Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Uso de sugerencias de unión en Spark SQL
With Spark 3.0, puede especificar el tipo de algoritmo de unión que desee Spark para usar en tiempo de ejecución. La estrategia de unión sugiereBROADCAST,MERGE, SHUFFLE_HASHSHUFFLE_REPLICATE_NL, e instruye Spark usar la estrategia sugerida en cada relación especificada al unirla con otra relación. En esta sección se analizan en detalle las sugerencias sobre la estrategia de unión.
EMISIÓN
En una combinación de Broadcast Hash, uno de los conjuntos de datos es significativamente más pequeño que el otro. Como el conjunto de datos más pequeño puede caber en la memoria, se transmite a todos los ejecutores del clúster. Una vez difundidos los datos, se realiza una unión hash estándar. La unión de Broadcast Hash se realiza en dos pasos:
-
Transmisión: el conjunto de datos más pequeño se transmite a todos los ejecutores del clúster.
-
Combinación mediante hash: el conjunto de datos más pequeño se procesa mediante hash en todos los ejecutores y, a continuación, se une al conjunto de datos más grande.
No hay ninguna operaciónsort. merge Al unir tablas de datos grandes con tablas de dimensiones más pequeñas utilizadas para realizar una unión de esquemas en estrella, Broadcast Hash es el algoritmo de unión más rápido. El siguiente ejemplo muestra cómo funciona una unión de Broadcast Hash. La parte de unión con la sugerencia se difunde, independientemente del límite de tamaño especificado en la spark.sql.autoBroadcastJoinThreshold propiedad. Si ambos lados de la unión tienen sugerencias de emisión, se emitirá el que tenga el tamaño más pequeño (según las estadísticas). El valor predeterminado de la spark.sql.autoBroadcastJoinThreshold propiedad es de 10 MB. Esto configura el tamaño máximo, en bytes, de una tabla que se transmite a todos los nodos trabajadores al realizar una unión.
Los siguientes ejemplos proporcionan la consulta, el EXPLAIN plan físico y el tiempo que tarda en ejecutarse la consulta. La consulta requiere menos tiempo de procesamiento si usas la BROADCASTJOIN sugerencia para forzar la unión de una transmisión, como se muestra en el segundo EXPLAIN plan de ejemplo.
SQL Query : select table1.id,table1.col,table2.id,table2.int_col from table1 join table2 on table1.id = table2.id == Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- SortMergeJoin [id#80L], [id#95L], Inner :- Sort [id#80L ASC NULLS FIRST], false, 0 : +- Exchange hashpartitioning(id#80L, 36), ENSURE_REQUIREMENTS, [id=#725] : +- Filter isnotnull(id#80L) : +- Scan ExistingRDD[id#80L,col#81] +- Sort [id#95L ASC NULLS FIRST], false, 0 +- Exchange hashpartitioning(id#95L, 36), ENSURE_REQUIREMENTS, [id=#726] +- Filter isnotnull(id#95L) +- Scan ExistingRDD[id#95L,int_col#96L] Number of records processed: 799541 Querytime : 21.87715196 seconds
SQL Query : select /*+ BROADCASTJOIN(table1)*/ table1.id,table1.col,table2.id,table2.int_col from table1 join table2 on table1.id = table2.id Physical Plan == AdaptiveSparkPlan isFinalPlan=false\n +- BroadcastHashJoin [id#271L], [id#286L], Inner, BuildLeft, false :- BroadcastExchange HashedRelationBroadcastMode(List(input[0, bigint, false]),false), [id=#955] : +- Filter isnotnull(id#271L) : +- Scan ExistingRDD[id#271L,col#272] +- Filter isnotnull(id#286L) +- Scan ExistingRDD[id#286L,int_col#287L] Number of records processed: 799541 Querytime : 15.35717314 seconds
MERGE
Se prefiere la combinación Shuffle Sort Merge cuando ambos conjuntos de datos son grandes y no caben en la memoria. Como su nombre indica, esta unión incluye las tres fases siguientes:
-
Fase de mezcla: se mezclan los dos conjuntos de datos de la consulta de unión.
-
Fase de ordenación: los registros se ordenan por la clave de unión en ambos lados.
-
Fase de fusión: ambos lados de la condición de unión se repiten en función de la clave de combinación.
La siguiente imagen muestra una visualización en un gráfico acíclico dirigido (DAG) de una unión aleatoria, ordenada y combinada. Ambas tablas se leen en las dos primeras etapas. En la siguiente etapa (etapa 17), se barajan, se ordenan y, al final, se combinan.
Nota: Algunas de las etapas de esta imagen se muestran como omitidas porque esos pasos se completaron en etapas anteriores. Esos datos se almacenaron en caché o se conservaron para su uso en estas etapas. |
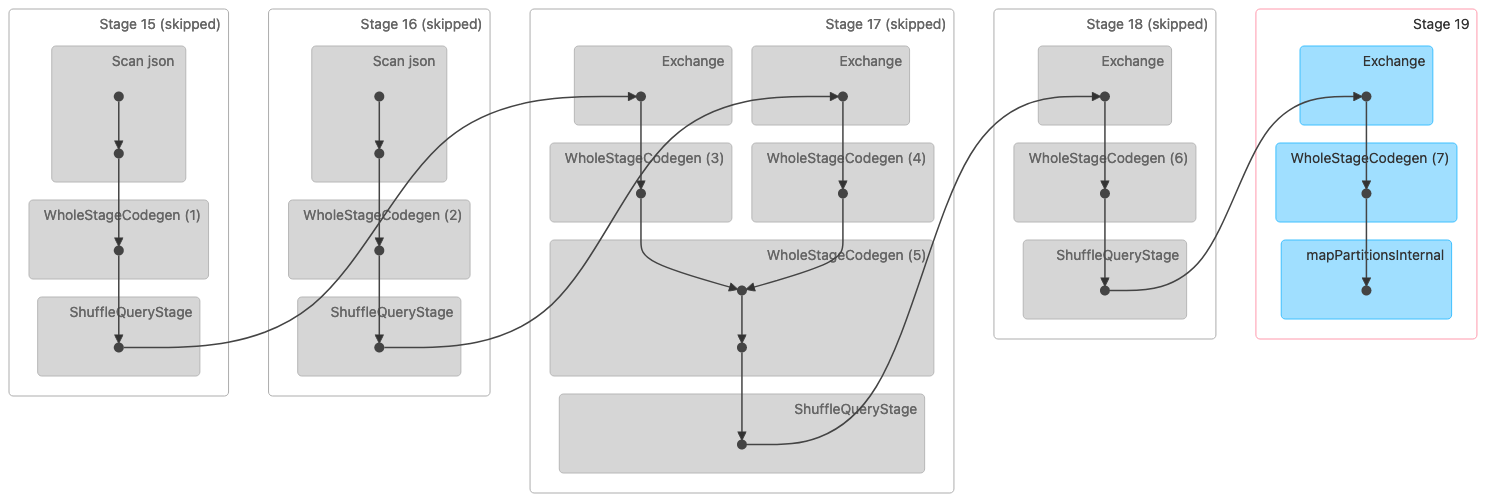
El siguiente es un plan físico que indica una unión por orden y combinación.
== Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- SortMergeJoin [id#320L], [id#335L], Inner :- Sort [id#320L ASC NULLS FIRST], false, 0 : +- Exchange hashpartitioning(id#320L, 36), ENSURE_REQUIREMENTS, [id=#1018] : +- Filter isnotnull(id#320L) : +- Scan ExistingRDD[id#320L,col#321] +- Sort [id#335L ASC NULLS FIRST], false, 0 +- Exchange hashpartitioning(id#335L, 36), ENSURE_REQUIREMENTS, [id=#1019] +- Filter isnotnull(id#335L) +- Scan ExistingRDD[id#335L,int_col#336L]
SHUFFLE_HASH
La combinación Shuffle Hash, como su nombre indica, funciona mezclando ambos conjuntos de datos. Las mismas claves de ambos lados terminan en la misma partición o tarea. Una vez mezclados los datos, el más pequeño de los dos conjuntos de datos se convierte en cubos y, a continuación, se realiza una combinación de hash dentro de la partición. Una unión de hash aleatorio es diferente de una unión de hash de transmisión porque no se difunde todo el conjunto de datos. Una unión de Shuffle Hash se divide en dos fases:
-
Fase de mezcla: ambos conjuntos de datos se mezclan.
-
Fase de combinación de hash: el lado más pequeño de los datos se tritura, se agrupa y, a continuación, se une al lado más grande en todas las particiones.
No es necesario ordenar con Shuffle Hash las uniones dentro de las particiones. La siguiente imagen muestra las fases de la unión de Shuffle Hash. Los datos se leen inicialmente, luego se mezclan y, a continuación, se crea un hash que se utiliza para la unión.
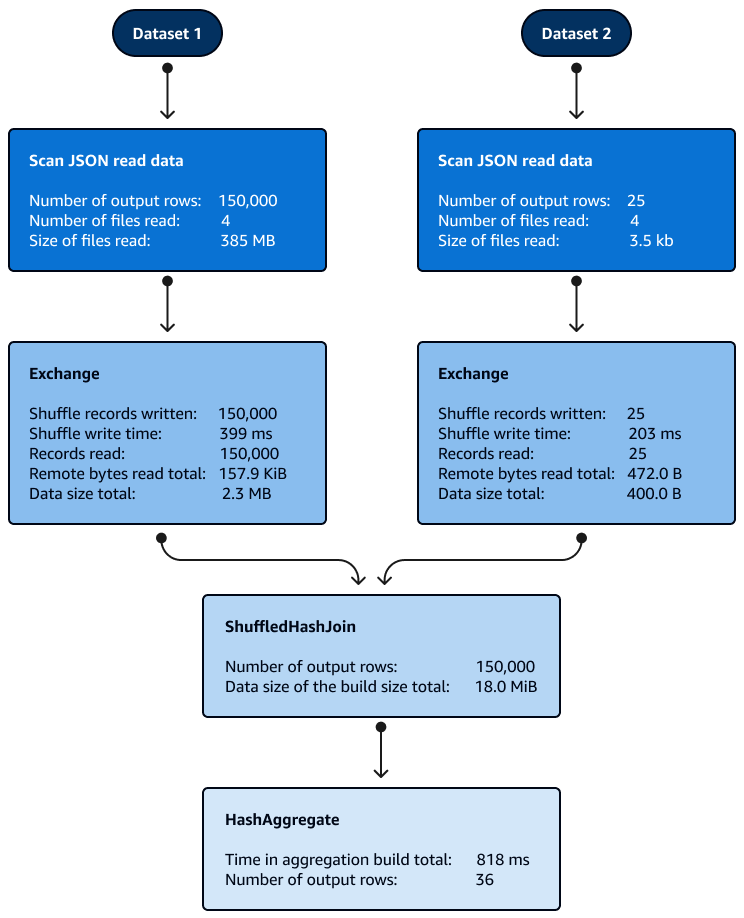
De forma predeterminada, el optimizador elige la combinación Shuffle Hash cuando no se puede utilizar la combinación Broadcast Hash. Según el tamaño del umbral de unión por hash de transmisión (spark.sql.autoBroadcastJoinThreshold) y el número de particiones aleatorias (spark.sql.shuffle.partitions) elegidas, utiliza la unión por hash aleatorio cuando la única partición del SQL lógico es lo suficientemente pequeña como para crear una tabla hash local.
SHUFFLE_REPLICATE_NL
La unión de bucles Shuffle-and-Replicate anidados, también conocida como unión de productos cartesianos, funciona de forma muy similar a una unión de hash de transmisión, excepto que el conjunto de datos no se transmite.
En este algoritmo de unión, la reproducción aleatoria no se refiere a una mezcla real porque los registros con las mismas claves no se envían a la misma partición. En su lugar, toda la partición de ambos conjuntos de datos se copia a través de la red. Cuando las particiones de los conjuntos de datos están disponibles, se realiza una unión de bucles anidados. Si hay X varios registros en el primer conjunto de datos y Y varios registros en el segundo conjunto de datos de cada partición, cada registro del segundo conjunto de datos se une a todos los registros del primer conjunto de datos. Esto continúa formando un bucle de X × Y veces en cada partición.
