Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Monte Carlo dropout
Una de las formas más populares de estimar la incertidumbre es inferir distribuciones predictivas con redes neuronales bayesianas. Para indicar una distribución predictiva, utilice:

con objetivos
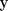 , aportaciones
, aportaciones
 y
y
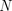 muchos ejemplos de formación
muchos ejemplos de formación
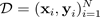 . Cuando obtiene una distribución predictiva, puede inspeccionar la varianza y descubrir la incertidumbre. Una forma de conocer una distribución predictiva requiere aprender una distribución entre funciones o, de manera equivalente, una distribución sobre los parámetros (es decir, la distribución paramétrica posterior)
. Cuando obtiene una distribución predictiva, puede inspeccionar la varianza y descubrir la incertidumbre. Una forma de conocer una distribución predictiva requiere aprender una distribución entre funciones o, de manera equivalente, una distribución sobre los parámetros (es decir, la distribución paramétrica posterior)
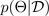 .
.
La técnica de abandono de Montecarlo (MC) (Gal y Ghahramani, 2016) proporciona una forma escalable de aprender una distribución predictiva. El MC dropout funciona apagando aleatoriamente las neuronas de una red neuronal, lo que regulariza la red. Cada configuración de abandono corresponde a una muestra diferente de la distribución posterior paramétrica aproximada:
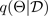
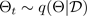
donde
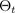 corresponde a una configuración de abandono o, de manera equivalente, a una simulación ~, muestreada a partir de la parte posterior paramétrica aproximada
, como se muestra en la siguiente figura. El muestreo de la parte posterior aproximada
permite integrar en Montecarlo la probabilidad del modelo, lo que permite descubrir la distribución predictiva, de la siguiente manera:
corresponde a una configuración de abandono o, de manera equivalente, a una simulación ~, muestreada a partir de la parte posterior paramétrica aproximada
, como se muestra en la siguiente figura. El muestreo de la parte posterior aproximada
permite integrar en Montecarlo la probabilidad del modelo, lo que permite descubrir la distribución predictiva, de la siguiente manera:
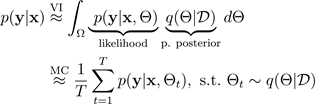
Para simplificar, se puede suponer que la probabilidad tiene una distribución gaussiana:

con la función gaussiana
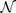 especificada mediante los
especificada mediante los
 parámetros de media y varianza
parámetros de media y varianza
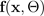 , que se obtienen mediante simulaciones del BNN de Monte Carlo dropout:
, que se obtienen mediante simulaciones del BNN de Monte Carlo dropout:
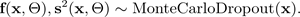
El siguiente gráfico muestra el MC dropout Cada configuración de exclusión produce una salida diferente al apagar y encender las neuronas de forma aleatoria (círculos grises) y encenderlas (círculos negros) con cada propagación hacia delante. Múltiples pasadas hacia adelante con diferentes configuraciones de abandono producen una distribución predictiva sobre la media p (f (x, ø)).

El número de pases anticipados a los datos debe evaluarse cuantitativamente, pero entre 30 y 100 es un rango adecuado a tener en cuenta (Gal y Ghahramani 2016).
