Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Caso de uso: creación de una aplicación de inteligencia médica con datos aumentados de pacientes
La IA generativa puede ayudar a aumentar la atención a los pacientes y la productividad del personal al mejorar las funciones clínicas y administrativas. El análisis de imágenes impulsado por la IA, como la interpretación de ecografías, acelera los procesos de diagnóstico y mejora la precisión. Puede proporcionar información fundamental que respalde las intervenciones médicas oportunas.
Al combinar modelos de IA generativos con gráficos de conocimiento, puede automatizar la organización cronológica de los registros electrónicos de los pacientes. Esto le ayuda a integrar datos en tiempo real de las interacciones entre el médico y el paciente, los síntomas, los diagnósticos, los resultados de laboratorio y el análisis de imágenes. Esto proporciona al médico datos completos del paciente. Estos datos ayudan al médico a tomar decisiones médicas más precisas y oportunas, lo que mejora tanto los resultados de los pacientes como la productividad de los proveedores de atención médica.
Información general de la solución
La IA puede ayudar a los médicos y médicos al sintetizar los datos de los pacientes y el conocimiento médico para proporcionar información valiosa. Esta solución de generación aumentada de recuperación (RAG) es un motor de inteligencia médica que consume un conjunto integral de datos y conocimientos de los pacientes procedentes de millones de interacciones clínicas. Aprovecha el poder de la IA generativa para crear información basada en la evidencia para mejorar la atención a los pacientes. Está diseñado para mejorar los flujos de trabajo clínicos, reducir los errores y mejorar los resultados de los pacientes.
La solución incluye una capacidad de procesamiento de imágenes automatizada que funciona con. LLMs Esta capacidad reduce la cantidad de tiempo que el personal médico debe dedicar manualmente a buscar imágenes de diagnóstico similares y a analizar los resultados del diagnóstico.
En la siguiente imagen se muestra end-to-end-workflow la solución correspondiente. Utiliza Amazon Neptune, Amazon SageMaker AI, Amazon OpenSearch Service y un modelo básico en Amazon Bedrock. Para el agente de recuperación de contexto que interactúa con el gráfico de conocimientos médicos de Neptune, puede elegir entre un agente de Amazon Bedrock y un LangChain agente.
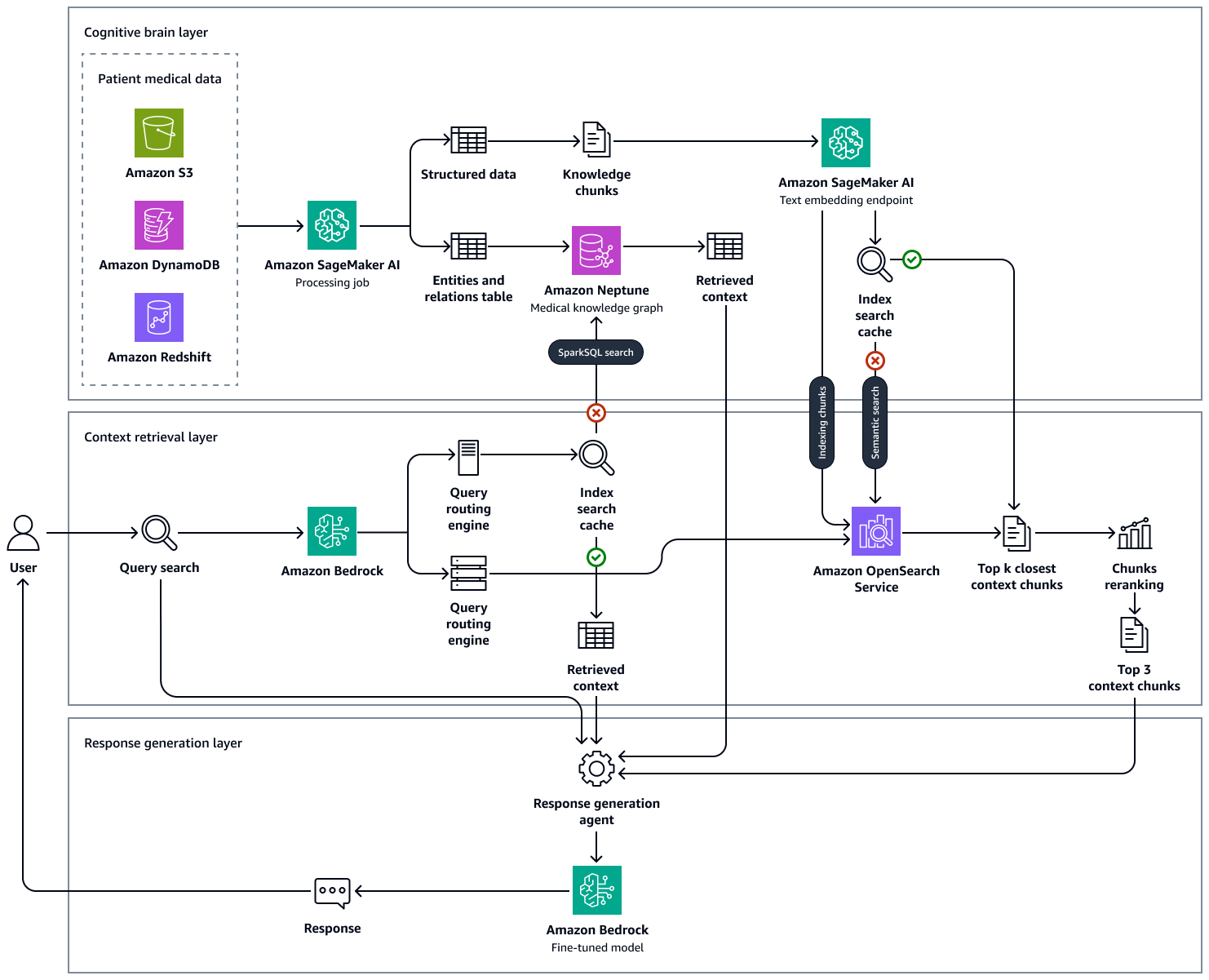
En nuestros experimentos con ejemplos de preguntas médicas, observamos que las respuestas finales generadas por nuestro enfoque, que utilizó un gráfico de conocimiento mantenido en Neptune, una base de datos OpenSearch vectorial que alberga la base de conocimientos clínicos y Amazon Bedrock, LLMs se basaban en la realidad y son mucho más precisas, ya que reducen los falsos positivos y aumentan los verdaderos positivos. Esta solución puede generar información basada en evidencias sobre el estado de salud del paciente y tiene como objetivo mejorar los flujos de trabajo clínicos, reducir los errores y mejorar los resultados de los pacientes.
La creación de esta solución consta de los siguientes pasos:
Paso 1: Descubrimiento de datos
Existen muchos conjuntos de datos médicos de código abierto que puede utilizar para respaldar el desarrollo de una solución sanitaria basada en la IA. Uno de estos conjuntos de datos es el conjunto de datos MIMIC-IV, que es un conjunto
También puede utilizar un conjunto de datos que proporcione resúmenes de alta de pacientes anotados y anónimos, seleccionados específicamente para fines de investigación. Un conjunto de datos resumidos sobre el alta médica puede ayudarte a experimentar con la extracción de entidades, ya que te permite identificar entidades médicas clave (como afecciones, procedimientos y medicamentos) a partir del texto. Paso 2: Crear un gráfico de conocimientos médicosen esta guía, se describe cómo puede utilizar los datos estructurados extraídos del conjunto de datos MIMIC-IV y del conjunto de datos resumidos del alta médica para crear un gráfico de conocimientos médicos. Este gráfico de conocimientos médicos es la columna vertebral de los sistemas avanzados de consulta y apoyo a la toma de decisiones para los profesionales de la salud.
Además de los conjuntos de datos basados en texto, puede utilizar conjuntos de datos de imágenes. Por ejemplo, el conjunto de datos de radiografías musculoesqueléticas (MURA)
Paso 2: Crear un gráfico de conocimientos médicos
Para cualquier organización de salud que desee crear un sistema de apoyo a la toma de decisiones basado en una base de conocimientos masiva, un desafío clave es localizar y extraer las entidades médicas que están presentes en las notas clínicas, las revistas médicas, los resúmenes de alta y otras fuentes de datos. También es necesario recopilar las relaciones temporales, los temas y las evaluaciones de certeza de estos registros médicos para poder utilizar de forma eficaz las entidades, los atributos y las relaciones extraídas.
El primer paso consiste en extraer los conceptos médicos del texto médico no estructurado utilizando un mensaje de pocas tomas para un modelo básico, como Llama 3 en Amazon Bedrock. Las solicitudes de pocas tomas se dan cuando se le proporciona a un LLM un número reducido de ejemplos que muestran la tarea y el resultado deseado antes de pedirle que realice una tarea similar. Con un extractor de entidades médicas basado en el LLM, puede analizar el texto médico no estructurado y, a continuación, generar una representación de datos estructurados de las entidades del conocimiento médico. También puede almacenar los atributos del paciente para su posterior análisis y automatización. El proceso de extracción de entidades incluye las siguientes acciones:
-
Extraiga información sobre conceptos médicos, como enfermedades, medicamentos, dispositivos médicos, dosis, frecuencia y duración de los medicamentos, síntomas, procedimientos médicos y sus atributos clínicamente relevantes.
-
Capture las características funcionales, como las relaciones temporales entre las entidades extraídas, los sujetos y las evaluaciones de certeza.
-
Amplíe los vocabularios médicos estándar, como los siguientes:
-
Identificadores conceptuales (RxCUI) de la base de datos RxNorm
-
Códigos de la Clasificación Internacional de Enfermedades, décima revisión, modificación clínica
(ICD-10-CM) -
Términos de los encabezados de materias médicas
(MeSH) -
Conceptos de la nomenclatura sistematizada de la medicina, términos clínicos
(SNOMED CT) -
Códigos del Sistema Unificado de Lenguaje Médico
(UMLS)
-
-
Resuma las notas de alta y obtenga información médica a partir de las transcripciones.
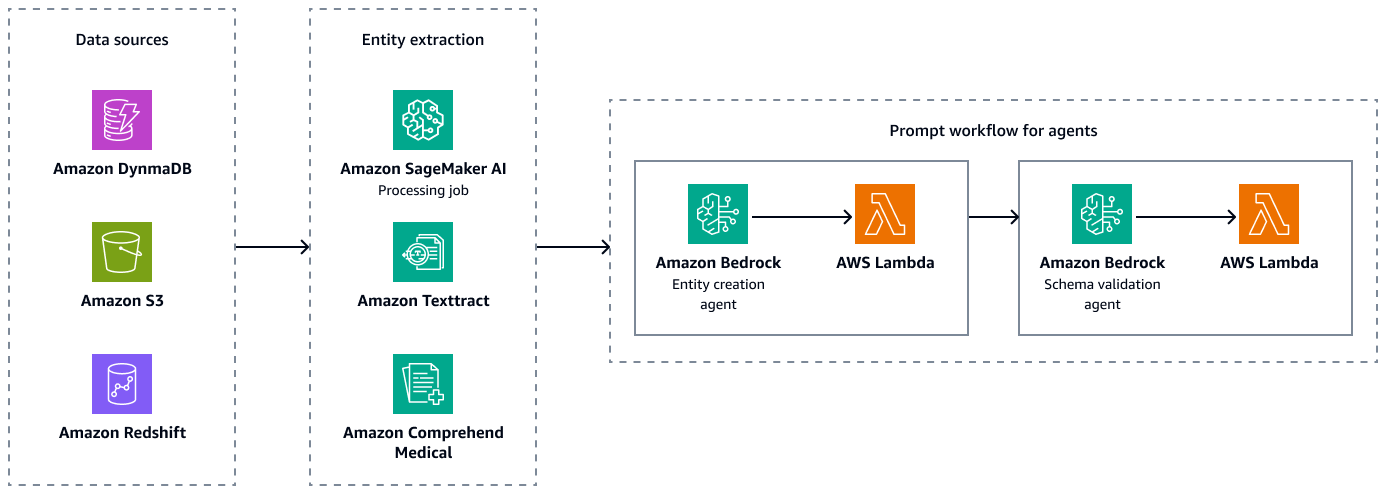
La siguiente figura muestra los pasos de extracción de entidades y validación del esquema para crear combinaciones pareadas válidas de entidades, atributos y relaciones. Puede almacenar datos no estructurados, como resúmenes de alta o notas de pacientes, en Amazon Simple Storage Service (Amazon S3). Puede almacenar datos estructurados, como datos de planificación de recursos empresariales (ERP), historiales electrónicos de pacientes y sistemas de información de laboratorio, en Amazon Redshift y Amazon DynamoDB. Puede crear un agente de creación de entidades en Amazon Bedrock. Este agente puede integrar servicios, como los canales de extracción de datos de Amazon SageMaker AI, Amazon Textract y Amazon Comprehend Medical, para extraer entidades, relaciones y atributos de las fuentes de datos estructuradas y no estructuradas. Por último, utiliza un agente de validación de esquemas de Amazon Bedrock para asegurarse de que las entidades y relaciones extraídas se ajustan al esquema gráfico predefinido y mantienen la integridad de las conexiones entre los extremos del nodo y las propiedades asociadas.
Tras extraer y validar las entidades, las relaciones y los atributos, puede vincularlos para crear un subject-object-predicate triplete. Estos datos se ingieren en una base de datos de gráficos de Amazon Neptune, como se muestra en la siguiente figura. Las bases de datos de gráficos están optimizadas para almacenar y consultar las relaciones entre los elementos de datos.
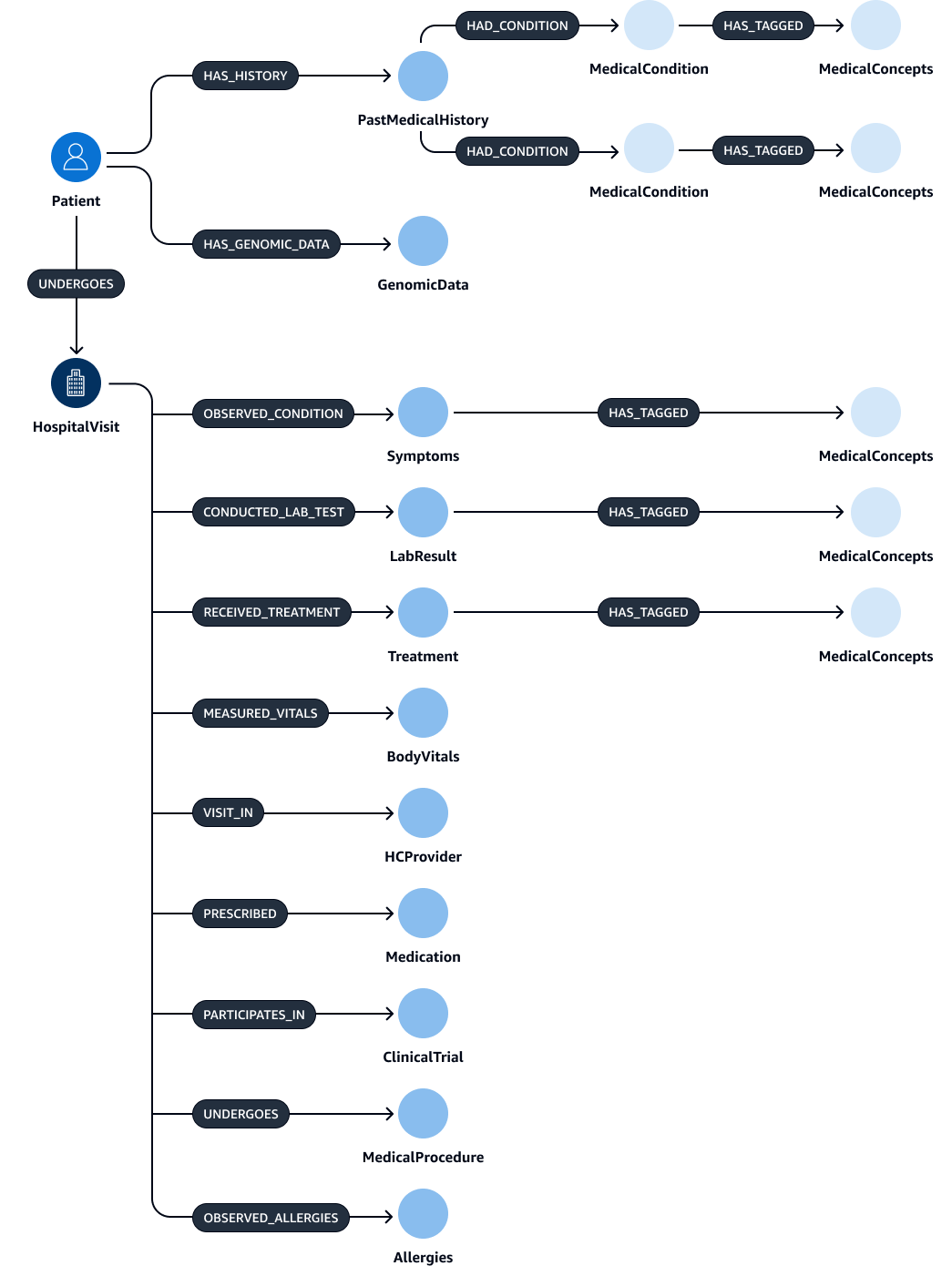
Puede crear un gráfico de conocimiento completo con estos datos. Un gráfico de conocimientoHospitalVisit PastMedicalHistorySymptoms,Medication,MedicalProcedures, yTreatment.
En las tablas siguientes se enumeran las entidades y sus atributos que se pueden extraer de las notas de aprobación.
| Entidad | Atributos |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
En la siguiente tabla se enumeran las relaciones que pueden tener las entidades y sus atributos correspondientes. Por ejemplo, la Patient entidad podría conectarse a la HospitalVisit entidad con la [UNDERGOES] relación. El atributo de esta relación esVisitDate.
| Entidad objeto | Relación | Entidad objeto | Atributos |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ninguno |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ninguna |
|
|
|
Ninguna |
|
|
|
Ninguna |
|
|
|
Ninguno |
Paso 3: Crear agentes de recuperación de contexto para consultar el gráfico del conocimiento médico
Tras crear la base de datos de gráficos médicos, el siguiente paso es crear agentes para la interacción con los gráficos. Los agentes recuperan el contexto correcto y necesario para la consulta que introduce un médico o un clínico. Existen varias opciones para configurar estos agentes que recuperan el contexto del gráfico de conocimiento:
Agentes de Amazon Bedrock para la interacción con gráficos
Los agentes de Amazon Bedrock trabajan a la perfección con las bases de datos de gráficos de Amazon Neptune. Puede realizar interacciones avanzadas a través de los grupos de acción de Amazon Bedrock. El grupo de acciones inicia el proceso llamando a una AWS Lambda función que ejecuta consultas OpenCypher de Neptune.
Para consultar un gráfico de conocimiento, puede utilizar dos enfoques distintos: la ejecución directa de consultas o la consulta con incrustación de contexto. Estos enfoques se pueden aplicar de forma independiente o combinados, según el caso de uso específico y los criterios de clasificación. Al combinar ambos enfoques, puede proporcionar un contexto más completo al LLM, lo que puede mejorar los resultados. Los dos enfoques de ejecución de consultas son los siguientes:
-
Ejecución directa de consultas de Cypher sin incrustaciones: la función Lambda ejecuta consultas directamente en Neptune sin ninguna búsqueda basada en incrustaciones. A continuación se muestra un ejemplo de este enfoque:
MATCH (p:Patient)-[u:UNDERGOES]->(h:HospitalVisit) WHERE h.Reason = 'Acute Diabetes' AND date(u.VisitDate) > date('2024-01-01') RETURN p.PatientID, p.Name, p.Age, p.Gender, p.Address, p.ContactInformation -
Ejecución directa de consultas de Cypher mediante búsqueda incrustada: la función Lambda utiliza la búsqueda incrustada para mejorar los resultados de la consulta. Este enfoque mejora la ejecución de las consultas al incorporar incrustaciones, que son representaciones vectoriales densas de datos. Las incrustaciones son particularmente útiles cuando la consulta requiere una similitud semántica o una comprensión más amplia que vaya más allá de las coincidencias exactas. Puede utilizar modelos previamente entrenados o personalizados para generar integraciones para cada afección médica. El siguiente es un ejemplo de este enfoque:
CALL { WITH "Acute Diabetes" AS query_term RETURN search_embedding(query_term) AS similar_reasons } MATCH (p:Patient)-[u:UNDERGOES]->(h:HospitalVisit) WHERE h.Reason IN similar reasons AND date(u.VisitDate) > date('2024-01-01') RETURN p.PatientID, p.Name, p.Age, p.Gender, p.Address, p.ContactInformationEn este ejemplo, la
search_embedding("Acute Diabetes")función recupera afecciones semánticamente cercanas a la «diabetes aguda». Esto ayuda a la consulta a encontrar también pacientes con afecciones como la prediabetes o el síndrome metabólico.
La siguiente imagen muestra cómo los agentes de Amazon Bedrock interactúan con Amazon Neptune para realizar una consulta cifrada de un gráfico de conocimientos médicos.
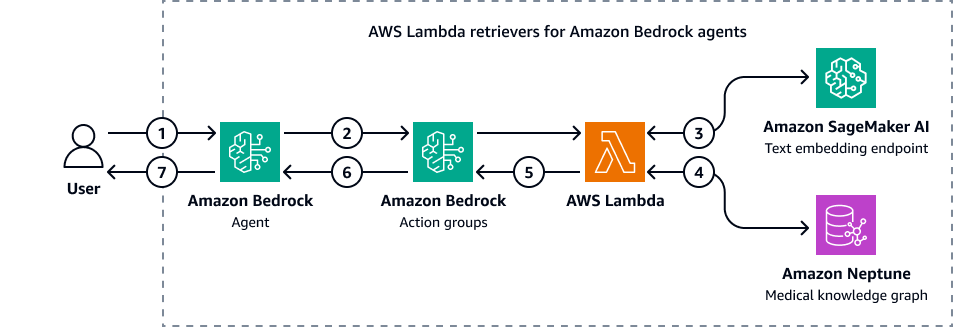
En el diagrama, se muestra el siguiente flujo de trabajo:
-
El usuario envía una pregunta al agente de Amazon Bedrock.
-
El agente de Amazon Bedrock pasa la pregunta y las variables del filtro de entrada a los grupos de acción de Amazon Bedrock. Estos grupos de acción contienen una AWS Lambda función que interactúa con el punto final de incrustación de texto de Amazon SageMaker AI y el gráfico de conocimientos médicos de Amazon Neptune.
-
La función Lambda se integra con el punto final de incrustación de texto de SageMaker IA para realizar una búsqueda semántica en la consulta de OpenCypher. Convierte la consulta en lenguaje natural en una consulta de OpenCypher mediante el uso de la función subyacente LangChain agentes.
-
La función Lambda consulta el conjunto de datos correcto en el gráfico de conocimiento médico de Neptuno y recibe el resultado del gráfico de conocimiento médico de Neptuno.
-
La función Lambda devuelve los resultados de Neptune a los grupos de acción de Amazon Bedrock.
-
Los grupos de acción de Amazon Bedrock envían el contexto recuperado al agente de Amazon Bedrock.
-
El agente de Amazon Bedrock genera la respuesta mediante la consulta original del usuario y el contexto recuperado del gráfico de conocimiento.
LangChain agentes para la interacción de gráficos
Puedes integrar LangChain con Neptune para permitir consultas y recuperaciones basadas en gráficos. Este enfoque puede mejorar los flujos de trabajo impulsados por la IA mediante el uso de las capacidades de la base de datos de gráficos de Neptune. La personalizada LangChain El retriever actúa como intermediario. El modelo fundamental de Amazon Bedrock puede interactuar con Neptune mediante consultas Cypher directas y algoritmos de gráficos más complejos.
Puede utilizar el recuperador personalizado para refinar la forma en que LangChain el agente interactúa con los algoritmos gráficos de Neptune. Por ejemplo, puede utilizar indicaciones de pocas tomas, lo que le ayuda a adaptar las respuestas del modelo base en función de patrones o ejemplos específicos. También puede aplicar filtros identificados por el LLM para afinar el contexto y mejorar la precisión de las respuestas. Esto puede mejorar la eficiencia y la precisión del proceso general de recuperación al interactuar con datos gráficos complejos.
La siguiente imagen muestra cómo se personaliza LangChain El agente organiza la interacción entre un modelo básico de Amazon Bedrock y un gráfico de conocimiento médico de Amazon Neptune.
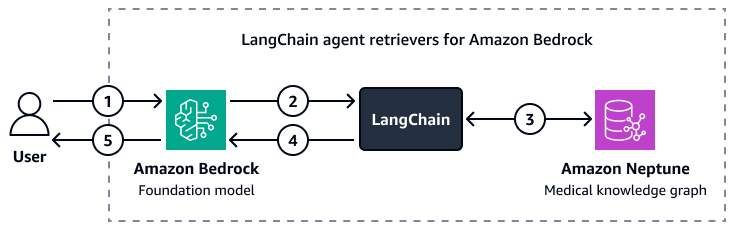
En el diagrama, se muestra el siguiente flujo de trabajo:
-
Un usuario envía una pregunta a Amazon Bedrock y al LangChain agente.
-
El modelo de base de Amazon Bedrock utiliza el esquema de Neptune, que proporciona el LangChain agente, para generar una consulta para la pregunta del usuario.
-
La LangChain El agente compara la consulta con el gráfico de conocimiento médico de Amazon Neptune.
-
La LangChain el agente envía el contexto recuperado al modelo de base de Amazon Bedrock.
-
El modelo básico de Amazon Bedrock utiliza el contexto recuperado para generar una respuesta a la pregunta del usuario.
Paso 4: Crear una base de conocimientos de datos descriptivos en tiempo real
A continuación, debe crear una base de conocimientos con notas descriptivas de la interacción médico-paciente en tiempo real, evaluaciones de imágenes de diagnóstico e informes de análisis de laboratorio. Esta base de conocimientos es una base de datos vectorial
Uso de una base de conocimientos médicos OpenSearch del Servicio
Amazon OpenSearch Service puede gestionar grandes volúmenes de datos médicos de alta dimensión. Es un servicio gestionado que facilita la búsqueda de alto rendimiento y el análisis en tiempo real. Es ideal como base de datos vectorial para aplicaciones RAG. OpenSearch El servicio actúa como una herramienta de back-end para administrar grandes cantidades de datos no estructurados o semiestructurados, como registros médicos, artículos de investigación y notas clínicas. Sus capacidades de búsqueda semántica avanzada le ayudan a recuperar información relevante desde el punto de vista contextual. Esto lo hace particularmente útil en aplicaciones como los sistemas de apoyo a la toma de decisiones clínicas, las herramientas de resolución de consultas de los pacientes y los sistemas de gestión del conocimiento sanitario. Por ejemplo, un médico puede encontrar rápidamente datos relevantes de pacientes o estudios de investigación que coincidan con síntomas o protocolos de tratamiento específicos. Esto ayuda a los médicos a tomar decisiones basadas en la información más relevante up-to-date.
OpenSearch El servicio puede escalar y gestionar la indexación y consulta de datos en tiempo real. Esto lo hace ideal para entornos de atención médica dinámicos donde el acceso oportuno a información precisa es fundamental. Además, cuenta con capacidades de búsqueda multimodales que son óptimas para búsquedas que requieren múltiples entradas, como imágenes médicas y notas médicas. Al implementar las aplicaciones de OpenSearch Service for Health, es fundamental definir campos y mapeos precisos para optimizar la indexación y la recuperación de datos. Los campos representan los datos individuales, como los registros de los pacientes, los historiales médicos y los códigos de diagnóstico. Los mapeos definen cómo se almacenan estos campos (en forma incrustada o en forma original) y cómo se consultan. Para las aplicaciones sanitarias, es esencial establecer mapeos que se adapten a varios tipos de datos, incluidos los datos estructurados (como los resultados de las pruebas numéricas), los datos semiestructurados (como las notas de los pacientes) y los datos no estructurados (como las imágenes médicas)
En OpenSearch Service, puede realizar búsquedas neuronales
Crear una arquitectura RAG
Puede implementar una solución RAG personalizada que utilice los agentes de Amazon Bedrock para consultar una base de conocimientos médicos en OpenSearch Service. Para ello, debe crear una AWS Lambda función que pueda interactuar con el Servicio y OpenSearch consultarlo. La función Lambda incrusta la pregunta introducida por el usuario accediendo a un punto final de incrustación de texto de SageMaker IA. El agente de Amazon Bedrock transfiere parámetros de consulta adicionales como entradas a la función Lambda. La función consulta la base de conocimientos médicos de OpenSearch Service, que devuelve el contenido médico relevante. Tras configurar la función Lambda, agréguela como grupo de acciones en el agente de Amazon Bedrock. El agente de Amazon Bedrock toma la entrada del usuario, identifica las variables necesarias, pasa las variables y la pregunta a la función Lambda y, a continuación, inicia la función. La función devuelve un contexto que ayuda al modelo básico a proporcionar una respuesta más precisa a la pregunta del usuario.
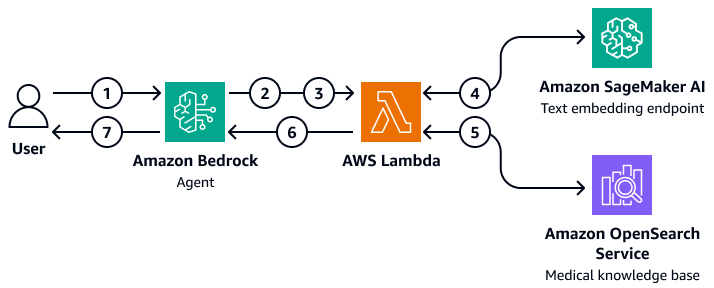
En el diagrama, se muestra el siguiente flujo de trabajo:
-
Un usuario envía una pregunta al agente de Amazon Bedrock.
-
El agente de Amazon Bedrock selecciona qué grupo de acción iniciar.
-
El agente de Amazon Bedrock inicia una AWS Lambda función y le pasa parámetros.
-
La función Lambda inicia el modelo de incrustación de texto de Amazon SageMaker AI para incrustar la pregunta del usuario.
-
La función Lambda transfiere el texto incrustado y los parámetros y filtros adicionales a Amazon OpenSearch Service. Amazon OpenSearch Service consulta la base de conocimientos médicos y devuelve los resultados a la función Lambda.
-
La función Lambda devuelve los resultados al agente de Amazon Bedrock.
-
El modelo básico del agente Amazon Bedrock genera una respuesta basada en los resultados y la devuelve al usuario.
Para situaciones en las que se trate de un filtrado más complejo, puede utilizar un filtro personalizado LangChain recuperador. Cree este recuperador configurando un cliente de búsqueda vectorial de OpenSearch Service que se cargue directamente en LangChain. Esta arquitectura le permite pasar más variables para crear los parámetros del filtro. Una vez configurado el retriever, utilice el modelo Amazon Bedrock y el retriever para configurar una cadena de preguntas y respuestas de recuperación. Esta cadena organiza la interacción entre el modelo y el recuperador al pasar la entrada del usuario y los posibles filtros al recuperador. El recuperador devuelve el contexto relevante que ayuda al modelo básico a responder a la pregunta del usuario.
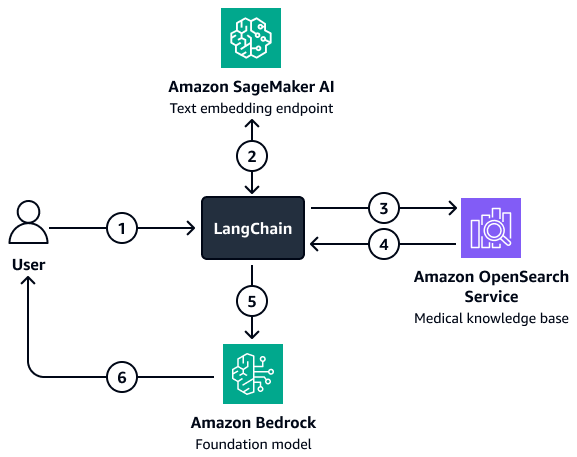
En el diagrama, se muestra el siguiente flujo de trabajo:
-
Un usuario envía una pregunta al LangChain agente recuperador.
-
La LangChain El agente de recuperación envía la pregunta al punto final de incrustación de texto de Amazon SageMaker AI para incrustarla.
-
La LangChain El agente de recuperación pasa el texto incrustado a Amazon OpenSearch Service.
-
Amazon OpenSearch Service devuelve los documentos recuperados al LangChain agente recuperador.
-
La LangChain El agente retriever pasa la pregunta del usuario y el contexto recuperado al modelo básico de Amazon Bedrock.
-
El modelo básico genera una respuesta y la envía al usuario.
Paso 5: LLMs Utilízalo para responder a preguntas médicas
Los pasos anteriores le ayudan a crear una aplicación de inteligencia médica que pueda recuperar el historial médico del paciente y resumir los medicamentos relevantes y los posibles diagnósticos. Ahora, crea la capa de generación. Esta capa utiliza las capacidades generativas de un LLM en Amazon Bedrock, como Llama 3, para aumentar la producción de la aplicación.
Cuando un médico introduce una consulta, la capa de recuperación de contexto de la aplicación lleva a cabo el proceso de recuperación a partir del gráfico de conocimiento y devuelve los registros principales relacionados con el historial, la demografía, los síntomas, el diagnóstico y los resultados del paciente. De la base de datos vectorial, también recupera notas descriptivas y en tiempo real sobre las interacciones entre el médico y el paciente, información sobre la evaluación de las imágenes diagnósticas, resúmenes de los informes de análisis de laboratorio e información procedente de una enorme cantidad de libros académicos y de investigación médica. Estos resultados más recuperados, la consulta del médico y las indicaciones (que están diseñadas para seleccionar las respuestas en función de la naturaleza de la consulta) se pasan luego al modelo básico de Amazon Bedrock. Esta es la capa de generación de respuestas. El LLM utiliza el contexto recuperado para generar una respuesta a la consulta del médico. La siguiente figura muestra el end-to-end flujo de trabajo de los pasos de esta solución.
Puede utilizar un modelo básico previamente entrenado en Amazon Bedrock, como Llama 3, para una variedad de casos de uso que debe gestionar la aplicación de inteligencia médica. El LLM más eficaz para una tarea determinada varía según el caso de uso. Por ejemplo, un modelo previamente entrenado podría ser suficiente para resumir las conversaciones entre el paciente y el médico, buscar entre los medicamentos y las historias clínicas de los pacientes y obtener información a partir de conjuntos de datos médicos internos y conjuntos de conocimientos científicos. Sin embargo, podría ser necesario un LLM perfeccionado para otros casos de uso complejos, como las evaluaciones de laboratorio en tiempo real, las recomendaciones de procedimientos médicos y las predicciones de los resultados de los pacientes. Puede afinar un LLM entrenándolo en conjuntos de datos del dominio médico. Los requisitos específicos o complejos de la salud y las ciencias de la vida impulsan el desarrollo de estos modelos ajustados.
Para obtener más información sobre cómo ajustar un LLM o elegir un LLM existente que se haya formado con datos del dominio médico, consulte Uso de modelos lingüísticos de gran tamaño para casos de uso de la salud y las ciencias de la vida.
Alineación con el marco de AWS Well-Architected
La solución se alinea con los seis pilares del AWS Well-Architected
-
Excelencia operativa: la arquitectura está desacoplada para una supervisión y actualizaciones eficientes. Amazon Bedrock tiene agentes y le AWS Lambda ayuda a implementar y deshacer herramientas rápidamente.
-
Seguridad: esta solución está diseñada para cumplir con las normas sanitarias, como la HIPAA. También puede implementar el cifrado, un control de acceso detallado y las barandillas Amazon Bedrock para ayudar a proteger los datos de los pacientes.
-
Fiabilidad: los servicios AWS gestionados, como Amazon OpenSearch Service y Amazon Bedrock, proporcionan la infraestructura necesaria para la interacción continua con los modelos.
-
Eficiencia de rendimiento: la solución RAG recupera los datos relevantes rápidamente mediante búsquedas semánticas optimizadas y consultas cifradas, mientras que un agente enrutador identifica las rutas óptimas para las consultas de los usuarios.
-
Optimización de costes: el pay-per-token modelo de Amazon Bedrock y la arquitectura RAG reducen los costes de inferencia y formación previa.
-
Sostenibilidad: el uso de infraestructura y pay-per-token computación sin servidores minimiza el uso de recursos y mejora la sostenibilidad.
