Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Pilar de eficiencia de rendimiento
El pilar de eficiencia del rendimiento del AWS Well-Architected Framework se centra en cómo optimizar el rendimiento al ingerir o consultar datos. La optimización del rendimiento es un proceso gradual y continuo que consiste en lo siguiente:
-
Confirmación de los requisitos empresariales
-
Medición del rendimiento de la carga
-
Identificar los componentes de bajo rendimiento
-
Ajustando los componentes para que se adapten a las necesidades de su empresa
El pilar de la eficiencia del rendimiento proporciona pautas específicas para cada caso de uso que pueden ayudarlo a identificar el modelo de datos gráfico y los lenguajes de consulta correctos que debe utilizar. También incluye las mejores prácticas que se deben seguir a la hora de ingerir y consumir datos de Neptune Analytics.
El pilar de la eficiencia del rendimiento se centra en las siguientes áreas clave:
-
Modelado gráfico
-
Optimización de las consultas
-
Dimensionamiento correcto de gráficos
-
Optimización de escritura
Comprenda el modelado de gráficos para el análisis
En la guía Applying the AWS Well-Architected Framework for Amazon Neptune se analiza el modelado de gráficos para mejorar la eficiencia del rendimiento. Las decisiones de modelado que afectan al rendimiento incluyen la elección de los nodos y bordes necesarios, sus etiquetas y propiedades IDs, la dirección de los bordes, si las etiquetas deben ser genéricas o específicas y, en general, la eficacia con la que el motor de consultas puede navegar por el gráfico para procesar las consultas comunes.
Estas consideraciones también se aplican a Neptune Analytics; sin embargo, es importante distinguir entre los patrones de uso transaccionales y analíticos. Es posible que sea necesario cambiar la forma de un modelo gráfico que sea eficaz para las consultas en una base de datos transaccional, como una base de datos de Neptune, para fines de análisis.
Por ejemplo, consideremos un gráfico de fraude en una base de datos de Neptune cuyo propósito es comprobar si hay patrones fraudulentos en los pagos con tarjeta de crédito. Este gráfico puede tener nodos que representen las cuentas, los pagos y las características (como la dirección de correo electrónico, la dirección IP o el número de teléfono) tanto de la cuenta como del pago. Este gráfico conectado admite consultas como recorrer una ruta de longitud variable que comienza con un pago determinado y realiza varios saltos para encontrar funciones y cuentas relacionadas. En la siguiente figura se muestra un gráfico de este tipo.
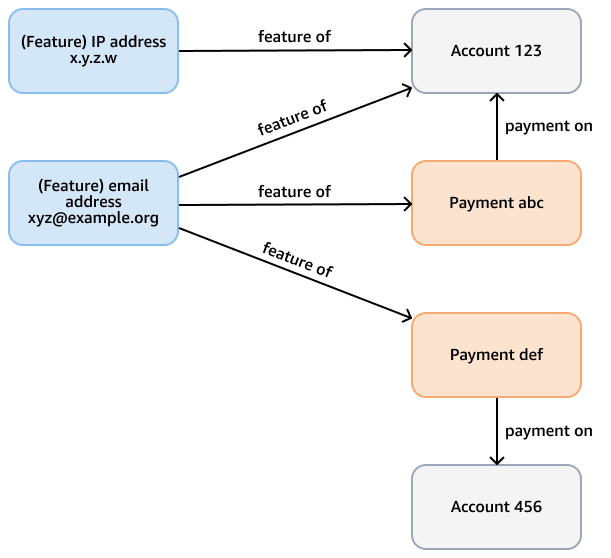
El requisito analítico puede ser más específico, como encontrar comunidades de cuentas que estén vinculadas mediante una función. Para ello, puede utilizar el algoritmo de componentes débilmente conectados (WCC). Ejecutarlo con el modelo del ejemplo anterior es ineficiente, ya que necesita atravesar varios tipos diferentes de nodos y bordes. El modelo del siguiente diagrama es más eficiente. Vincula account los nodos con una shares feature ventaja si las propias cuentas (o los pagos de las cuentas) comparten una función. Por ejemplo, Account 123 tiene la función xyz@example.org de correo electrónico y Account 456 usa ese mismo correo electrónico para un pago (). Payment def

La complejidad computacional del WCC es O(|E|logD) dónde |E| está el número de aristas del gráfico y D es el diámetro (la longitud de la ruta más larga) que conecta los nodos. Como el modelo transaccional omite los nodos y aristas no esenciales, optimiza tanto el número de aristas como el diámetro y reduce la complejidad del algoritmo del WCC.
Cuando utilice Neptune Analytics, trabaje a partir de los algoritmos y consultas analíticas necesarios. Si es necesario, modifique la forma del modelo para optimizar estas consultas. Puede cambiar la forma del modelo antes de cargar datos en el gráfico o escribir consultas que modifiquen los datos existentes en el gráfico.
Optimización de consultas
Siga estas recomendaciones para optimizar las consultas de Neptune Analytics:
-
Utilice consultas parametrizadas y la caché del plan de consultas, que está habilitada de forma predeterminada. Al utilizar la memoria caché del plan, el motor prepara la consulta para su uso posterior, siempre que la consulta se complete en 100 milisegundos o menos, lo que ahorra tiempo en las siguientes invocaciones.
-
En el caso de consultas lentas, ejecuta un plan explicativo para detectar los cuellos de botella y realizar las mejoras correspondientes.
-
Si utilizas la búsqueda de similitudes vectoriales, decide si las incrustaciones más pequeñas producen resultados de similitud precisos. Puede crear, almacenar y buscar incrustaciones más pequeñas de forma más eficiente.
-
Siga las prácticas recomendadas documentadas para usar OpenCypher en Neptune Analytics. Por ejemplo, utilice mapas aplanados en una cláusula UNWIND y especifique las etiquetas de los bordes siempre que sea posible.
-
Cuando utilice un algoritmo gráfico, comprenda las entradas y salidas del algoritmo, su complejidad computacional y, en términos generales, cómo funciona.
-
Antes de utilizar un algoritmo gráfico, utilice una
MATCHcláusula para minimizar el conjunto de nodos de entrada. Por ejemplo, para limitar los nodos desde los que realizar búsquedas prioritarias por amplitud (BFS), siga los ejemplos que se proporcionan en la documentación de Neptune Analytics. -
Si es posible, filtre las etiquetas de los nodos y los bordes. Por ejemplo, BFS tiene parámetros de entrada para filtrar el recorrido hasta una etiqueta de nodo específica (
vertexLabel) o etiquetas de borde específicas (edgeLabels). -
Utilice parámetros delimitadores, por ejemplo,
maxDepthpara limitar los resultados. -
Experimente con el
concurrencyparámetro. Pruébelo con un valor de 0, que utiliza todos los subprocesos del algoritmo disponibles para paralelizar el procesamiento. Compárelo con la ejecución de un solo subproceso configurando el parámetro en 1. Un algoritmo puede completarse más rápido en un solo subproceso, especialmente en entradas más pequeñas, como las búsquedas con poco espacio, en las que el paralelismo no ofrece una reducción apreciable del tiempo de ejecución y puede generar una sobrecarga. -
Elige entre tipos de algoritmos similares. Por ejemplo, Bellman-Ford y delta-Stepping son algoritmos de ruta más corta de una sola fuente. Cuando realices pruebas con tu propio conjunto de datos, prueba ambos algoritmos y compara los resultados. El delta suele ser más rápido que el de Bellman-Ford debido a su menor complejidad computacional. Sin embargo, el rendimiento depende del conjunto de datos y de los parámetros de entrada, en particular del parámetro.
delta
-
Optimice las escrituras
Siga estas prácticas para optimizar las operaciones de escritura en Neptune Analytics:
-
Busque la forma más eficiente de cargar datos en un gráfico. Cuando cargue datos en Amazon S3, utilice la importación masiva si los datos tienen un tamaño superior a 50 GB. Para datos más pequeños, utilice la carga por lotes. Si se out-of-memory producen errores al ejecutar la carga por lotes, considere la posibilidad de aumentar el valor de m-NCU o dividir la carga en varias solicitudes. Una forma de lograrlo consiste en dividir los archivos en varios prefijos en el bucket de S3. En ese caso, llame a batch load por separado para cada prefijo.
-
Utilice la importación masiva o el cargador por lotes para rellenar el conjunto inicial de datos del gráfico. Utilice las operaciones transaccionales de creación, actualización y eliminación de OpenCypher únicamente para cambios pequeños.
-
Utilice la importación masiva o el cargador por lotes con una simultaneidad de 1 (subproceso único) para incorporar las incrustaciones en el gráfico. Intente cargar las incrustaciones por adelantado mediante uno de estos métodos.
-
Evalúe la dimensión de las incrustaciones vectoriales necesarias para una búsqueda de similitud precisa en los algoritmos de búsqueda de similitudes vectoriales. Utilice una dimensión más pequeña si es posible. Esto se traduce en una velocidad de carga más rápida para las incrustaciones.
-
Utilice algoritmos de mutación para recordar los resultados algorítmicos si es necesario. Por ejemplo, el algoritmo de centralidad con grado de mutación busca el grado de cada nodo de entrada y escribe ese valor como una propiedad del nodo. Si las conexiones que rodean esos nodos no cambian posteriormente, la propiedad contiene el resultado correcto. No es necesario volver a ejecutar el algoritmo.
-
Utilice la acción administrativa de restablecimiento gráfico para borrar todos los nodos, bordes e incrustaciones si necesita empezar de nuevo. Si el gráfico es grande, no es posible eliminar todos los nodos, bordes e incrustaciones mediante una consulta de OpenCypher. Se puede agotar el tiempo de espera de una sola consulta en un conjunto de datos grande. A medida que aumenta el tamaño, el conjunto de datos tarda más en eliminarse y el tamaño de la transacción aumenta. Por el contrario, el tiempo necesario para completar el restablecimiento de un gráfico es prácticamente constante y la acción ofrece la opción de crear una instantánea antes de ejecutarla.
Gráficos del tamaño correcto
El rendimiento general depende de la capacidad aprovisionada de un gráfico de Neptune Analytics. La capacidad se mide en unidades denominadas unidades de capacidad de Neptune optimizadas para la memoria (m -). NCUs Asegúrese de que el gráfico tenga el tamaño suficiente para admitir el tamaño del gráfico y las consultas. Ten en cuenta que el aumento de la capacidad no mejora necesariamente el rendimiento de una consulta individual.
Si es posible, cree el gráfico importando datos de una fuente existente, como Amazon S3 o un clúster o una instantánea de Neptune existente. Puede establecer límites en la capacidad mínima y máxima. También puede cambiar la capacidad aprovisionada en un gráfico existente.
Supervise CloudWatch métricas comoNumQueuedRequestsPerSec, NumOpenCypherRequestsPerSec GraphStorageUsagePercentGraphSizeBytes, y CPUUtilization evalúe si el gráfico tiene el tamaño correcto. Determine si se necesita más capacidad para soportar el tamaño y la carga del gráfico. Para obtener más información sobre cómo interpretar algunas de estas métricas, consulte la sección sobre el pilar de la excelencia operativa.
