Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Opciones de restauración
En las siguientes secciones, se proporcionan dos opciones de restauración de bases de datos para SQL Server en Amazon Elastic Compute Cloud (Amazon EC2), cuando las copias de seguridad se encuentran en las instalaciones.
Uso de Amazon S3
Este enfoque de restauración de bases de datos de SQL Server utiliza los comandos de Amazon Simple Storage Service (Amazon S3) para AWS Command Line Interface (AWS CLI) o la API de Amazon S3 a fin de cargar los archivos de copia de seguridad directamente en un bucket de S3.
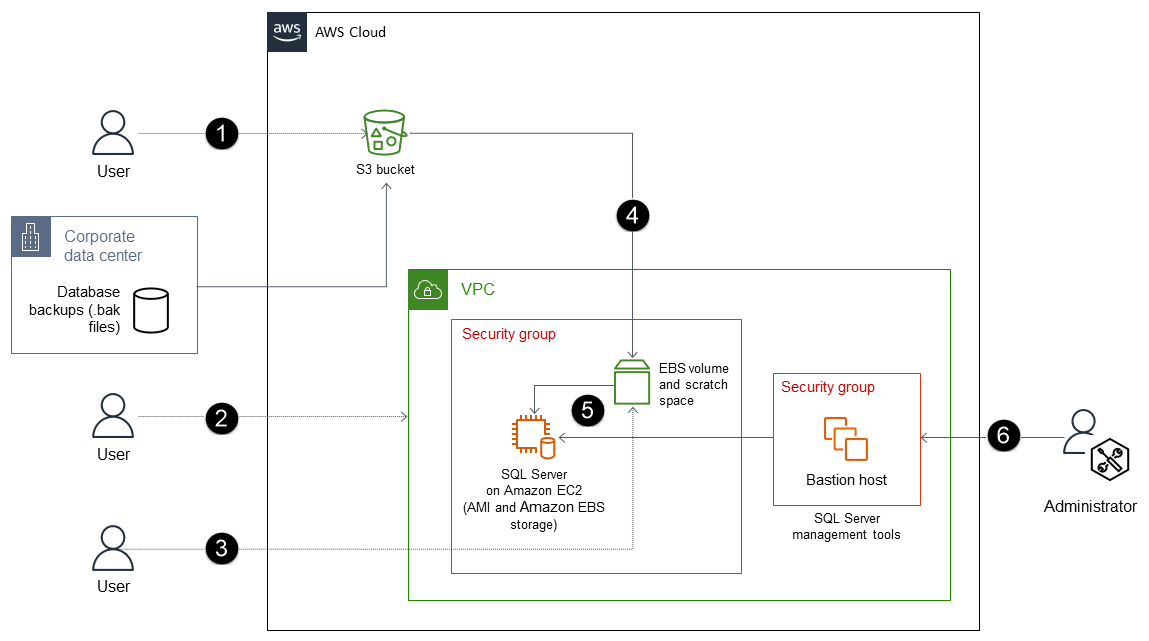
El proceso consta de los siguientes pasos:
-
Cree un bucket de S3 (o utilice uno existente) para almacenar los archivos de copia de seguridad y transfiera los archivos de copia de seguridad (.bak) de su base de datos en las instalaciones al bucket de S3 mediante la CLI de AWS o la API de Amazon S3.
-
Implemente SQL Server en una EC2 instancia optimizada para EBS mediante una Amazon Machine Image (AMI) de SQL Server. Esta AMI debe contener volúmenes de EBS configurados con una partición del sistema operativo, una partición DATA, una partición LOG, almacenamiento tempdb (NVMe) y espacio temporal.
-
(Opcional) Adjunte un volumen de EBS que no sea raíz a la instancia. EC2
-
Copie los archivos de copia de seguridad en el volumen de EBS que no sea raíz.
-
Restaure los archivos de respaldo del volumen de EBS a SQL Server de la instancia. EC2
-
Utilice las herramientas de administración de SQL Server para administrar su base de datos.
Using AWS DataSync y Amazon FSx
Este enfoque de restauración de bases de datos de SQL Server se utiliza AWS DataSync para transferir los archivos de respaldo a Amazon FSx para Windows File Server.
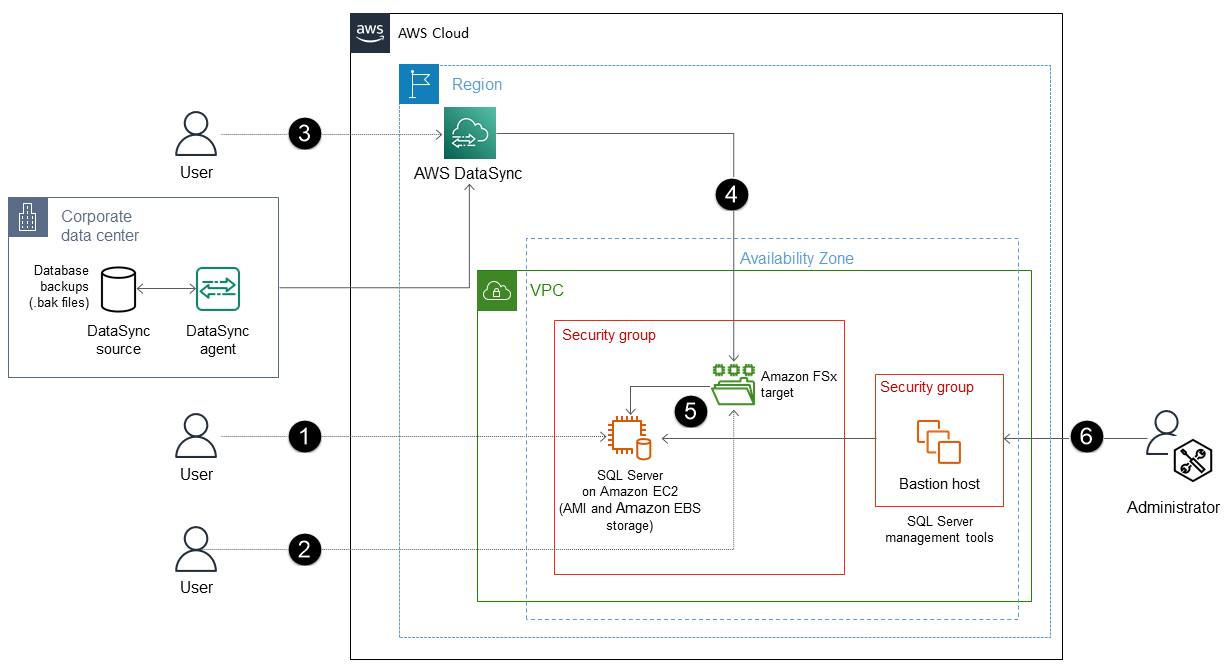
El proceso consta de estos pasos:
-
Implemente SQL Server en una EC2 instancia optimizada para EBS con una AMI adjunta NVMe que contenga volúmenes de EBS configurados con OS, DATA, LOG y tempdb. (Por ejemplo, puede usar la clase de instancia optimizada para memoria
r5d.large). -
FSx Utilícelo con Windows File Server para crear un servidor de archivos. Se puede utilizar como ubicación de almacenamiento temporal para descargar archivos de copia de seguridad (.bak) de SQL Server desde su entorno en las instalaciones.
-
Cree un DataSync punto de conexión y un agente para el servidor de FSx archivos de Amazon.
-
DataSync automatiza la sincronización de datos entre el almacenamiento local y el servidor de FSx archivos de Amazon sin necesidad de Amazon S3.
-
Restaure los archivos de respaldo del servidor de FSx archivos de Amazon a SQL Server de la EC2 instancia.
-
Utilice las herramientas de administración de SQL Server para administrar su base de datos.
nota
Amazon EC2 ofrece Microsoft SQL Server en Microsoft Windows Server AMIs
Uso de la puerta de enlace de archivo de Amazon S3
Puede utilizar la puerta de enlace de archivo de Amazon S3
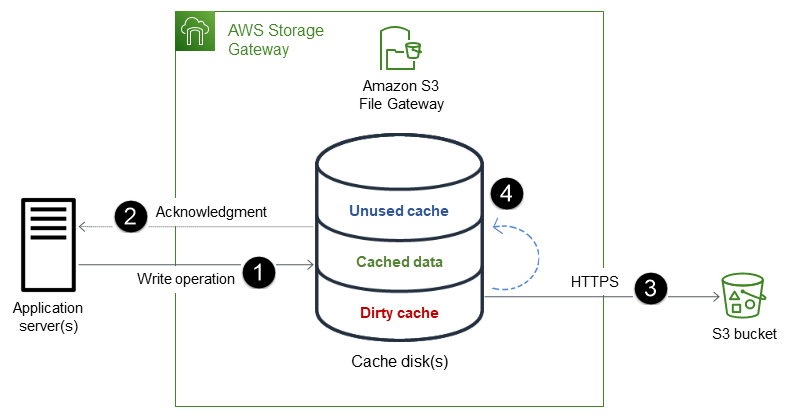
El proceso consta de los siguientes pasos:
-
Los datos se escriben en el disco de caché local de la puerta de enlace de archivo.
-
Una vez que los datos se mantienen de forma segura en la caché local, la puerta de enlace de archivo confirma que se ha completado la operación de escritura en la aplicación cliente.
-
La puerta de enlace de archivo transfiere los datos al bucket de S3 de forma asincrónica. Optimiza la transferencia de datos y utiliza HTTPS para cifrar datos en tránsito.
-
Una vez que los datos se cargan en el bucket de S3, permanecen en la caché local de la puerta de enlace de archivo hasta que se expulsan.
