REL10-BP03 Uso de arquitecturas herméticas para limitar el alcance del impacto
La implementación de arquitecturas herméticas (también conocidas como arquitecturas basadas en celdas) restringe el efecto del fallo dentro de una carga de trabajo a un número limitado de componentes.
Resultado deseado: una arquitectura basada en celdas utiliza varias instancias aisladas de una carga de trabajo, donde cada instancia se conoce como celda. Cada celda es independiente, no comparte estado con otras celdas y gestiona un subconjunto de las solicitudes de la carga de trabajo global. Esto reduce la posible repercusión de un error, como una actualización de software incorrecta, en una celda individual y en las solicitudes que está procesando. Si una carga de trabajo utiliza 10 celdas para atender 100 solicitudes cuando se produce un error, el 90 % del total de las solicitudes no se verá afectado por el error.
Patrones comunes de uso no recomendados:
-
Permitir que las celdas crezcan sin límites.
-
Aplicar actualizaciones o implementaciones de código a todas las celdas al mismo tiempo.
-
Compartir estado o componentes entre celdas (a excepción de la capa de enrutador).
-
Agregar lógica compleja de negocio o de enrutamiento a la capa de enrutador.
-
No minimizar las interacciones entre celdas.
Beneficios de establecer esta práctica recomendada: con las arquitecturas basadas en celdas, muchos tipos de fallos comunes se encuentran dentro de la propia celda, lo que proporciona un aislamiento adicional de los fallos. Estos límites de los errores pueden favorecer la resiliencia frente a tipos de errores que, de otro modo, serían difíciles de contener, como implementaciones de código fallidas o solicitudes dañadas o que invocan un modo de error específico (también conocidas como solicitudes de píldora venenosa).
Nivel de riesgo expuesto si no se establece esta práctica recomendada: alto
Guía para la implementación
En un barco, los mamparos garantizan que una brecha en el casco quede contenida en una sola sección del casco. En los sistemas complejos, este modelo de contención suele imitarse para permitir el aislamiento de errores. Los límites aislados de los errores restringen el efecto de un error en una carga de trabajo a un número limitado de componentes. Los componentes que se encuentran fuera del límite no se ven afectados por el error. Al usar múltiples límites aislados de errores, puede limitar el impacto en su carga de trabajo. En AWS, los clientes pueden utilizar varias zonas y regiones de disponibilidad para proporcionar aislamiento de errores, pero el concepto de aislamiento de errores también puede extenderse a la arquitectura de su carga de trabajo.
La carga de trabajo global se divide en celdas mediante una clave de partición. Esta clave tiene que alinearse con la corriente del servicio o con la forma natural en que la carga de trabajo de un servicio puede subdividirse con mínimas interacciones entre celdas. Algunos ejemplos de claves de partición son el ID de cliente, el ID de recurso o cualquier otro parámetro fácilmente accesible en la mayoría de las llamadas a la API. Una capa de enrutador de celdas distribuye las solicitudes a celdas individuales en función de la clave de partición y presenta un único punto de conexión a los clientes.
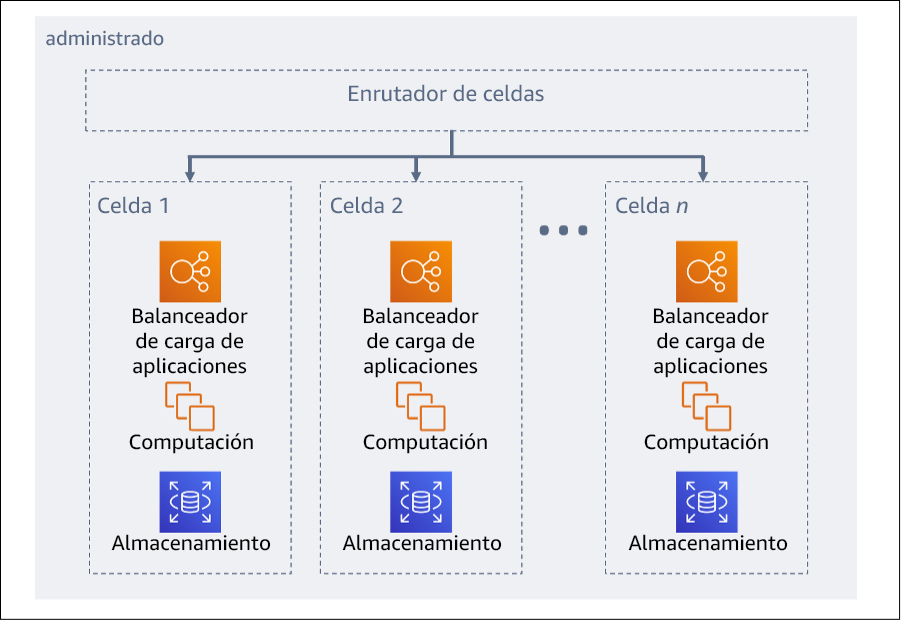
Figura 11: Arquitectura basada en celdas
Pasos para la implementación
Al diseñar una arquitectura basada en celdas, hay que tener en cuenta varias consideraciones de diseño:
-
Clave de partición: se debe tener especial cuidado al elegir la clave de partición.
-
Debe alinearse con la corriente del servicio o con la forma natural en que la carga de trabajo de un servicio puede subdividirse con mínimas interacciones entre celdas. Algunos ejemplos son
customer IDoresource ID. -
La clave de partición debe estar disponible en todas las solicitudes, ya sea de modo directo o de una manera que se pueda inferir con facilidad de forma determinista por otros parámetros.
-
-
Asignación persistente de celdas: los servicios ascendentes solo deberían interactuar con una única celda durante el ciclo de vida de sus recursos.
-
Según la carga de trabajo, puede ser necesaria una estrategia de migración de celda para migrar datos de una celda a otra. Un posible escenario en el que puede ser precisa una migración de celda es si un usuario o recurso concreto de la carga de trabajo crece demasiado y requiere una celda dedicada.
-
Las celdas no deben compartir estados ni componentes entre ellas.
-
En consecuencia, las interacciones entre celdas deben evitarse o mantenerse al mínimo, ya que dichas interacciones crean dependencias entre las celdas y, por lo tanto, disminuyen las ventajas en el aislamiento de errores.
-
-
Capa de enrutador: la capa de enrutador es un componente compartido entre las celdas y, por lo tanto, no puede seguir la misma estrategia de compartimentación que las celdas.
-
Se recomienda que la capa de enrutador distribuya las solicitudes a las celdas individuales mediante un algoritmo de asignación de particiones de una manera eficiente a nivel computacional, como la combinación de funciones hash criptográficas y aritmética modular para asignar claves de partición a las celdas.
-
Para evitar impactos multicelda, la capa de enrutador debe ser lo más simple y escalable horizontalmente posible, lo que requiere evitar una lógica de negocio compleja dentro de esta capa. Esto tiene la ventaja agregada de facilitar la comprensión de su comportamiento esperado en todo momento, lo que permite una comprobabilidad exhaustiva. Como explica Colm MacCárthaigh en Reliability, constant work, and a good cup of coffee
, los diseños simples y los patrones de trabajo constantes producen sistemas fiables y reducen la antifragilidad.
-
-
Tamaño de la celda: las celdas deben tener un tamaño máximo y no debe permitirse que lo superen.
-
Para determinar el tamaño máximo, se deben llevar a cabo pruebas exhaustivas hasta que se alcancen puntos de ruptura y se establezcan márgenes de funcionamiento seguros. Para obtener más detalles sobre cómo implementar prácticas de prueba, consulte REL07-BP04 Pruebas en su carga de trabajo
-
La carga de trabajo global crecerá a medida que se agreguen celdas adicionales, lo que permite escalar la carga de trabajo con los aumentos de la demanda.
-
-
Estrategias de varias zonas de disponibilidad o de varias regiones: se deben aprovechar las diversas capas de resiliencia para protegerse contra diferentes dominios de error.
-
Para obtener resiliencia, debe utilizar un enfoque que cree capas de defensa. Una capa protege de las interrupciones más pequeñas y frecuentes mediante la creación de una arquitectura de alta disponibilidad con múltiples AZ. Otra capa de defensa está pensada para proteger de eventos poco frecuentes, como las catástrofes naturales generalizadas y las interrupciones a nivel regional. Esta segunda capa implica la arquitectura de su aplicación para que abarque múltiples Regiones de AWS. Implementar una estrategia multirregión para la carga de trabajo ayuda a protegerla de catástrofes naturales generalizadas que afecten a una región geográfica amplia de un país o de errores técnicos de alcance regional. Tenga en cuenta que implementar una arquitectura multirregional puede ser significativamente complejo y no suele ser necesario para la mayoría de las cargas de trabajo. Para obtener más información, consulte REL10-BP01 Implementación de la carga de trabajo en varias ubicaciones.
-
-
Implementación de código: debería preferirse una estrategia de implementación de código escalonada en lugar de implementar cambios de código en todas las celdas al mismo tiempo.
-
Esto ayuda a minimizar posibles errores en numerosas celdas provocados por una implementación incorrecta o a un error humano. Para obtener más detalles, consulte Automatización de implementaciones seguras y sin intervención
.
-
Recursos
Prácticas recomendadas relacionadas:
Documentos relacionados:
Videos relacionados:
-
AWS re:Invent 2018: Close Loops and Opening Minds: How to Take Control of Systems, Big and Small
-
AWS re:Invent 2018: How AWS Minimizes the Blast Radius of Failures (ARC338)
-
Shuffle-sharding: AWS re:Invent 2019: Introducing The Amazon Builders’ Library (DOP328)
-
AWS Summit ANZ 2021 - Everything fails, all the time: Designing for resilience
