Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Información general del marco de
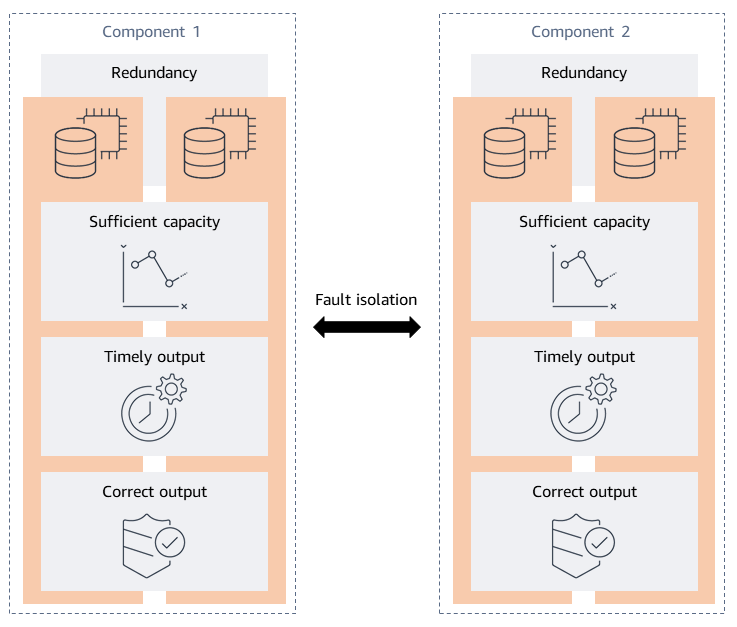
El marco de análisis de la resiliencia se desarrolló identificando las propiedades de resiliencia deseadas de una carga de trabajo. Las propiedades deseadas son las cosas que usted quiere que sean ciertas acerca del sistema. Por lo general, la resiliencia se mide en función de la disponibilidad, por lo que cinco propiedades son las características de un sistema distribuido de alta disponibilidad: redundancia, capacidad suficiente, producción puntual, salida correcta y aislamiento de fallas. Estas propiedades se muestran en el siguiente diagrama.
-
Redundancia: la tolerancia a las fallas se logra mediante una redundancia que elimina los puntos únicos de falla ()SPOFs. La redundancia puede abarcar desde componentes de repuesto de la carga de trabajo hasta réplicas completas de todo el conjunto de aplicaciones. Al considerar la redundancia para sus aplicaciones, es importante tener en cuenta el nivel de redundancia que proporcionan la infraestructura, los almacenes de datos y las dependencias que utiliza. Por ejemplo, Amazon DynamoDB y Amazon Simple Storage Service (Amazon S3) proporcionan redundancia al replicar los datos en varias zonas de disponibilidad de una región AWS Lambda y ejecutan sus funciones en varios nodos de trabajo de varias zonas de disponibilidad. Para cada servicio que utilice, tenga en cuenta lo que proporciona el servicio y lo que debe diseñar.
-
Capacidad suficiente: su carga de trabajo requiere recursos suficientes para funcionar según lo previsto. Los recursos incluyen memoria, ciclos de CPU, subprocesos, almacenamiento, rendimiento, cuotas de servicio y muchos otros.
-
Resultados puntuales: cuando los clientes utilizan su carga de trabajo, esperan que desempeñe la función prevista en un período de tiempo razonable. A menos que el servicio incluya un acuerdo de nivel de servicio (SLA) en materia de latencia, sus expectativas se basan generalmente en datos empíricos, es decir, en su propia experiencia. Por lo general, se considera que esta experiencia media del cliente es la latencia media (P50) del sistema. Si su carga de trabajo tarda más de lo esperado, esta latencia puede afectar a la experiencia de sus clientes.
-
Salida correcta: se requiere la salida correcta del software de la carga de trabajo para que proporcione la funcionalidad prevista. Un resultado incorrecto o incompleto puede ser peor que no recibir respuesta alguna.
-
Aislamiento de fallas: el aislamiento de fallas restringe el alcance del impacto al contenedor de fallas previsto cuando se produce una falla. Garantiza que los componentes específicos de la carga de trabajo fallen juntos y, al mismo tiempo, evita que una falla se propague en cascada a otros componentes no deseados. También ayuda a limitar el alcance del impacto de su carga de trabajo en los clientes. El aislamiento de errores es algo diferente de las cuatro propiedades anteriores, ya que acepta que ya se ha producido un error, pero debe contenerse. Puede crear un aislamiento de errores en la infraestructura, las dependencias y las funciones de software.
Cuando se infringe una propiedad deseada, se puede provocar que una carga de trabajo no esté disponible o se perciba que no está disponible. Basándonos en estas propiedades de resiliencia deseadas y en nuestra experiencia trabajando con muchos AWS clientes, hemos identificado cinco categorías de errores comunes: puntos únicos de fallo, carga excesiva, latencia excesiva, errores y configuraciones incorrectas, y destino compartido, que abreviamos como SEEMS. Estas proporcionan un método coherente para clasificar los posibles modos de fallo y se describen en la siguiente tabla.
Categoría de fallo |
Viola |
Definición |
|---|---|---|
Puntos únicos de falla (SPOFs) |
Redundancia |
Una falla en un solo componente interrumpe el sistema debido a la falta de redundancia del componente. |
Carga excesiva |
Capacidad suficiente |
El consumo excesivo de un recurso debido a una demanda o un tráfico excesivos impide que el recurso desempeñe la función esperada. Esto puede incluir alcanzar límites y cuotas, lo que provoca la limitación y el rechazo de las solicitudes. |
Latencia excesiva |
Salida puntual |
El procesamiento del sistema o la latencia del tráfico de red superan el tiempo esperado, los objetivos de nivel de servicio (SLOs) o los acuerdos de nivel de servicio () esperados. SLAs |
Configuración errónea y errores |
Salida correcta |
Los errores de software o una mala configuración del sistema provocan un resultado incorrecto. |
Fecha compartida |
Aislamiento de fallas |
Un fallo provocado por cualquiera de las categorías de fallos anteriores sobrepasa los límites de aislamiento de fallos previstos y se extiende en cascada a otras partes del sistema o a otros clientes. |
