Visualización de datos de rendimiento del clúster
Cuando utiliza las métricas de clúster en Amazon Redshift, puede realizar las siguientes tareas de rendimiento comunes:
-
Determinar si las métricas de clúster están fuera de lo normal en un intervalo de tiempo especificado y, si es así, identificar las consultas responsables de este error en el rendimiento.
-
Comprobar si las consultas actuales o históricas están impactando en el rendimiento del clúster. Si identifica una consulta problemática, puede ver sus detalles incluyendo el rendimiento del clúster durante la ejecución de la consulta. Puede utilizar esta información a la hora de diagnosticar el motivo por el que la consulta es lenta y lo que se puede hacer para mejorar su rendimiento.
Para ver los datos de desempeño
-
Inicie sesión en la AWS Management Console y abra la consola de Amazon Redshift en https://console.aws.amazon.com/redshiftv2/
. -
En el menú de navegación, elija Clusters (Clústeres) y, a continuación, elija el nombre de un clúster de la lista para abrir sus detalles. Se mostrarán los detalles del clúster, que pueden incluir las pestañas Cluster performance (Rendimiento del clúster), Query monitoring (Monitoreo de consultas), Databases (Bases de datos), Datashares (Recursos para compartir datos), Schedules (Programaciones), Maintenance (Mantenimiento) y Properties (Propiedades).
-
Elija la pestaña Cluster performance (Rendimiento del clúster) para ver la información del rendimiento, incluido:
-
Utilización de la CPU
-
Porcentaje de espacio del disco usado
-
Conexiones a base de datos
-
Estado
-
Query duration
-
Query throughput
-
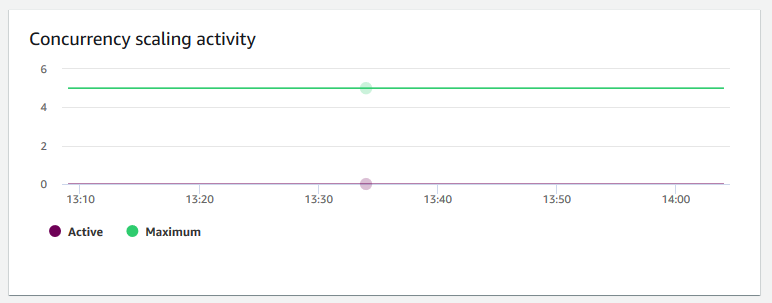
Actividad de escalado de simultaneidad
Hay muchas más métricas disponibles. Para ver las métricas disponibles y elegir cuáles se muestran, seleccione el icono Preferencias.
-
Gráficos de rendimiento del clúster
En los siguientes ejemplos se pueden observar algunos de los gráficos que se muestran en la nueva consola de Amazon Redshift.
-
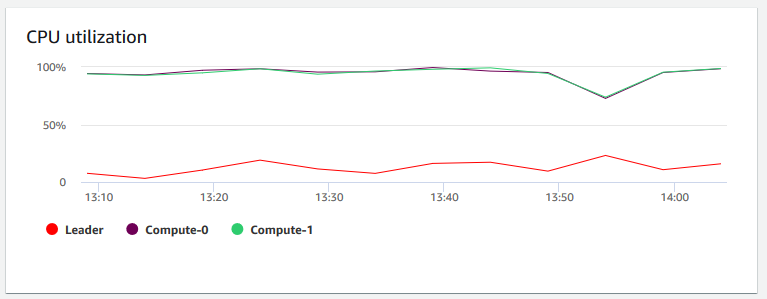
Utilización de la CPU: muestra el porcentaje de utilización de la CPU para todos los nodos (principales y de informática). Para encontrar un momento en el que el uso del clúster sea inferior antes de programar la migración del clúster u otras operaciones que consumen recursos, monitoree este gráfico para ver la utilización de la CPU en cada uno de los nodos o en todos ellos.
-
Modo de mantenimiento: muestra si el clúster está en el modo de mantenimiento en un momento elegido mediante los indicadores
OnyOff. Puede ver la hora en que el clúster está en proceso de mantenimiento. A continuación, puede correlacionar esta hora con las operaciones que se realizan en el clúster para estimar períodos de inactividad futuros para eventos recurrentes.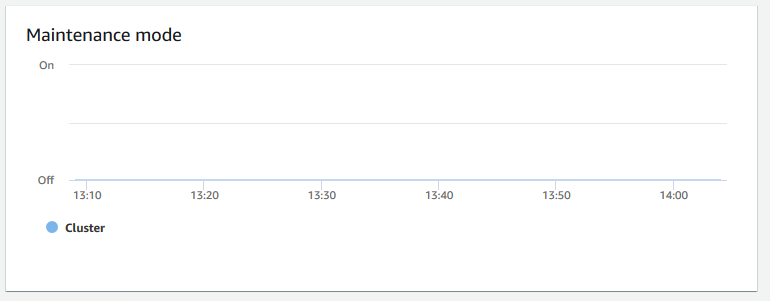
-
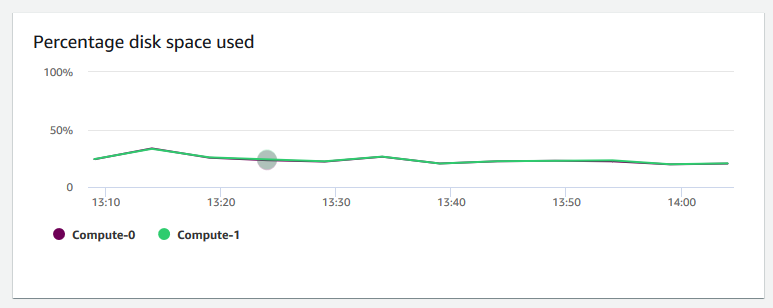
Porcentaje de espacio del disco usado: muestra el porcentaje de uso de espacio en disco por cada nodo informático, y no para el clúster como un todo. Puede explorar este gráfico para monitorear la utilización del disco. Las operaciones de mantenimiento como VACUUM y COPY utilizan espacio de almacenamiento temporal intermedio para sus operaciones de clasificación, por lo que se espera un aumento en el uso del disco.
-
Rendimiento de lectura: muestra el número promedio de megabytes leídos en el disco por segundo. Puede evaluar este gráfico para monitorear el aspecto físico correspondiente del clúster. Este rendimiento no incluye el tráfico de red entre las instancias del clúster y su volumen.
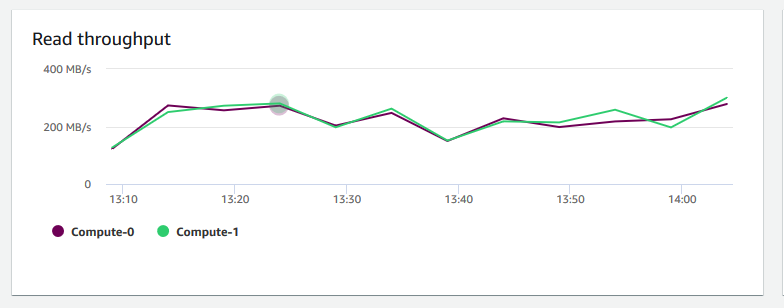
-
Latencia de lectura: muestra el tiempo promedio de cada operación de E/S de lectura en disco por milisegundo. Puede ver los tiempos de respuesta para que se devuelvan los datos. Cuando la latencia es alta, significa que el remitente pasa más tiempo inactivo (sin enviar paquetes nuevos), lo que reduce la rapidez con que crece el rendimiento.
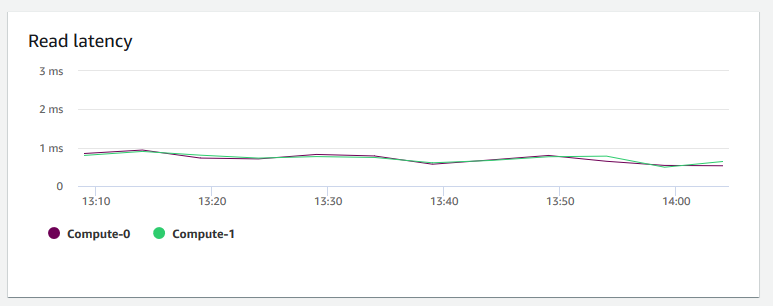
-
Rendimiento de escritura: muestra el número promedio de megabytes escritos en el disco por segundo. Puede evaluar esta métrica para monitorear el aspecto físico correspondiente del clúster. Este rendimiento no incluye el tráfico de red entre las instancias del clúster y su volumen.
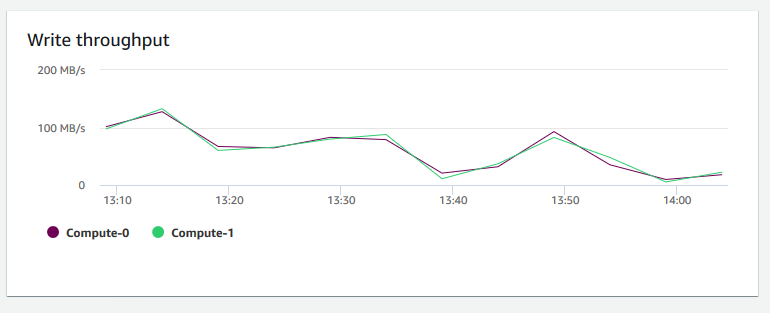
-
Latencia de escritura: muestra el tiempo promedio en milisegundos de cada operación de E/S de escritura en disco. Puede evaluar el tiempo para que se devuelva el reconocimiento de la escritura. Cuando la latencia es alta, significa que el remitente pasa más tiempo inactivo (sin enviar paquetes nuevos), lo que reduce la rapidez con que crece el rendimiento.
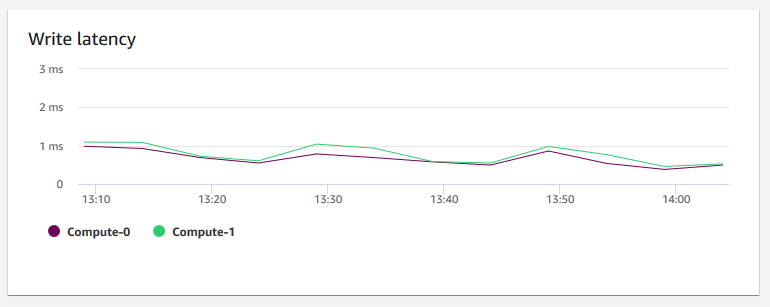
-
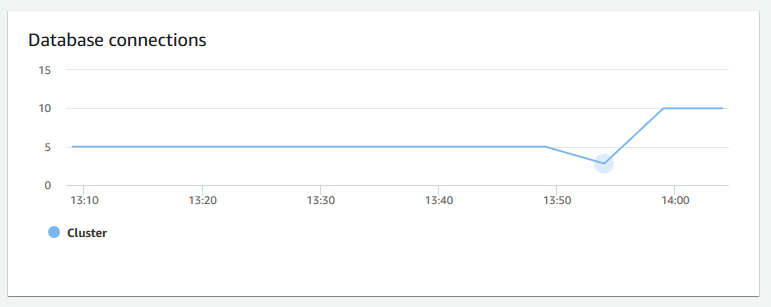
Conexiones de bases de datos: muestra el número de conexiones de bases de datos a un clúster. Puede utilizar este gráfico para ver cuántas conexiones se establecen a la base de datos y encontrar una hora en la que el uso del clúster es menor.
-
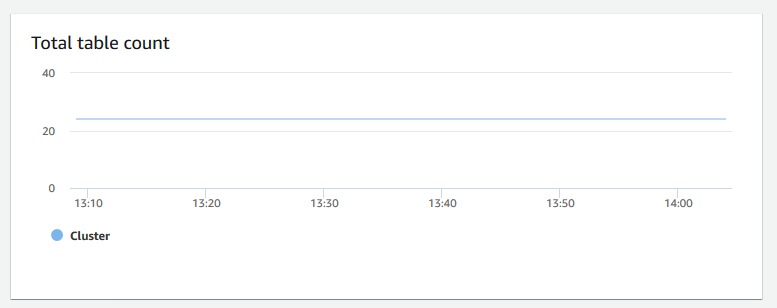
Recuento total de tablas: muestra el número de tablas de usuario abiertas en un momento determinado en un clúster. Puede monitorear el rendimiento del clúster cuando el recuento de tablas abiertas es alto.
-
Estado: indica si el estado del clúster es
HealthyoUnhealthy. Si el clúster puede conectarse a su base de datos y realiza correctamente una consulta sencilla, se considera que el clúster está en buen estado. De lo contrario, se considera que el clúster está en mal estado. Un estado incorrecto se puede producir cuando la base de datos del clúster está sobrecargada en exceso o cuando hay un problema de configuración con una base de datos del clúster.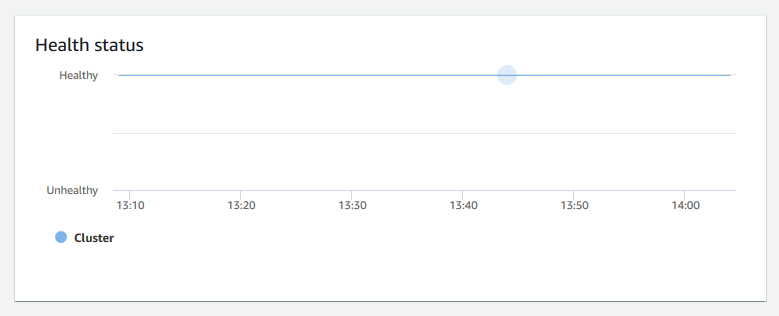
-
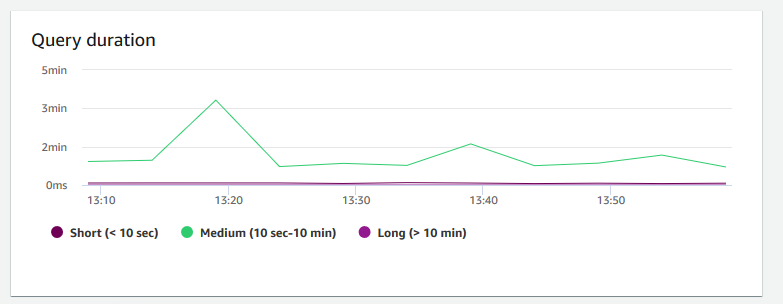
Duración de la consulta: muestra el tiempo promedio que tarda en completarse una consulta en microsegundos. Puede comparar los datos de este gráfico para medir el rendimiento de E/S dentro del clúster y ajustar sus consultas más largas si es necesario.
-
Rendimiento de la consulta: muestra el número promedio de consultas completadas por segundo. Puede analizar los datos de este gráfico para medir el rendimiento de la base de datos y caracterizar la capacidad del sistema para admitir una carga de trabajo multiusuario de manera equilibrada.
-
Duración de la consulta por cola de WLM: muestra el tiempo promedio que tarda en completarse una consulta en microsegundos. Puede comparar los datos de este gráfico para medir el rendimiento de E/S por cola de WLM y ajustar sus consultas más largas si es necesario.
-
Rendimiento de consulta por cola de WLM: muestra el número promedio de consultas completadas por segundo. Puede analizar los datos de este gráfico para medir el rendimiento de la base de datos por cola de WLM.
-
Actividad de escalado de simultaneidad: muestra el número de clústeres de escalado de simultaneidad activos. Cuando el escalado de simultaneidad está habilitado, Amazon Redshift agrega capacidad del clúster de manera automática si se necesita para procesar un aumento de las consultas de lectura simultáneas.