Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Lanzar un trabajo de Spark en un clúster EMR transitorio mediante una función de Lambda
Creado por Dhrubajyoti Mukherjee (AWS)
Resumen
Este patrón utiliza la acción de la RunJobFlow API Amazon EMR para lanzar un clúster transitorio para ejecutar un trabajo de Spark desde una función de Lambda. Un clúster EMR transitorio está diseñado para finalizar tan pronto como se complete el trabajo o si se produce algún error. Un clúster transitorio permite ahorrar costos porque solo se ejecuta durante el tiempo de cálculo y proporciona escalabilidad y flexibilidad en un entorno de nube.
El clúster EMR transitorio se lanza mediante la API Boto3 y el lenguaje de programación Python en una función de Lambda. La función de Lambda, escrita en Python, proporciona la flexibilidad adicional de iniciar el clúster cuando es necesario.
Para demostrar un ejemplo de cálculo y salida por lotes, este patrón lanzará un trabajo de Spark en un clúster de EMR desde una función de Lambda y ejecutará un cálculo por lotes con los datos de ventas de ejemplo de una empresa ficticia. El resultado del trabajo de Spark será un archivo de valores separados por comas (CSV) en Amazon Simple Storage Service (Amazon S3). El archivo de datos de entrada, el archivo.jar de Spark, un fragmento de código y una CloudFormation plantilla de AWS para una nube privada virtual (VPC) y las funciones de AWS Identity and Access Management (IAM) para ejecutar el cálculo se proporcionan como datos adjuntos.
Requisitos previos y limitaciones
Requisitos previos
Una cuenta de AWS activa
Limitaciones
Solo se puede iniciar un trabajo de Spark a partir del código a la vez.
Versiones de producto
Probado en Amazon EMR 6.0.0
Arquitectura
Pila de tecnología de destino
Amazon EMR
AWS Lambda
Amazon S3
Apache Spark
Arquitectura de destino
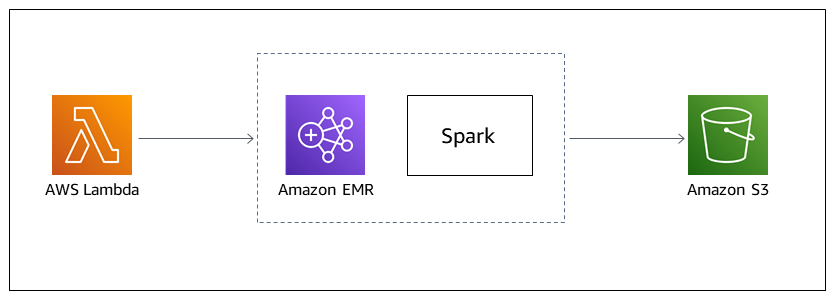
Automatizar y escalar
Para automatizar el cálculo por lotes de Spark-EMR, puede utilizar cualquiera de las siguientes opciones.
Implemente una EventBridge regla de Amazon que pueda iniciar la función Lambda en una programación cron. Para obtener más información, consulte el tutorial: Programe funciones de AWS Lambda mediante. EventBridge
Configure las notificaciones de eventos de Amazon S3 para iniciar la función de Lambda al llegar el archivo.
Transfiera los parámetros de entrada a la función de AWS Lambda a través del cuerpo del evento y de las variables de entorno de Lambda.
Herramientas
Servicios de AWS
Amazon EMR es una plataforma de clúster administrada que simplifica la ejecución de marcos de macrodatos en AWS para procesar y analizar grandes cantidades de datos.
AWS Lambda es un servicio de computación que ayuda a ejecutar código sin necesidad de aprovisionar ni administrar servidores. Ejecuta el código solo cuando es necesario y amplía la capacidad de manera automática, por lo que solo pagará por el tiempo de procesamiento que utilice.
Amazon Simple Storage Service (Amazon S3) es un servicio de almacenamiento de objetos basado en la nube que le ayuda a almacenar, proteger y recuperar cualquier cantidad de datos.
Otras herramientas
Apache Spark
es un motor de análisis en varios idiomas para el procesamiento de datos a gran escala.
Epics
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Crear las funciones de IAM y la VPC. | Si ya tiene las funciones de IAM de AWS Lambda y Amazon EMR y una VPC, puede omitir este paso. Para ejecutar el código, tanto el clúster de EMR como la función de Lambda requieren funciones de IAM. El clúster de EMR también requiere una VPC con una subred pública o una subred privada con una gateway NAT. Para crear automáticamente todas las funciones de IAM y una VPC, implemente la plantilla de CloudFormation AWS adjunta tal cual, o bien, puede crear las funciones y la VPC manualmente, tal como se especifica en la sección Información adicional. | Arquitecto de la nube |
Anote las claves de salida CloudFormation de la plantilla de AWS. | Una vez que la CloudFormation plantilla se haya implementado correctamente, vaya a la pestaña Outputs de la CloudFormation consola de AWS. Tenga en cuenta las cinco claves de salida:
Utilizará los valores de estas claves cuando cree la función de Lambda. | Arquitecto de la nube |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Subir el archivo.jar de Spark. | Cargue el archivo.jar de Spark en el depósito de S3 que creó la CloudFormation pila de AWS. El nombre del bucket es el mismo que el de la clave de salida | AWS general |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Creación de una función de Lambda. | En la consola Lambda, cree una función de Lambda de Python 3.9+ con un rol de ejecución. La política de funciones de ejecución debe permitir a Lambda lanzar un clúster de EMR. (Consulte la CloudFormation plantilla de AWS adjunta). | Ingeniero de datos, ingeniero de nube |
Copie y pegue el código. | Sustituya el código del archivo | Ingeniero de datos, ingeniero de nube |
Cambie los parámetros del código. | Siga los comentarios del código para cambiar los valores de los parámetros para que se ajusten a su cuenta de AWS. | Ingeniero de datos, ingeniero de nube |
Inicie la función para iniciar el clúster. | Inicie la función para iniciar la creación de un clúster EMR transitorio con el archivo .jar de Spark proporcionado. Ejecutará el trabajo de Spark y finalizará automáticamente cuando se complete el trabajo. | Ingeniero de datos, ingeniero de nube |
Compruebe el estado del clúster de EMR. | Una vez iniciado el clúster de EMR, aparece en la consola de Amazon EMR, en la pestaña Clústeres. Se puede comprobar en consecuencia cualquier error que se produzca al lanzar el clúster o al ejecutar el trabajo. | Ingeniero de datos, ingeniero de nube |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Subir el archivo.jar de Spark. | Descargar el archivo.jar de Spark de la sección de Adjuntos y cárgalo en el bucket de S3. | Ingeniero de datos, ingeniero de nube |
Cargue el conjunto de datos de entrada. | Cargue el archivo | Ingeniero de datos, ingeniero de nube |
Pegue el código de Lambda y cambie los parámetros. | Copie el código de la sección Herramientas y péguelo en una función de Lambda, sustituyendo el archivo de código | Ingeniero de datos, ingeniero de nube |
Iniciar la función y verificar la salida. | Una vez que la función de Lambda inicia el clúster con el trabajo de Spark proporcionado, genera un archivo.csv en el bucket de S3. | Ingeniero de datos, ingeniero de nube |
Recursos relacionados
Información adicional
Código
""" Copy paste the following code in your Lambda function. Make sure to change the following key parameters for the API as per your account -Name (Name of Spark cluster) -LogUri (S3 bucket to store EMR logs) -Ec2SubnetId (The subnet to launch the cluster into) -JobFlowRole (Service role for EC2) -ServiceRole (Service role for Amazon EMR) The following parameters are additional parameters for the Spark job itself. Change the bucket name and prefix for the Spark job (located at the bottom). -s3://your-bucket-name/prefix/lambda-emr/SparkProfitCalc.jar (Spark jar file) -s3://your-bucket-name/prefix/fake_sales_data.csv (Input data file in S3) -s3://your-bucket-name/prefix/outputs/report_1/ (Output location in S3) """ import boto3 client = boto3.client('emr') def lambda_handler(event, context): response = client.run_job_flow( Name='spark_job_cluster', LogUri='s3://your-bucket-name/prefix/logs', ReleaseLabel='emr-6.0.0', Instances={ 'MasterInstanceType': 'm5.xlarge', 'SlaveInstanceType': 'm5.large', 'InstanceCount': 1, 'KeepJobFlowAliveWhenNoSteps': False, 'TerminationProtected': False, 'Ec2SubnetId': 'subnet-XXXXXXXXXXXXXX' }, Applications=[{'Name': 'Spark'}], Configurations=[ {'Classification': 'spark-hive-site', 'Properties': { 'hive.metastore.client.factory.class': 'com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory'} } ], VisibleToAllUsers=True, JobFlowRole='EMRLambda-EMREC2InstanceProfile-XXXXXXXXX', ServiceRole='EMRLambda-EMRRole-XXXXXXXXX', Steps=[ { 'Name': 'flow-log-analysis', 'ActionOnFailure': 'TERMINATE_CLUSTER', 'HadoopJarStep': { 'Jar': 'command-runner.jar', 'Args': [ 'spark-submit', '--deploy-mode', 'cluster', '--executor-memory', '6G', '--num-executors', '1', '--executor-cores', '2', '--class', 'com.aws.emr.ProfitCalc', 's3://your-bucket-name/prefix/lambda-emr/SparkProfitCalc.jar', 's3://your-bucket-name/prefix/fake_sales_data.csv', 's3://your-bucket-name/prefix/outputs/report_1/' ] } } ] )
Funciones de IAM y creación de VPC
Para lanzar el clúster de EMR en una función de Lambda, se necesitan funciones de VPC e IAM. Puede configurar las funciones de VPC e IAM mediante la CloudFormation plantilla de AWS de la sección de adjuntos de este patrón, o puede crearlas manualmente mediante los siguientes enlaces.
Las siguientes funciones de IAM son necesarias para ejecutar Lambda y Amazon EMR.
Rol de ejecución de Lambda
El rol de ejecución de una función de AWS Lambda concede permiso a la función para que tenga acceso a los servicios y recursos de AWS.
Roles de servicio para Amazon EMR
La función Amazon EMR define las acciones permitidas para Amazon EMR al aprovisionar recursos y realizar tareas de nivel de servicio que no se realizan en el contexto de una instancia de Amazon Elastic Compute Cloud (Amazon) que se ejecuta dentro de un clúster. EC2 Por ejemplo, la función de servicio se utiliza para aprovisionar EC2 instancias cuando se lanza un clúster.
Función de servicio para EC2 instancias
La función de servicio para EC2 las instancias de clúster (también denominada perfil de EC2 instancia para Amazon EMR) es un tipo especial de función de servicio que se asigna a todas las instancias de un clúster de Amazon EMR cuando se lanza la EC2 instancia. Los procesos de aplicación que se ejecutan sobre el ecosistema de Apache asumen este rol para los permisos, e interactuar así con otros servicios de AWS.
Creación de VPC y subredes
Puede crear una VPC desde la consola de VPC.
Conexiones
Para acceder al contenido adicional asociado a este documento, descomprima el archivo: attachment.zip
