Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Modo de escritura en su región (principal mixto)
El modo de escritura en su región asigna distintos subconjuntos de datos a distintas regiones de origen y permite realizar operaciones de escritura en un elemento únicamente a través de su región de origen. Este modo es activo-pasivo, pero asigna la región activa en función del elemento. Cada región es principal para su propio conjunto de datos que no se superponga, y las operaciones de escritura deben estar protegidas para garantizar la ubicación adecuada.
Este modo es similar al de escribir en una región, excepto que permite operaciones de escritura de menor latencia, ya que los datos asociados a cada usuario se pueden colocar más cerca de la red de ese usuario. También distribuye la infraestructura circundante de manera más uniforme entre las regiones y requiere menos trabajo para construir la infraestructura durante un escenario de conmutación por error, ya que todas las regiones tienen una parte de su infraestructura ya activa.
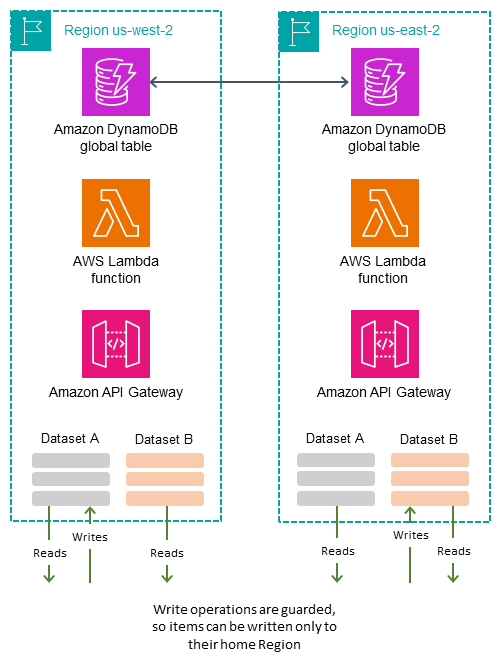
Puede determinar la región de origen de los elementos de varias maneras:
-
Intrínseco: algún aspecto de los datos, como un atributo especial o un valor incrustado en su clave de partición, aclara la región de origen. Esta técnica se describe en la entrada del blog Use Region Pinning para establecer una región de inicio para los artículos de una tabla global de Amazon DynamoDB
. -
Negociado: la región de origen de cada conjunto de datos se negocia de alguna manera externa, por ejemplo, con un servicio global independiente que mantiene las asignaciones. La asignación puede tener una duración limitada, después de la cual está sujeta a renegociación.
-
Orientado a tablas: en lugar de crear una única tabla global replicante, se crea el mismo número de tablas globales que las regiones replicantes. El nombre de cada tabla indica su región de origen. En las operaciones estándar, todos los datos se escriben en la región de origen, mientras que las demás regiones conservan una copia de solo lectura. Durante una conmutación por error, otra región adopta temporalmente tareas de escritura para esa tabla.
Por ejemplo, imagina que trabajas para una empresa de juegos. Necesitas operaciones de lectura y escritura de baja latencia para todos los jugadores de todo el mundo. Asignas a cada jugador a la región que esté más cerca de él. Esa región realiza todas sus operaciones de lectura y escritura, lo que garantiza una gran read-after-write coherencia. Sin embargo, cuando un jugador viaja o si su región de origen sufre una interrupción, hay una copia completa de sus datos disponible en otras regiones y se le puede asignar al jugador a una región de origen diferente.
Como otro ejemplo, imagina que trabajas en una empresa de videoconferencias. Los metadatos de cada conferencia telefónica se asignan a una región concreta. Las personas que llaman pueden usar la región más cercana a ellas para obtener la latencia más baja. Si se produce una interrupción en una región, el uso de tablas globales permite una recuperación rápida, ya que el sistema puede trasladar el procesamiento de la llamada a otra región en la que ya existe una copia replicada de los datos.
