Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Ejemplo de implementación de una estrategia moderna de datos de salud
AWS proporciona arquitecturas de referencia que las organizaciones sanitarias pueden utilizar para comprender y crear plataformas de datos que respalden un enfoque ágil de los datos. La siguiente arquitectura de referencia ilustra una arquitectura de malla de datos
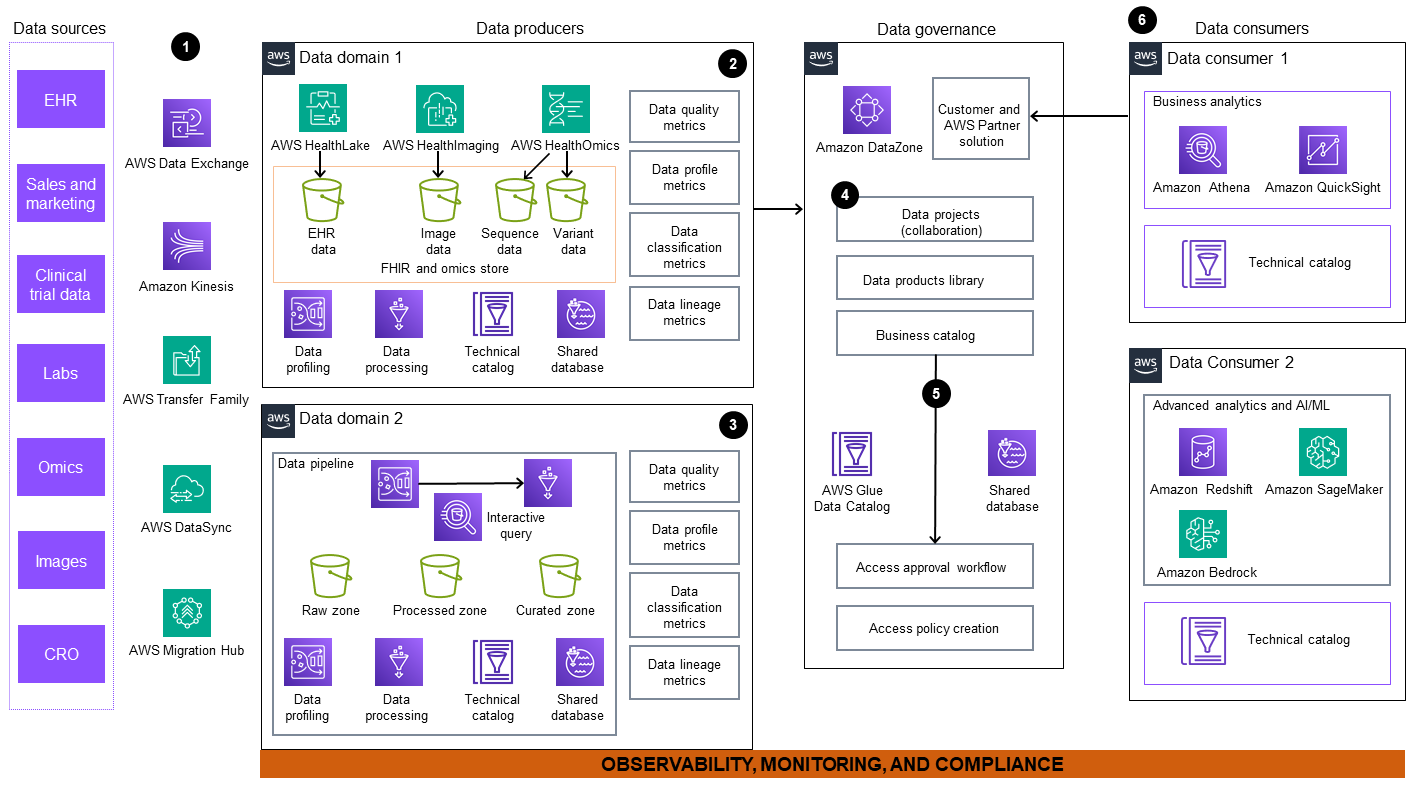
El diagrama de arquitectura incluye los siguientes componentes:
-
Los datos se ingieren de fuentes de datos externas e internas. Estas fuentes incluyen, pero no se limitan a, sistemas de registros electrónicos de salud (EHR), laboratorios, instalaciones de secuenciación y centros de diagnóstico por imágenes. AWS ofrece un conjunto de servicios como AWS Data Exchange
Amazon Kinesis ,, AWS Transfer FamilyAWS DataSyncAWS Migration HubAWS HealthLake , y AWS Glue (ETL). Puede utilizar estos servicios para migrar su conjunto de datos interno y suscribirse a conjuntos de datos internos y externos. -
El dominio de datos 1 comprende un flujo de trabajo integral para procesar datos multimodales orientados al paciente, incluidos datos clínicos, ómicos y de imagen. Los datos clínicos de la EHR se ingieren y almacenan en un almacén de HealthLake datos, un servicio gestionado especialmente diseñado para los datos clínicos. AWS HealthOmics
, un servicio diseñado específicamente para datos ómicos, gestiona el flujo de trabajo y el almacenamiento de secuencias y variantes. Los datos de imagen se ingieren y almacenan en. AWS HealthImaging Luego, estos datos se transforman en productos listos para el consumo y se publican en un mercado de datos empresariales para una amplia accesibilidad y uso. -
En el dominio de datos 2, Amazon Kinesis AWS Glue, e AWS Data Exchange ingiera datos sin procesar en una canalización de datos. Las fuentes de datos pueden incluir registros públicos, monitoreo remoto de pacientes y programas de planificación de recursos empresariales (ERP). La canalización carga los datos sin procesar en depósitos de Amazon Simple Storage Service (Amazon S3)
. Estos datos se limpian, seleccionan, transforman y almacenan para publicarlos como un producto de datos. Amazon Athena ofrece un motor de consultas interactivo que los productores de datos pueden utilizar para transformar los datos mediante SQL. AWS Glue DataBrew proporciona capacidades visuales de transformación, normalización y creación de perfiles de datos. -
Amazon DataZone
gestiona la publicación de metadatos, proyectos de datos colaborativos y la biblioteca de productos de datos en el catálogo empresarial central. -
Un portal de análisis de datos unificado permite la colaboración en torno a los datos al proporcionar una visión de los productos de datos mediante una gobernanza federada. Amazon DataZone permite un flujo de trabajo de autoservicio con el AWS Glue Data Catalog respaldo de AWS Lake Formation, para que los usuarios puedan compartir, buscar, descubrir datos y solicitar permiso para su consumo.
-
Los consumidores de datos pueden acceder a los datos, crear vistas posteriores y utilizar herramientas diseñadas específicamente, como Amazon Athena, Amazon, Amazon QuickSight Redshift, Amazon SageMaker
AI y Amazon Bedrock para hacer lo siguiente: -
Análisis operativo
-
Informática clínica
-
Investigación
-
Participación clínica y del paciente
Los consumidores de datos también pueden desarrollar aplicaciones innovadoras mediante el uso de la IA generativa y pueden publicar productos de datos en el catálogo empresarial.
-
Para obtener más información sobre la arquitectura de malla de datos, consulte ¿Qué es una malla de datos?
IA generativa
Las organizaciones sanitarias utilizan la IA generativa para una variedad de aplicaciones, desde la automatización de la interpretación de imágenes médicas hasta la generación de recomendaciones de diagnóstico y planes de tratamiento basados en datos textuales y de imágenes. La adopción de la IA generativa está acelerando la innovación y mejorando la eficiencia en todo el proceso asistencial. El nuevo enfoque en la IA generativa ha obligado a la sanidad a ampliar su enfoque en los datos para incluir más tipos de datos no estructurados, lo que ha ampliado el número y la variedad de casos de uso que se prestan a la IA. En general, las organizaciones pueden elegir entre cuatro patrones, según su caso de uso, para implementar soluciones de IA generativa:
-
Ingeniería rápida: en la ingeniería rápida, los usuarios proporcionan datos relevantes como contexto, lo que guía el modelo de IA generativa para crear el contenido que desean. Las organizaciones con una estrategia de datos de salud moderna pueden garantizar que los datos relevantes se puedan descubrir, compartir y consumir fácilmente.
-
Generación aumentada de recuperación (RAG): el patrón RAG se basa en una ingeniería rápida. En lugar de que un usuario proporcione datos relevantes, un programa intercepta la pregunta o entrada del usuario. El programa busca en un repositorio de datos para recuperar el contenido relevante para la pregunta o entrada. El programa introduce los datos que encuentra en el modelo de IA generativa para generar contenido. Una estrategia moderna de datos de atención médica permite la conservación e indexación de los datos empresariales. Luego, los datos se pueden buscar y usar como contexto para preguntas o preguntas, lo que ayuda a un modelo de lenguaje amplio (LLM) a generar respuestas.
Su organización puede utilizar los dos patrones siguientes para centrar los resultados del modelo de IA generativa en la generación de contenido adecuado al contexto de sus datos.
-
Ajuste: con este patrón, su organización puede ir un paso más allá y personalizar los modelos de IA generativa. Esto implica ajustar los modelos a partir de una pequeña muestra de datos específicos de la organización. Como el tamaño de la muestra es pequeño, este patrón proporciona un equilibrio entre el costo y la personalización. Para evitar sesgos en los resultados del modelo, utilice un conjunto de datos de muestra pequeño que sea lo más diverso y representativo posible de los patrones de datos de su organización. Una estrategia moderna de datos de salud permite el acceso eficiente a una amplia variedad de datos para preparar los conjuntos de datos de muestra.
-
Cree su propio modelo: si su organización necesita generar contenido a partir de grandes volúmenes de datos altamente especializados y los tres patrones anteriores no son adecuados, puede crear sus propios modelos.
Una estrategia de datos moderna desempeña un papel fundamental en las soluciones de IA generativa, ya que ayuda a garantizar que los datos tengan las siguientes características:
-
Datos de alta calidad para respaldar la precisión
-
Datos en tiempo real o casi en tiempo real para garantizar que los resultados del modelo sean relevantes
-
Múltiples modalidades de datos en una variedad de fuentes de datos para proporcionar al modelo acceso a conjuntos de datos enriquecidos para generar contenido
El siguiente diagrama muestra la implementación de una estrategia moderna de datos de salud que utiliza una arquitectura de malla de datos para respaldar las soluciones generativas de IA.
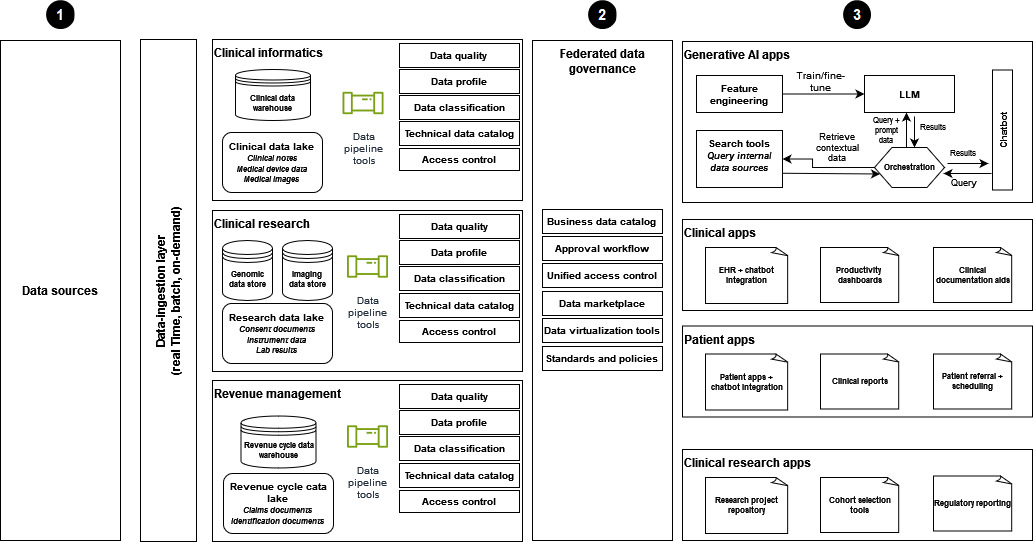
-
Los datos se obtienen de diversas fuentes de datos en los ámbitos de la informática clínica, la investigación clínica y la gestión de ingresos, y los datos se ponen a disposición de la organización sanitaria.
-
La gobernanza de datos federada ayuda a garantizar un control de acceso estricto para el intercambio de datos y el acceso unificado.
-
Entre los consumidores de datos se encuentran los siguientes:
-
Aplicaciones de IA generativa, especialmente aquellas que utilizan datos para entrenar y afinar LLMs. Estas aplicaciones utilizan datos empresariales para los chatbots de preguntas y respuestas a fin de mejorar la eficiencia operativa y las experiencias de los pacientes y los proveedores.
-
Aplicaciones clínicas equipadas con herramientas como chatbots integrados en la EHR, paneles de productividad y material de documentación.
-
Aplicaciones centradas en el paciente para mejorar las experiencias de los pacientes. Estas aplicaciones incluyen interacciones con chatbots, informes clínicos y procesos eficientes de derivación y programación.
-
Investigación clínica, con un repositorio de proyectos de investigación y aplicaciones diseñadas para el análisis de cohortes y la elaboración de informes reglamentarios.
-
Con esta arquitectura, las partes interesadas de su organización pueden centrarse en seleccionar y administrar los datos que recopilan de otras fuentes y, al mismo tiempo, hacer que sus propios datos sean accesibles para el resto de la organización. Pueden usar las herramientas que están disponibles en la capa de gobierno de datos federados para definir los metadatos, administrar los flujos de trabajo de aprobación de accesos y definir y aplicar políticas. Además, la capa de gobierno de datos federados proporciona un control de acceso centralizado. Esto crea un entorno para seleccionar una variedad de fuentes de datos y actualizar los activos de datos de alta calidad con una frecuencia específica para mantener la relevancia. AWS ofrece un conjunto completo de funciones para satisfacer sus necesidades generativas de IA. Amazon Bedrock
