Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Preparación y limpieza de datos
La preparación y la limpieza de los datos son una de las etapas más importantes del ciclo de vida de los datos, pero que requieren más tiempo. El siguiente diagrama muestra cómo la etapa de preparación y limpieza de datos se adapta al ciclo de vida de la ingeniería de datos, la automatización y el control de acceso.
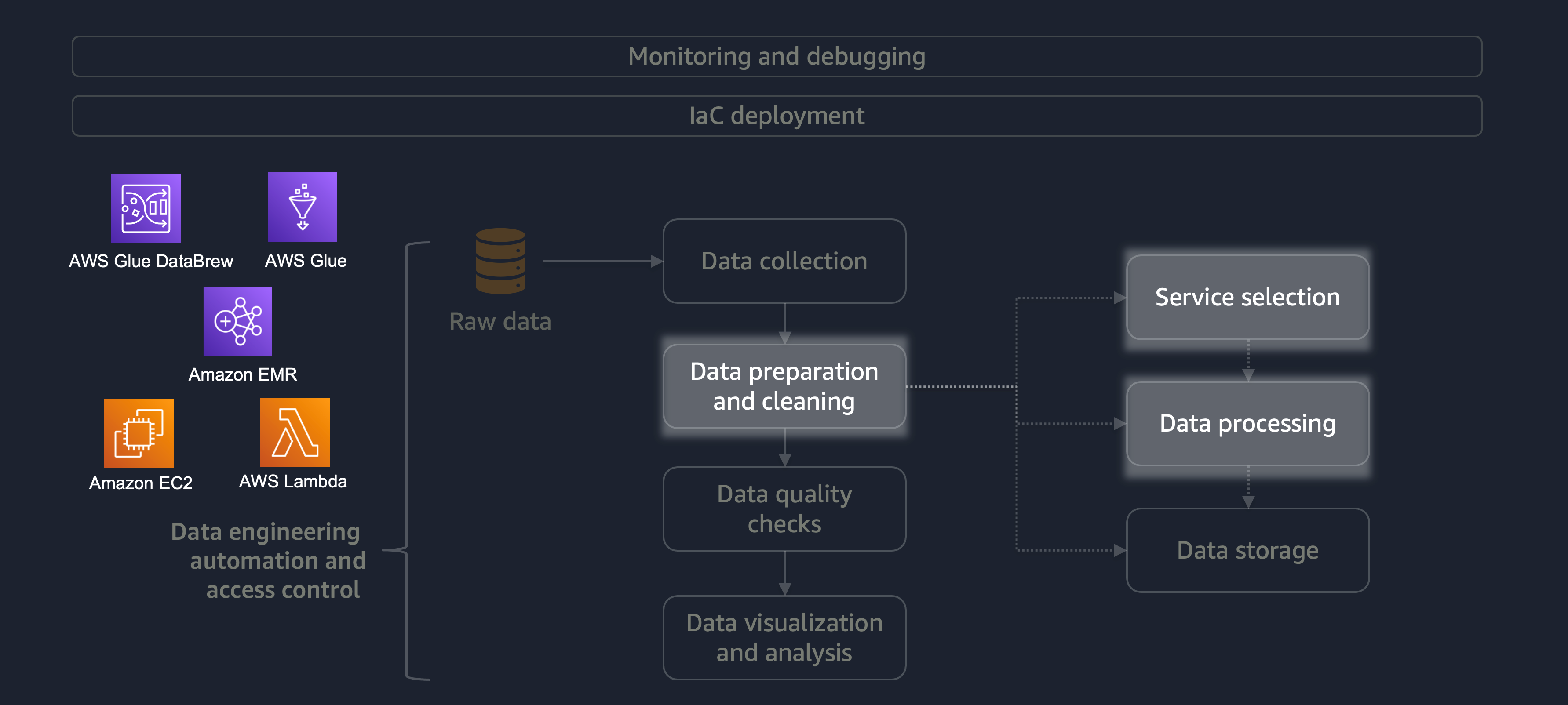
Estos son algunos ejemplos de preparación o limpieza de datos:
-
Asignación de columnas de texto a códigos
-
Ignorar las columnas vacías
-
Rellenar campos de datos vacíos con
0None, o'' -
Anonimizar o enmascarar la información de identificación personal (PII)
Si tiene una gran carga de trabajo que contiene una variedad de datos, le recomendamos que utilice Amazon EMRDataFrame o DynamicFrame trabajar con él. Además, puede usar AWS Glue DataBrew
Para cargas de trabajo más pequeñas que no requieren procesamiento distribuido y se pueden completar en menos de 15 minutos, le recomendamos que utilice AWS
Es esencial elegir el servicio de AWS adecuado para la preparación y limpieza de datos y comprender las desventajas que implica su elección. Por ejemplo, considere un escenario en el que elija entre AWS Glue y Amazon EMR. DataBrew AWS Glue es ideal si el trabajo de ETL es poco frecuente. Un trabajo poco frecuente se realiza una vez al día, una vez a la semana o una vez al mes. Además, puedes suponer que tus ingenieros de datos son expertos en escribir el código de Spark (para casos de uso de macrodatos) o en la creación de scripts en general. Si el trabajo es más frecuente, ejecutar AWS Glue constantemente puede resultar caro. En este caso, Amazon EMR proporciona capacidades de procesamiento distribuido y ofrece tanto una versión sin servidor como una basada en servidor. Si sus ingenieros de datos no tienen las habilidades adecuadas o si usted debe ofrecer resultados rápidamente, entonces DataBrew es una buena opción. DataBrew puede reducir el esfuerzo de desarrollar código y acelerar el proceso de preparación y limpieza de datos.
Una vez finalizado el procesamiento, los datos del proceso ETL se almacenan en AWS. La elección del almacenamiento depende del tipo de datos del que se trate. Por ejemplo, podría trabajar con datos no relacionales, como datos de gráficos, datos de pares clave-valor, imágenes, archivos de texto o datos estructurados relacionales.
Como se muestra en el siguiente diagrama, puede utilizar los siguientes servicios de AWS para el almacenamiento de datos:
-
Amazon S3
almacena datos no estructurados o semiestructurados (por ejemplo, archivos, imágenes y vídeos de Apache Parquet). -
Amazon Neptune
almacena conjuntos de datos de gráficos que puede consultar mediante SPARQL o GREMLIN. -
Amazon Keyspaces (para Apache Cassandra)
almacena conjuntos de datos compatibles con Apache Cassandra. -
Amazon Aurora
almacena conjuntos de datos relacionales. -
Amazon DynamoDB
almacena datos de documentos o valores clave en una base de datos NoSQL. -
Amazon Redshift
almacena las cargas de trabajo de datos estructurados en un almacén de datos.
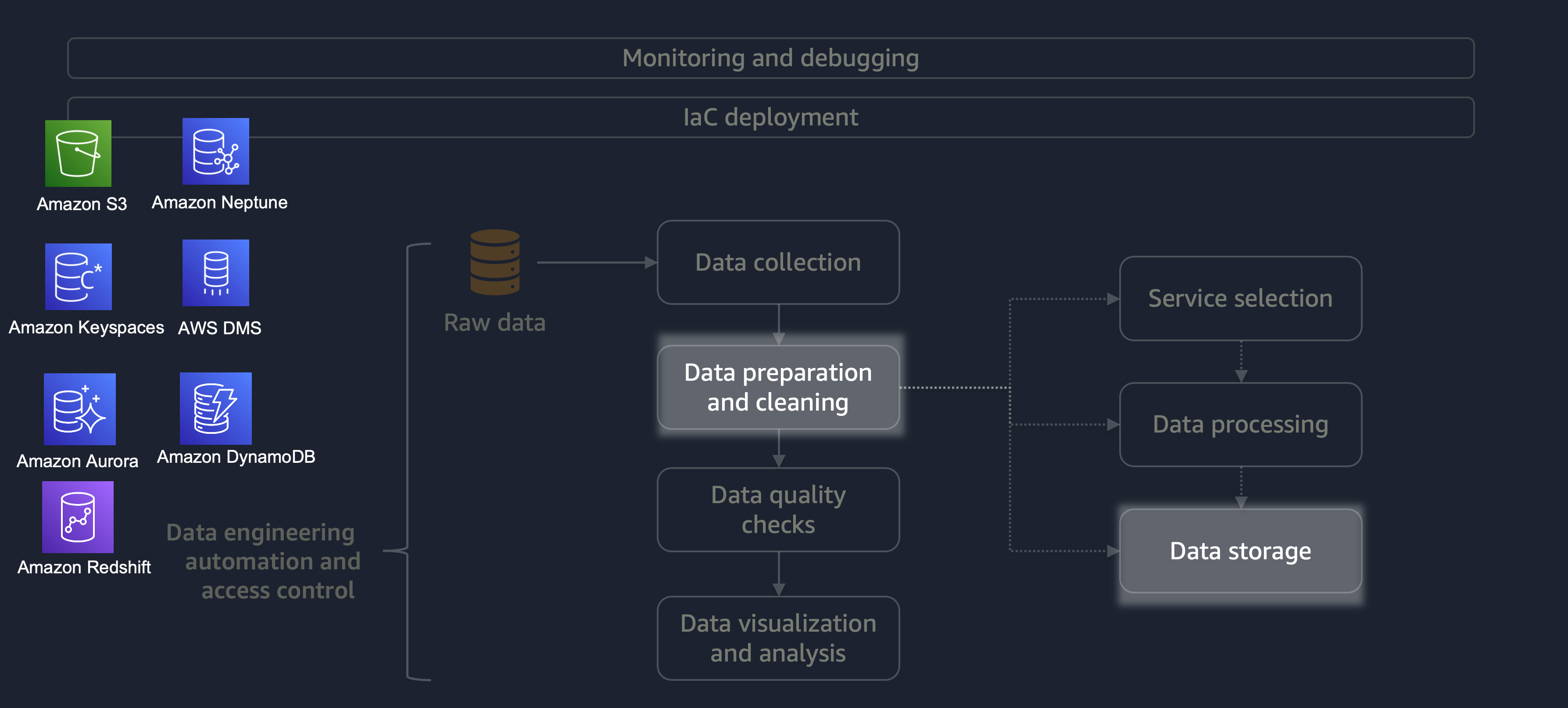
Al utilizar el servicio correcto con las configuraciones correctas, puede almacenar sus datos de la manera más eficiente y eficaz. Esto minimiza el esfuerzo que implica la recuperación de datos.
