Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Detección de objetos y conceptos
Esta sección proporciona información para detectar etiquetas en imágenes y vídeos con Amazon Rekognition Image y Amazon Rekognition Video.
Una etiqueta o marca es un objeto o concepto (incluidos escenas y acciones) encontrado en una imagen o vídeo basado en su contenido. Por ejemplo, una imagen de personas en una playa tropical podría contener etiquetas como Palmera (objetos), Playa (escena), Correr (acción) y Exterior (concepto).
Para descargar la lista más reciente de etiquetas y cuadros delimitadores de objetos compatibles con Amazon Rekognition, haga clic aquí. Para descargar la lista anterior de etiquetas y cuadros delimitadores de objetos, haga clic aquí.
nota
Amazon Rekognition realiza predicciones binarias de género (hombre, mujer, niña, etc.) en función de la apariencia física de una persona en una imagen determinada. Este tipo de predicción no está diseñada para categorizar la identidad de género de una persona, y no debería usar Amazon Rekognition para tomar esa determinación. Por ejemplo, se podría predecir que un actor masculino que lleva una peluca de pelo largo y pendientes para un papel es una mujer.
El uso de Amazon Rekognition para realizar predicciones binarias de género es el más adecuado para los casos de uso en los que es necesario analizar las estadísticas agregadas de distribución de género sin identificar a usuarios específicos. Por ejemplo, el porcentaje de usuarios que son mujeres en comparación con los hombres en una plataforma de redes sociales.
No es recomendable utilizar predicciones binarias de género para tomar decisiones que podrían afectar a los derechos, la privacidad o el acceso de una persona a los servicios.
Amazon Rekognition devuelve las etiquetas en inglés. Puedes usar Amazon Translate
En el siguiente diagrama se muestra el orden de las operaciones de llamadas, en función de sus objetivos de uso de las operaciones de Amazon Rekognition Image o Amazon Rekognition Video:
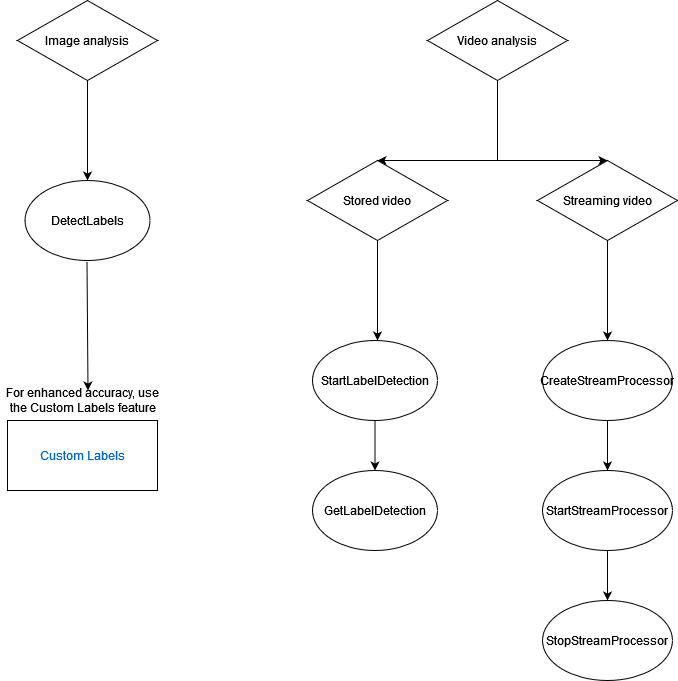
Etiquetado de objetos de respuesta
Cuadro delimitador
Amazon Rekognition Image y Amazon Rekognition Video pueden devolver el cuadro delimitador de etiquetas de objetos comunes, como personas, automóviles, muebles, prendas de vestir o mascotas. La información del cuadro delimitador no se devuelve en el caso de las etiquetas de objetos menos comunes. Puede utilizar los cuadros delimitadores para encontrar las ubicaciones exactas de objetos en una imagen, contar cuántas veces aparece el objeto detectado o medir el tamaño de un objeto mediante las dimensiones del cuadro delimitador.
Por ejemplo, en la imagen siguiente, Amazon Rekognition Image es capaz de detectar la presencia de una persona, un patinete, coches aparcados y otra información. Amazon Rekognition Image también devuelve el recuadro delimitador de una persona detectada y otros objetos detectados, como coches y ruedas.

Puntuación de confianza
Amazon Rekognition Video y Amazon Rekognition Image proporcionan además una puntuación de porcentaje sobre la confianza que tiene Amazon Rekognition en la precisión de cada etiqueta detectada.
Elementos principales
Amazon Rekognition Image y Amazon Rekognition Video utilizan una taxonomía jerárquica de etiquetas antecesoras para categorizar las etiquetas. Por ejemplo, una persona que está cruzando a pie la calle podría detectarse como Pedestrian (Peatón). La etiqueta principal de Pedestrian (Peatón) es Person (Persona). Ambas etiquetas se devuelven en la respuesta. Se devuelven todas las etiquetas antecesoras. Además, una etiqueta determinada contiene una lista de su etiqueta principal y demás etiquetas antecesoras. Por ejemplo, las etiquetas "abuelas" y "bisabuelas", si las hay. Puede utilizar etiquetas principales para crear grupos de etiquetas relacionadas y hacer posibles las consultas de etiquetas similares en una o varias imágenes. Por ejemplo, una consulta de todas las etiquetas Vehicle (Vehículo) podría devolver un automóvil de una imagen y una motocicleta de otra.
Categorías
Amazon Rekognition Image y Amazon Rekognition Video devuelven información en las categorías de etiquetas. Las etiquetas forman parte de categorías que agrupan etiquetas individuales en función de funciones y contextos comunes, como “Vehículos y automoción” y “Alimentos y bebidas”. Una categoría de etiquetas puede ser una subcategoría de una categoría principal.
Alias
Además de devolver las etiquetas, Amazon Rekognition Image y Amazon Rekognition Video devuelven cualquier alias asociado a la etiqueta. Los alias son etiquetas con el mismo significado o etiquetas que se pueden intercambiar visualmente con la etiqueta principal devuelta. Por ejemplo, “Móvil” es un alias de “Teléfono móvil”.
En versiones anteriores, Amazon Rekognition Image mostraba alias como “Móvil” en la misma lista de nombres de etiquetas principales que contenían “Teléfono móvil”. Amazon Rekognition Image ahora muestra “Móvil” en un campo denominado “alias” y “Teléfono móvil” en la lista de nombres de etiquetas principales. Si su aplicación se basa en las estructuras devueltas por una versión anterior de Rekognition, es posible que necesite transformar la respuesta actual devuelta por las operaciones de detección de etiquetas de imagen o vídeo en la estructura de respuesta anterior, en la que todas las etiquetas y alias se devuelven como etiquetas principales.
Si necesita transformar la respuesta actual de la DetectLabels API (para la detección de etiquetas en las imágenes) en la estructura de respuesta anterior, consulte el ejemplo de código en. Transformar la DetectLabels respuesta
Si necesita transformar la respuesta actual de la GetLabelDetection API (para la detección de etiquetas en los vídeos almacenados) en la estructura de respuesta anterior, consulte el ejemplo de código enTransformando la GetLabelDetection respuesta.
Propiedades de la imagen
Amazon Rekognition Image devuelve información sobre la calidad de la imagen (nitidez, brillo y contraste) de toda la imagen. La nitidez y el brillo también se devuelven para el primer plano y el fondo de la imagen. Las propiedades de la imagen también se pueden utilizar para detectar los colores dominantes de toda la imagen, el primer plano, el fondo y los objetos con cuadros delimitadores.

A continuación, se muestra un ejemplo de los ImageProperties datos contenidos en la respuesta de una DetectLabels operación para la imagen en curso:
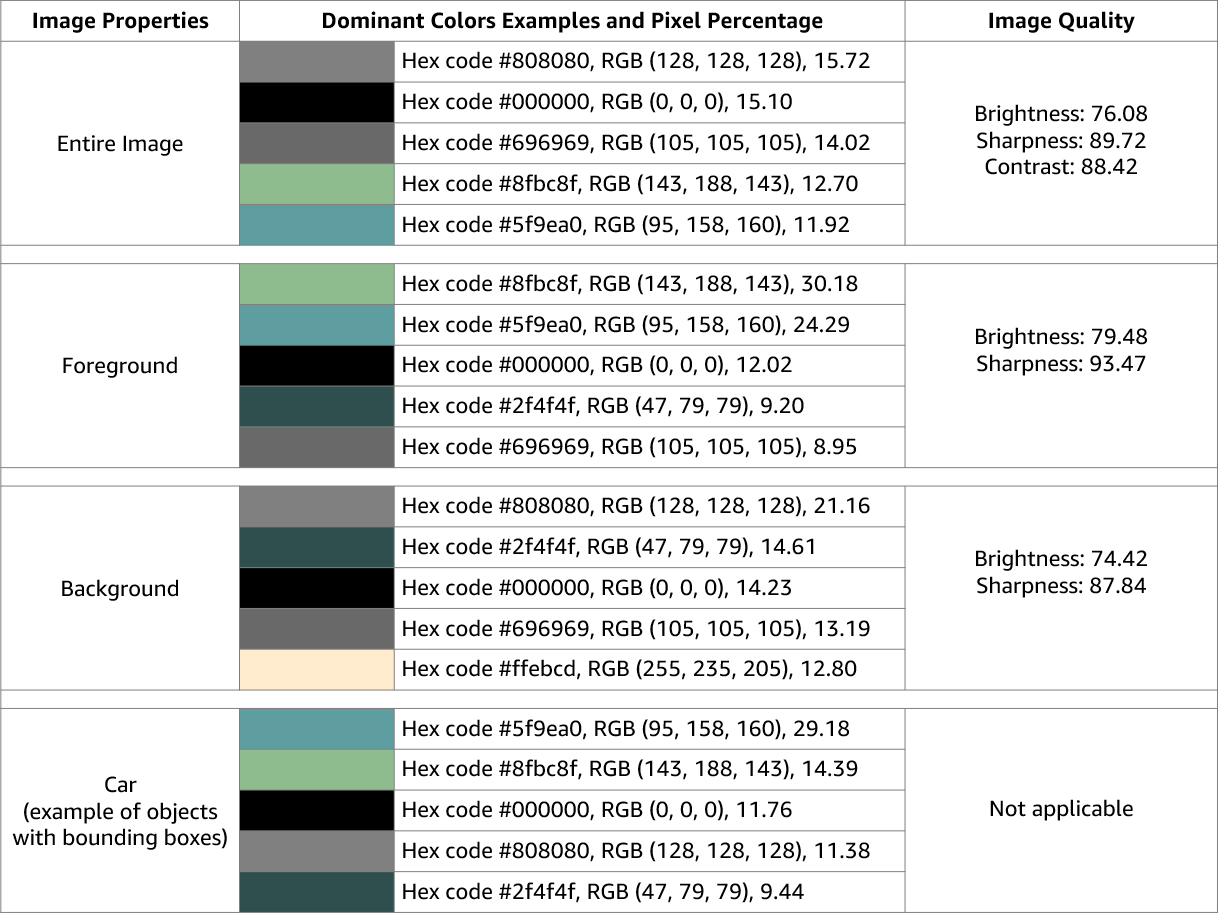
Las propiedades de imagen no están disponibles para Amazon Rekognition Video.
Versión del modelo
Amazon Rekognition Image y Amazon Rekognition Video devuelven la versión del modelo de detección de etiquetas que se ha utilizado para detectar etiquetas en una imagen o un vídeo almacenado.
Filtros de inclusión y exclusión
Puede filtrar los resultados devueltos por las operaciones de detección de etiquetas de Amazon Rekognition Image y Amazon Rekognition Video. Filtre los resultados proporcionando criterios de filtrado para las etiquetas y las categorías. Los filtros de etiquetas pueden ser inclusivos o exclusivos.
Consulte Detección de etiquetas en una imagen para obtener más información sobre el filtrado de los resultados obtenidos con DetectLabels.
Consulte Detección de etiquetas en un vídeo para obtener más información sobre el filtrado de los resultados obtenidos por GetLabelDetection.
Clasificación y agregación de los resultados
Los resultados obtenidos de determinadas operaciones de Amazon Rekognition Video se pueden ordenar y agregar según las marcas de tiempo y los segmentos de vídeo. Al recuperar los resultados de un trabajo de detección de etiquetas o moderación de contenido, con GetLabelDetection o GetContentModeration respectivamente, puede utilizar los argumentos SortBy y AggregateBy para especificar cómo desea que se devuelvan los resultados. Puede usar SortBy con TIMESTAMP o NAME (nombres de etiqueta) y usar TIMESTAMPS o SEGMENTS con el AggregateBy argumento.
