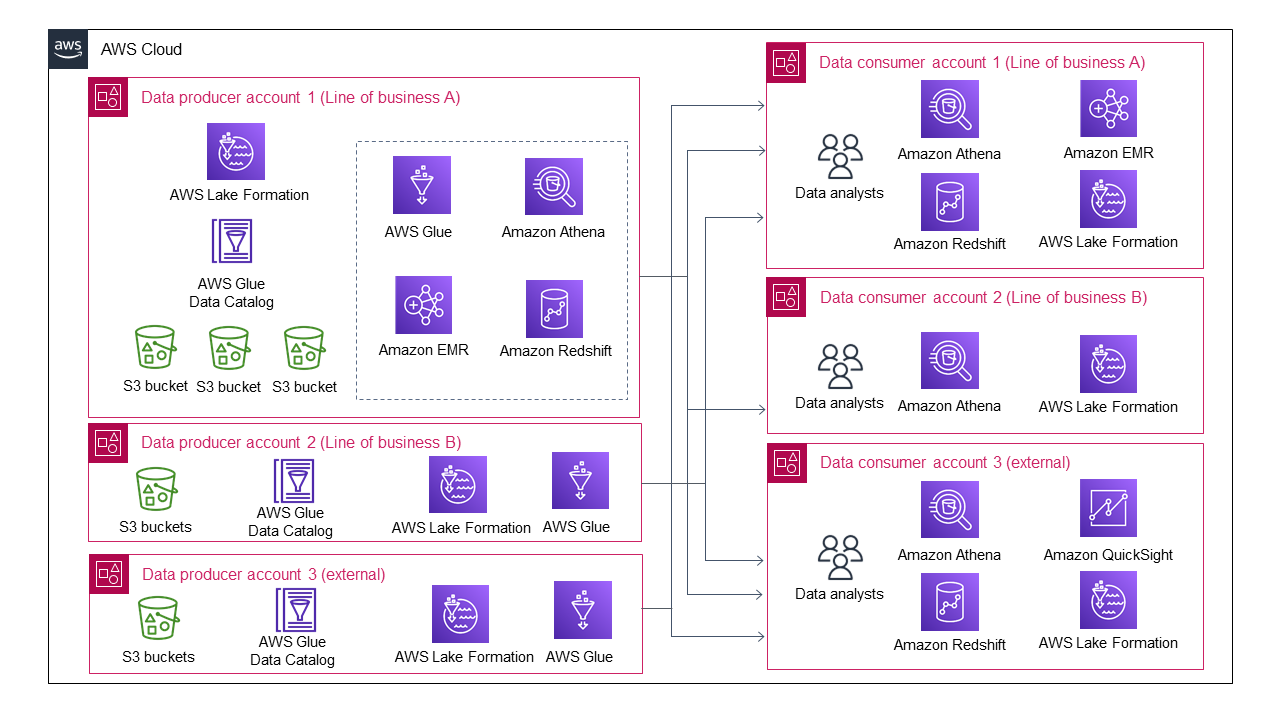
La arquitectura del lago de datos se vuelve cada vez más complicada, incluso con solo tres productores y tres consumidores de datos.
Cada productor de datos debe gestionar el intercambio y el acceso a los datos para varios consumidores de datos. No es realista esperar que todos los productores de datos desarrollen un proceso automatizado o semiautomatizado para el intercambio de datos y la gestión del acceso a los datos. Es posible que algunos productores de datos opten por no compartirlos y, por lo tanto, evitar una sobrecarga de administración inasumible. Del mismo modo, cada consumidor de datos necesita interactuar con varios productores de datos para comprender sus diferentes procesos de consumo de datos. Esto significa que los consumidores de datos individuales se enfrentan a una sobrecarga de administración cada vez mayor al gestionar diferentes patrones de intercambio de datos.
En muchas organizaciones, este lago de datos provoca cuellos de botella y no puede crecer ni escalar. Esto puede significar que su organización deba rediseñar y reconstruir su lago de datos para eliminar el cuello de botella, lo que puede costar mucho tiempo, recursos y dinero.
