Modelo de responsabilidad compartida para la resiliencia
La resiliencia es una responsabilidad compartida entre AWS y el cliente. Es importante que entienda cómo la recuperación de desastres (DR) y la disponibilidad, como parte de la resiliencia, operan bajo este modelo compartido.
Responsabilidad de AWS: resiliencia de la nube
AWS es responsable de la resiliencia de la infraestructura en la que se ejecutan todos los servicios que se ofrecen en la Nube de AWS. Esta infraestructura está conformada por el hardware, el software, las redes y las instalaciones que ejecutan servicios de la Nube de AWS. AWS hace todos los esfuerzos razonables desde el punto de vista comercial para que estos servicios de la Nube de AWS estén disponibles, lo que garantiza que la disponibilidad del servicio cumpla o supere los acuerdos de nivel de servicio (SLA) de AWS
La infraestructura en la nube global de AWS
Responsabilidad del cliente: resiliencia en la nube
Su responsabilidad vendrá determinada por los servicios de Nube de AWS que elija. Esto determina la cantidad de trabajo de configuración que debe llevar a cabo como parte de sus responsabilidades de resiliencia. Por ejemplo, un servicio como Amazon Elastic Compute Cloud (Amazon EC2) exige que el cliente lleve a cabo todas las tareas necesarias de configuración y administración de la resiliencia. Los clientes que implementan instancias de Amazon EC2 son responsables de implementar las instancias de Amazon EC2 en varias ubicaciones (como las zonas de disponibilidad de AWS), implementar la autorreparación mediante servicios como el escalado automático y utilizar las prácticas recomendadas de arquitectura de carga de trabajo resiliente para las aplicaciones instaladas en las instancias. En el caso de los servicios administrados, como Amazon S3 y Amazon DynamoDB, AWS se encarga de gestionar la capa de infraestructura, el sistema operativo y las plataformas, mientras que los clientes acceden a los puntos de conexión para guardar y recuperar información. El cliente es responsable de administrar la resiliencia de sus datos, incluidas las estrategias de copia de seguridad, control de versiones y replicación.
La implementación de la carga de trabajo en varias zonas de disponibilidad de una Región de AWS forma parte de una estrategia de alta disponibilidad diseñada para proteger las cargas de trabajo al aislar los problemas en una zona de disponibilidad, que utiliza la redundancia de las demás zonas de disponibilidad para seguir atendiendo las solicitudes. Una arquitectura de varias zonas de disponibilidad también forma parte de una estrategia de DR diseñada para que las cargas de trabajo estén mejor aisladas y protegidas de problemas como interrupciones de alimentación eléctrica, tormentas eléctricas, tornados, terremotos, etc. Las estrategias de DR también pueden hacer uso de varias Regiones de AWS. Por ejemplo, en una configuración activa-pasiva, el servicio para la carga de trabajo pasa de su región activa a su región de DR si la región activa ya no puede atender solicitudes.
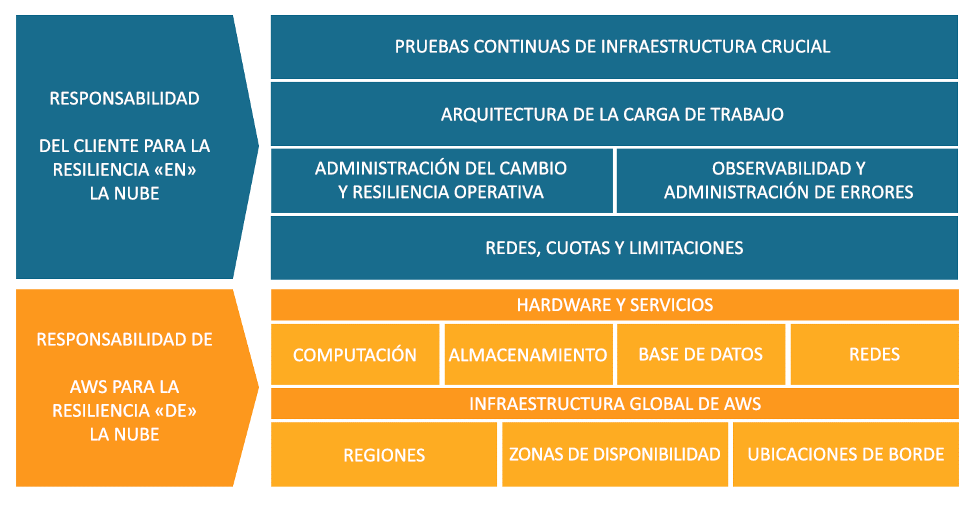
Responsabilidad de los clientes y AWS en cuanto a la resiliencia dentro y fuera de la nube.
Puede utilizar los servicios de AWS para lograr sus objetivos de resiliencia. Como cliente, es responsable de la administración de los siguientes aspectos de su sistema para lograr la resiliencia en la nube. Para obtener más información sobre cada servicio en particular, consulte la documentación de AWS.
Redes, cuotas y limitaciones
-
Las prácticas recomendadas para esta área del modelo de responsabilidad compartida se describen en detalle en Principios básicos.
-
Planifique su arquitectura con el espacio suficiente para escalarla y comprenda las cuotas de servicio y las limitaciones de los servicios que incluya, en función de los aumentos de carga esperados en las solicitudes, cuando proceda.
-
Diseñe la topología de red para que sea de alta disponibilidad, redundante y escalable.
Administración de cambios y resiliencia operativa
-
Administración de cambios incluye cómo introducir y administrar los cambios en su entorno. La implementación de cambios requiere crear y mantener actualizados los manuales de procedimientos y estrategias de implementación para su aplicación e infraestructura.
-
Una estrategia flexible para supervisar los recursos de la carga de trabajo considera todos los componentes, incluidas las métricas técnicas y empresariales, las notificaciones, la automatización y el análisis.
-
Las cargas de trabajo en la nube deben adaptarse a los cambios en la demanda al reducir horizontalmente en respuesta a las deficiencias o fluctuaciones del uso.
Observabilidad y administración de errores
-
Es necesario observar los fallos mediante la supervisión para automatizar la reparación, de modo que sus cargas de trabajo puedan soportar los fallos de los componentes.
-
La administración de errores requiere hacer copias de seguridad de los datos, aplicar las prácticas recomendadas para permitir que la carga de trabajo resista los fallos de los componentes y planificar la recuperación de desastres.
Arquitectura de la carga de trabajo
-
La arquitectura de la carga de trabajo incluye la forma de diseñar los servicios en torno a los dominios empresariales, aplicar el diseño de sistemas distribuidos y de SOA para evitar fallos e incorporar capacidades como la limitación, los reintentos, la gestión de colas, los tiempos de espera y las palancas de emergencia.
-
Confíe en las soluciones de AWS
probadas, la Amazon Builders' Library y los patrones sin servidor para alinearse con las prácticas recomendadas y poner en marcha las implementaciones. -
Utilice la mejora continua para descomponer su sistema en servicios distribuidos para escalar e innovar con más rapidez. Utilice la orientación sobre microservicios de AWS
y las opciones de servicios administrados para simplificar y acelerar su capacidad de introducir cambios e innovar.
Pruebas continuas de infraestructura crucial
-
Prueba de fiabilidad implica hacer pruebas a nivel funcional, de rendimiento y de caos, así como adoptar prácticas de análisis de incidentes y prácticas propias del día de juego para adquirir experiencia en la resolución de problemas que no se comprenden bien.
-
Tanto para las aplicaciones en la nube como para las híbridas, saber cómo se comporta su aplicación cuando surgen problemas o se caen los componentes le permite recuperarse de las interrupciones de forma rápida y fiable.
-
Cree y documente experimentos repetibles para comprender cómo se comporta su sistema cuando las cosas no funcionan como se esperaba. Estas pruebas demostrarán la eficacia de su capacidad de recuperación general y proporcionarán un bucle de retroalimentación para sus procedimientos operativos antes de enfrentarse a escenarios de error reales.
