Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Uso de un modelo de idioma personalizado
Una vez que haya creado su modelo de idioma personalizado, puede incluirlo en sus solicitudes de transcripción; consulte las siguientes secciones para ver ejemplos.
El idioma del modelo que incluya en la solicitud debe coincidir con el código de idioma que especifique para el contenido multimedia. Si los idiomas no coinciden, su modelo de idioma personalizado no se aplicará a la transcripción y no habrá advertencias ni errores.
Uso de un modelo de idioma personalizado en una transcripción por lotes
Para usar un modelo de idioma personalizado con una transcripción por lotes, consulte los siguientes ejemplos:
-
Inicie sesión en la AWS Management Console
. -
En el panel de navegación, elija Trabajos de transcripción y, a continuación, seleccione Crear trabajo (arriba a la derecha). Se abrirá la página Especificar los detalles del trabajo.
-
En el panel de Configuración del trabajo, en Tipo de modelo, seleccione la casilla Modelo de idioma personalizado.
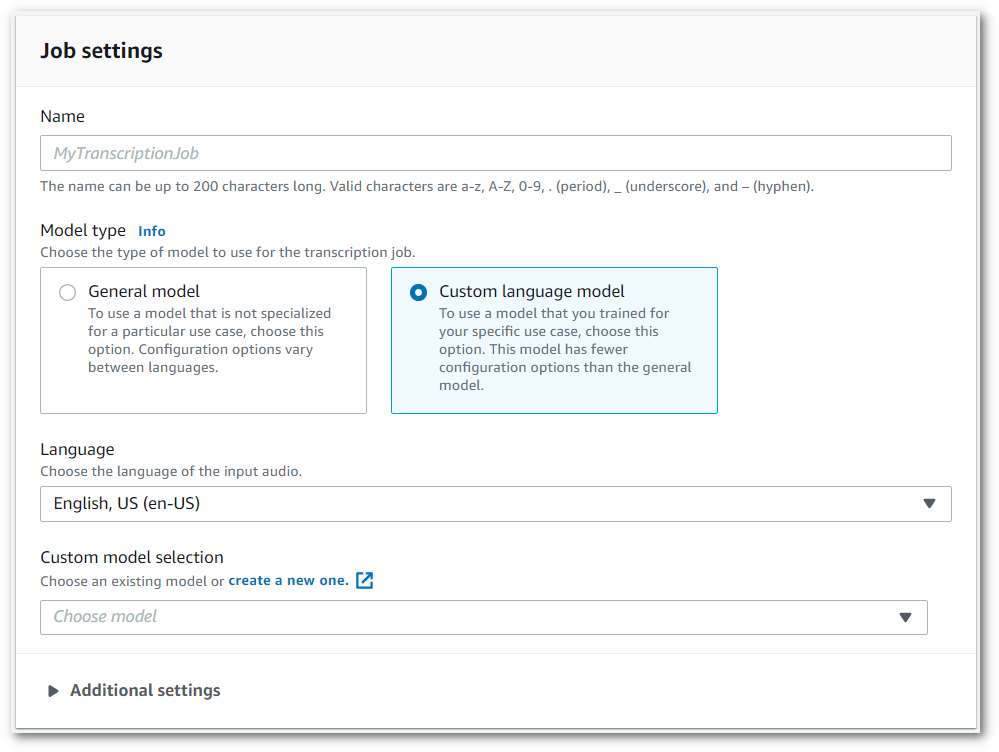
También debe seleccionar un idioma de entrada en el menú desplegable.
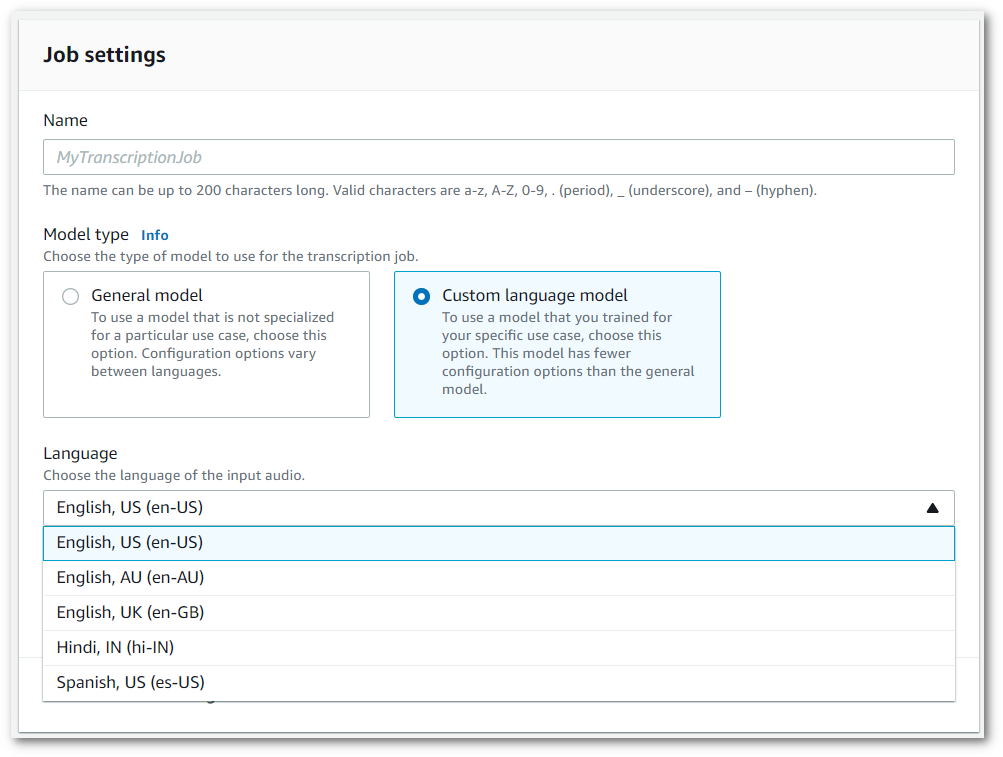
-
En Selección de modelos personalizados, seleccione un modelo de idioma personalizado existente en el menú desplegable o en Crear uno nuevo.
Añade la Amazon S3 ubicación del archivo de entrada en el panel de datos de entrada.
-
Seleccione Siguiente para obtener opciones de configuración adicionales.
Seleccione Crear trabajo para ejecutar su trabajo de transcripción.
En este ejemplo, se utilizan el start-transcription-jobModelSettings parámetro con el VocabularyName subparámetro. Para obtener más información, consulte StartTranscriptionJob y ModelSettings.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/ \ --language-codeen-US\ --model-settings LanguageModelName=my-first-language-model
Este es otro ejemplo en el que se usa el start-transcription-job
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-json file://my-first-model-job.json
El archivo my-first-model-job.json contiene el siguiente cuerpo de solicitud.
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" }, "OutputBucketName": "amzn-s3-demo-bucket", "OutputKey": "my-output-files/", "LanguageCode": "en-US", "ModelSettings": { "LanguageModelName": "my-first-language-model" } }
En este ejemplo, se utiliza AWS SDK para Python (Boto3) para incluir un modelo de lenguaje personalizado mediante el ModelSettings argumento del método start_transcription_jobStartTranscriptionJob y ModelSettings.
Para ver más ejemplos en los que se utiliza el escenario y los servicios cruzados AWS SDKs, incluidos ejemplos de funciones específicas, consulte el capítulo. Ejemplos de código para Amazon Transcribe usando AWS SDKs
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') job_name = "my-first-transcription-job" job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'amzn-s3-demo-bucket', OutputKey = 'my-output-files/', LanguageCode = 'en-US', ModelSettings = { 'LanguageModelName': 'my-first-language-model' } ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
Uso de un modelo de idioma personalizado en una transcripción de streaming
Para usar un modelo de idioma personalizado con una transcripción por lotes, consulte los siguientes ejemplos:
-
Inicie sesión en el AWS Management Console
. -
En el panel de navegación, elija Transcripción en tiempo real. Desplácese hacia abajo hasta Personalizaciones y expanda este campo si está minimizado.
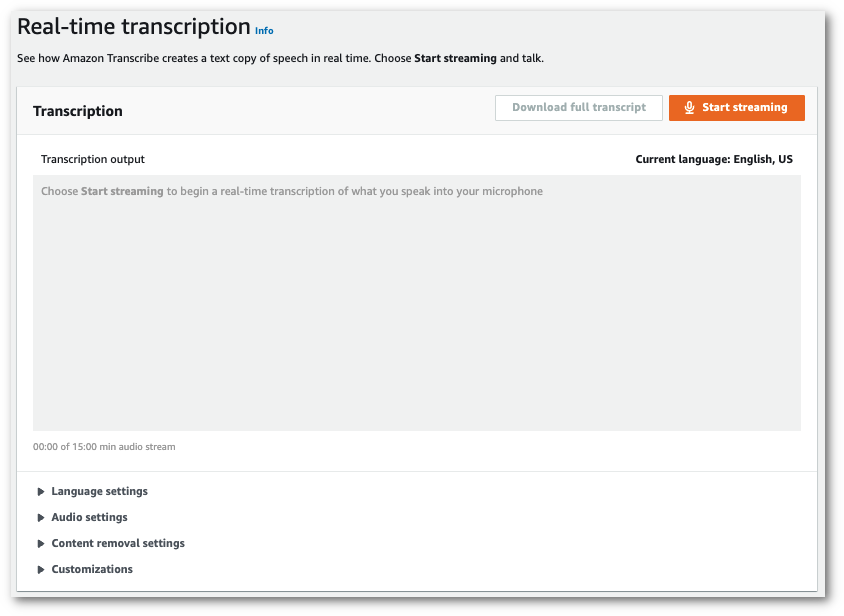
-
Active Modelo de idioma personalizado y seleccione un modelo en el menú desplegable.
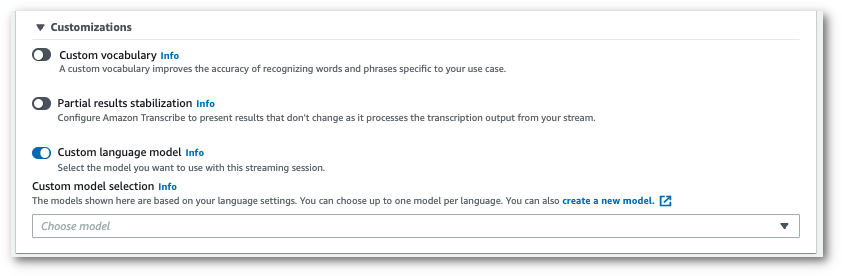
Incluya cualquier otra configuración que desee aplicar a la secuencia.
-
Ahora tiene todo preparado para transcribir la secuencia. Seleccione Comenzar streaming y comience a hablar. Para finalizar el dictado, seleccione Detener streaming.
En este ejemplo, se crea una solicitud HTTP/2 que incluye su modelo de idioma personalizado. Para obtener más información sobre el uso de la transmisión HTTP/2 con Amazon Transcribe, consulte. Configuración de una secuencia HTTP/2 Para obtener más información sobre los parámetros y encabezados específicos de Amazon Transcribe, consulte. StartStreamTranscription
POST /stream-transcription HTTP/2 host: transcribestreaming.us-west-2.amazonaws.com X-Amz-Target: com.amazonaws.transcribe.Transcribe.StartStreamTranscriptionContent-Type: application/vnd.amazon.eventstream X-Amz-Content-Sha256:stringX-Amz-Date:20220208T235959Z Authorization: AWS4-HMAC-SHA256 Credential=access-key/20220208/us-west-2/transcribe/aws4_request, SignedHeaders=content-type;host;x-amz-content-sha256;x-amz-date;x-amz-target;x-amz-security-token, Signature=stringx-amzn-transcribe-language-code:en-USx-amzn-transcribe-media-encoding:flacx-amzn-transcribe-sample-rate:16000x-amzn-transcribe-language-model-name:my-first-language-modeltransfer-encoding: chunked
Las definiciones de los parámetros se encuentran en la referencia de la API; los parámetros comunes a todas las operaciones de la AWS API se enumeran en la sección Parámetros comunes.
En este ejemplo, se crea una URL prefirmada que aplica tu modelo de idioma personalizado a una WebSocket transmisión. Se han añadido saltos de línea para facilitar la lectura. Para obtener más información sobre el uso de WebSocket transmisiones con Amazon Transcribe, consulteConfigurar una WebSocket transmisión. Para obtener más información sobre parámetros, consulte StartStreamTranscription.
GET wss://transcribestreaming.us-west-2.amazonaws.com:8443/stream-transcription-websocket? &X-Amz-Algorithm=AWS4-HMAC-SHA256 &X-Amz-Credential=AKIAIOSFODNN7EXAMPLE%2F20220208%2Fus-west-2%2Ftranscribe%2Faws4_request &X-Amz-Date=20220208T235959Z &X-Amz-Expires=300&X-Amz-Security-Token=security-token&X-Amz-Signature=string&X-Amz-SignedHeaders=content-type%3Bhost%3Bx-amz-date &language-code=en-US&media-encoding=flac&sample-rate=16000&language-model-name=my-first-language-model
Las definiciones de los parámetros se encuentran en la referencia de la API; los parámetros comunes a todas las operaciones de la AWS API se enumeran en la sección Parámetros comunes.
