Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Disponibilidad con redundancia
Cuando una carga de trabajo utiliza subsistemas múltiples, independientes y redundantes, puede alcanzar un mayor nivel teórico de disponibilidad que si se utilizara un único subsistema. Piense en una carga de trabajo compuesta de dos subsistemas idénticos. Puede estar completamente operativa si el subsistema uno o el subsistema dos están operativos. Para que todo el sistema esté inactivo, ambos subsistemas deben estar inactivos al mismo tiempo.
Si la probabilidad de error de un subsistema es 1 − α, entonces la probabilidad de que dos subsistemas redundantes estén inactivos al mismo tiempo es el producto de la probabilidad de que falle cada subsistema, F = (1 − α1) × (1 − α2). Para una carga de trabajo con dos subsistemas redundantes, si se utiliza la ecuación (3), se obtiene una disponibilidad definida de la siguiente manera:
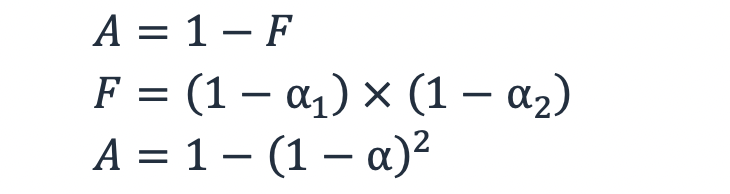
Ecuación 5
Por lo tanto, para dos subsistemas cuya disponibilidad es del 99 %, la probabilidad de que uno falle es del 1 % y la probabilidad de que ambos fallen es (1 − 99 %) × (1 − 99 %) = 0,01 %. Así, la disponibilidad al usar dos subsistemas redundantes es del 99,99 %.
Esto se puede generalizar para incorporar otros componentes redundantes de repuesto, r. En la ecuación (5), solo asumimos un repuesto, pero una carga de trabajo puede tener dos, tres o más repuestos para poder sobrevivir a la pérdida simultánea de varios subsistemas sin afectar a la disponibilidad. Si una carga de trabajo tiene tres subsistemas y dos son de repuesto, la probabilidad de que los tres subsistemas fallen al mismo tiempo es (1 − α) × (1 − α) × (1 − α) o (1 − α)3. En general, una carga de trabajo con r repuestos solo fallará si fallan los subsistemas s + 1.
Para una carga de trabajo con n subsistemas y r repuestos, f es el número de modos de error o las formas en que los subsistemas r + 1 pueden fallar a partir de n.
En efecto, este es el teorema binomial, la matemática combinatoria de elegir k elementos de un conjunto de n, o “n elige k”. En este caso, k es r+ 1.
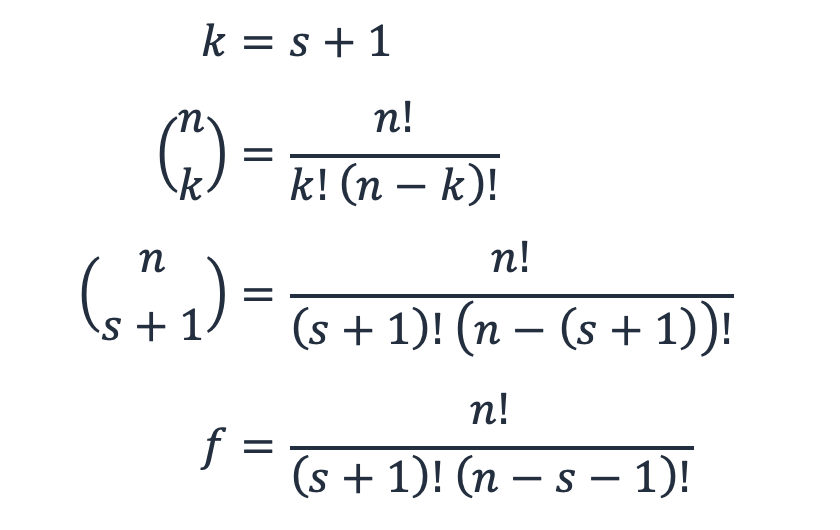
Ecuación 6
Luego, podemos producir una aproximación generalizada de disponibilidad que incorpore el número de modos de error y los repuestos. (Para entender por qué hablamos de una aproximación, consulte el apéndice 2 de Highleyman, et al., “Breaking the Availability Barrier
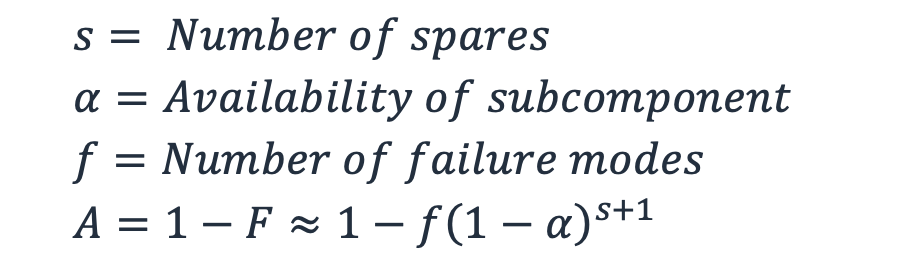
Ecuación 7
La incorporación de repuestos se puede aplicar a cualquier dependencia que proporcione recursos que fallen de forma independiente. Entre los ejemplos se incluyen instancias de Amazon EC2 en diferentes zonas de disponibilidad (AZ) o buckets de Amazon S3 en diferentes Regiones de AWS. El uso de repuestos ayuda a esa dependencia a lograr una mayor disponibilidad total para cumplir con los objetivos de disponibilidad de la carga de trabajo.
Regla 5
Utilice repuestos para incrementar la disponibilidad de las dependencias en una carga de trabajo.
Sin embargo, el uso de repuestos conlleva un costo. Cada repuesto adicional cuesta lo mismo que el módulo original, lo que incrementa el gasto de manera lineal. Crear una carga de trabajo que pueda utilizar componentes de repuesto también aumenta su complejidad. Debe saber cómo identificar los errores de dependencias, trasladar el trabajo a un recurso en buen estado y gestionar la capacidad general de la carga de trabajo.
La redundancia supone un problema de optimización. Si hay pocos repuestos, la carga de trabajo puede fallar con más frecuencia de la deseada; si hay demasiados, la carga de trabajo cuesta demasiado. Existe un umbral en el que añadir más repuestos costará más de lo que justifica la disponibilidad adicional que ofrecen.
Si utilizamos nuestra fórmula de disponibilidad general con repuestos, la ecuación (7), para un subsistema que tiene una disponibilidad del 99,5 %, con dos repuestos, la disponibilidad de la carga de trabajo es D ≈ 1 − (1)(1 − 0,995)3 = 99,9999875 % (aproximadamente 3,94 segundos de inactividad al año); con 10 repuestos obtenemos D ≈ 1 − (1)(1 − 0,995)11 = 99,99999999999999999999999 (el tiempo de inactividad aproximado sería 1,26252 × 10−15ms al año, prácticamente 0). Al comparar estas dos cargas de trabajo, hemos incurrido en un aumento de 5 veces en el costo de los repuestos para lograr cuatro segundos menos de tiempo de inactividad al año. Para la mayoría de las cargas de trabajo, el aumento del costo no estaría justificado para este aumento de la disponibilidad. La relación se muestra en la siguiente figura.
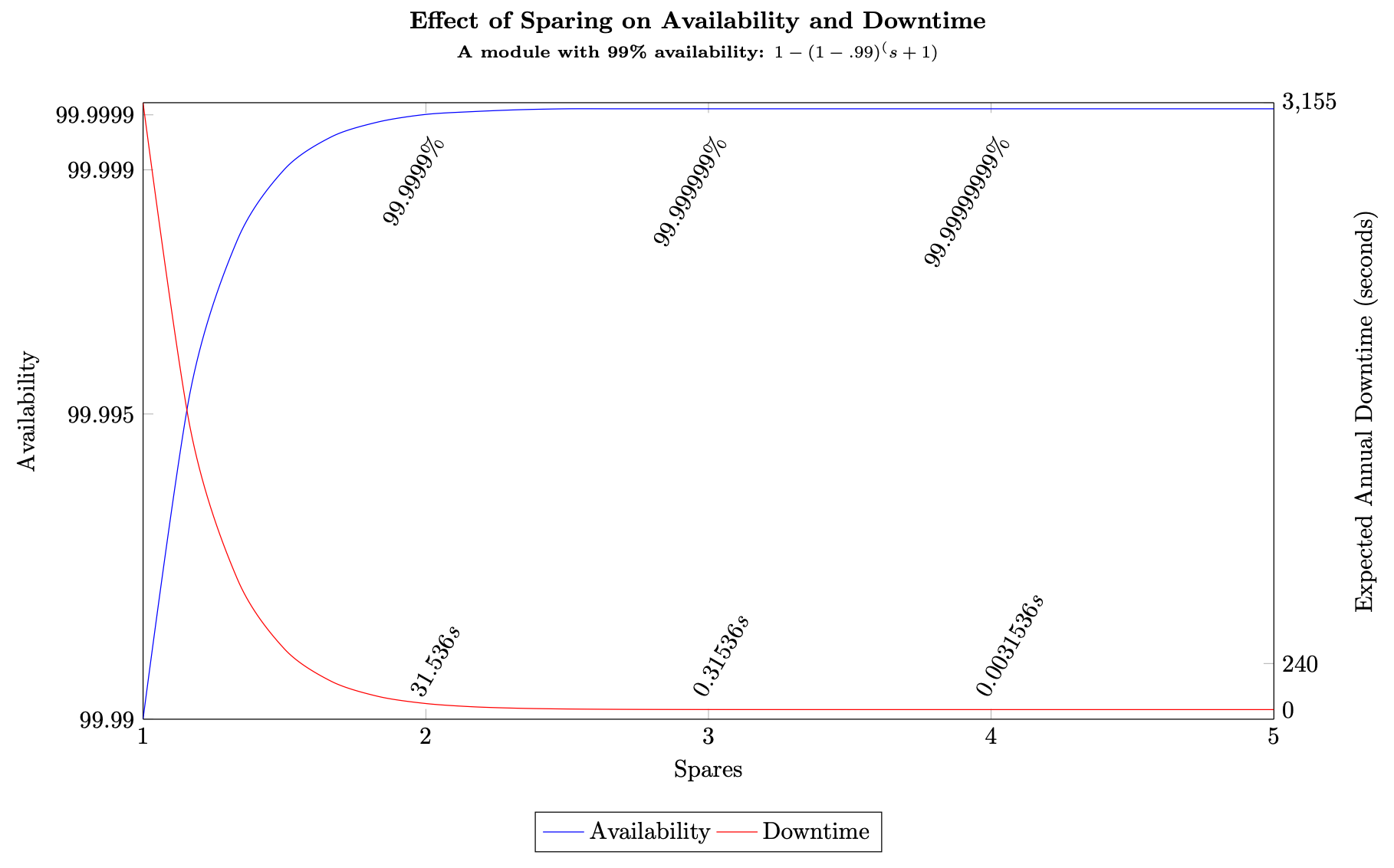
Rendimientos decrecientes derivados del aumento de repuestos
Con tres repuestos o más, el resultado son fracciones de segundo del tiempo de inactividad previsto al año, lo que significa que, a partir de esa cantidad, se llega a la zona de rentabilidad decreciente. Puede que surja la necesidad de añadir más capacidad para lograr niveles más altos de disponibilidad, pero en realidad, la rentabilidad desaparece muy rápidamente. El uso de más de tres repuestos no proporciona ganancias materiales ni notables para casi ninguna carga de trabajo cuando el propio subsistema en sí tiene una disponibilidad de al menos el 99 %.
Regla 6
La rentabilidad del uso de repuestos tiene un límite superior. Utilice el menor número de repuestos necesario para lograr la disponibilidad requerida.
Debe tener en cuenta la unidad de error al seleccionar el número correcto de repuestos. Tomemos como ejemplo una carga de trabajo que requiere 10 instancias de EC2 para gestionar los picos de capacidad, implementadas en una sola AZ.
Dado que las AZ se han diseñado para funcionar como límites de aislamiento de errores, la unidad de error no es solo una instancia de EC2, sino que todas las instancias de EC2 de una AZ pueden fallar al mismo tiempo. En este caso, querrá añadir redundancia con otra AZ e implementar 10 instancias de EC2 adicionales para gestionar la carga en caso de que se produzca un error en la AZ, lo que supone un total de 20 instancias de EC2 (siguiendo el patrón de estabilidad estática).
Si bien parece que hablamos de 10 instancias de EC2 de reserva o de repuesto, en realidad se trata de una única AZ de reserva, por lo que no hemos superado el punto de rentabilidad decreciente. Sin embargo, puede disfrutar de más rentabilidad y, al mismo tiempo, incrementar la disponibilidad si utiliza tres AZ e implementa cinco instancias de EC2 por AZ.
Esto proporciona una AZ de reserva con un total de 15 instancias de EC2 (frente a dos AZ con 20 instancias) y, al mismo tiempo, proporciona las 10 instancias necesarias en total para atender los picos de capacidad durante un evento que afecte a una única AZ. Por lo tanto, debe incorporar repuestos para tolerar los errores en todos los límites de aislamiento de errores utilizados por la carga de trabajo (instancia, celda, AZ y región).
