Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Cobertura y precisión de los documentos: en el dominio
Comparamos el rendimiento predictivo de los conjuntos profundos con dropout aplicado en el momento de la prueba, MC dropout y una función softmax ingenua, tal como se muestra en el siguiente gráfico. Tras la inferencia, las predicciones con las incertidumbres más altas se descartaron en diferentes niveles. La cobertura de datos restante osciló entre el 10 % y el 100 %. Esperábamos que el conjunto profundo identificara de manera más eficiente las predicciones inciertas debido a su mayor capacidad para cuantificar la incertidumbre epistémica, es decir, para identificar las regiones de los datos en las que el modelo cuenta con menos experiencia. Esto debería arrojar una mayor precisión en los diferentes niveles de cobertura de datos. Por cada conjunto profundo, usamos 5 modelos y aplicamos la inferencia 20 veces. En MC dropout, aplicamos la inferencia 100 veces para cada modelo. Usamos el mismo conjunto de hiperparámetros y la misma arquitectura de modelo con cada método.
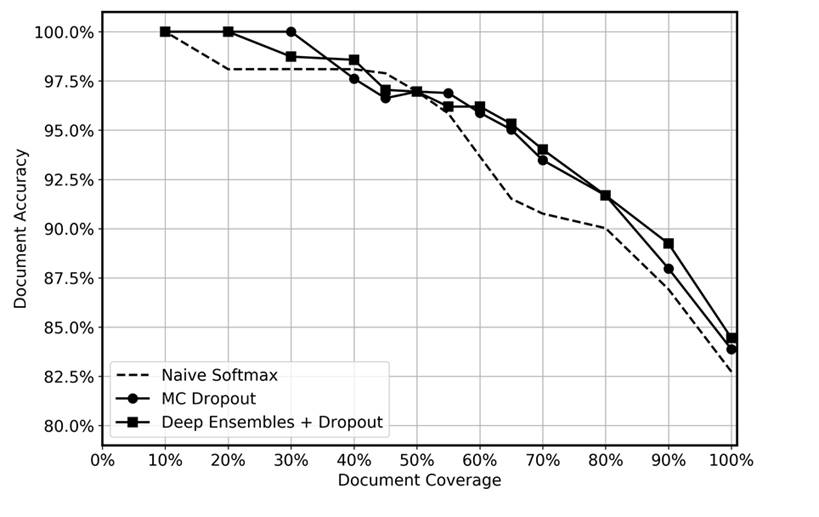
El gráfico parece mostrar una ligera ventaja al emplear conjuntos profundos y MC dropout en comparación con softmax ingenuo. Esto es más notable en el rango de cobertura de datos del 50 al 80 %. ¿Por qué no es mayor? Como se mencionó en la sección de conjuntos profundos, la fortaleza de los conjuntos profundos proviene de las diferentes trayectorias de pérdida adoptadas. En esta situación, utilizamos modelos previamente entrenados. Aunque perfeccionamos todo el modelo, la inmensa mayoría de las ponderaciones se inicializan a partir del modelo previamente entrenado, y solo unas pocas capas ocultas se inicializan aleatoriamente. En consecuencia, conjeturamos que el entrenamiento previo de grandes modelos puede provocar un exceso de confianza debido a la escasa diversificación. Hasta donde sabemos, la eficacia de los conjuntos profundos no se ha probado previamente en escenarios de aprendizaje por transferencia, y consideramos que esta es un área interesante para futuras investigaciones.
