Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Disponibilidad de los sistemas distribuidos
Los sistemas distribuidos se componen tanto de componentes de software como de componentes de hardware. Algunos de los componentes de software podrían ser en sí mismos otro sistema distribuido. La disponibilidad de los componentes de hardware y software subyacentes afecta a la disponibilidad resultante de la carga de trabajo.
El cálculo de la disponibilidad mediante el tiempo medio entre errores (MTBF) y el tiempo medio de reparación o recuperación (MTTR) tiene sus raíces en los sistemas de hardware. Sin embargo, los sistemas distribuidos fallan por motivos muy diferentes a los de un componente de hardware. Mientras que un fabricante puede calcular de manera coherente el tiempo promedio antes de que se deteriore un componente de hardware, las mismas pruebas no se pueden aplicar a los componentes de software de un sistema distribuido. El software suele seguir la curva en forma de bañera (donde la curva desciende primero bruscamente, luego se produce un periodo de estabilidad y, por último, la curva asciende de manera drástica), mientras que el software sigue una curva escalonada producida por los defectos adicionales que se van introduciendo con cada nueva versión (consulte Fiabilidad del software
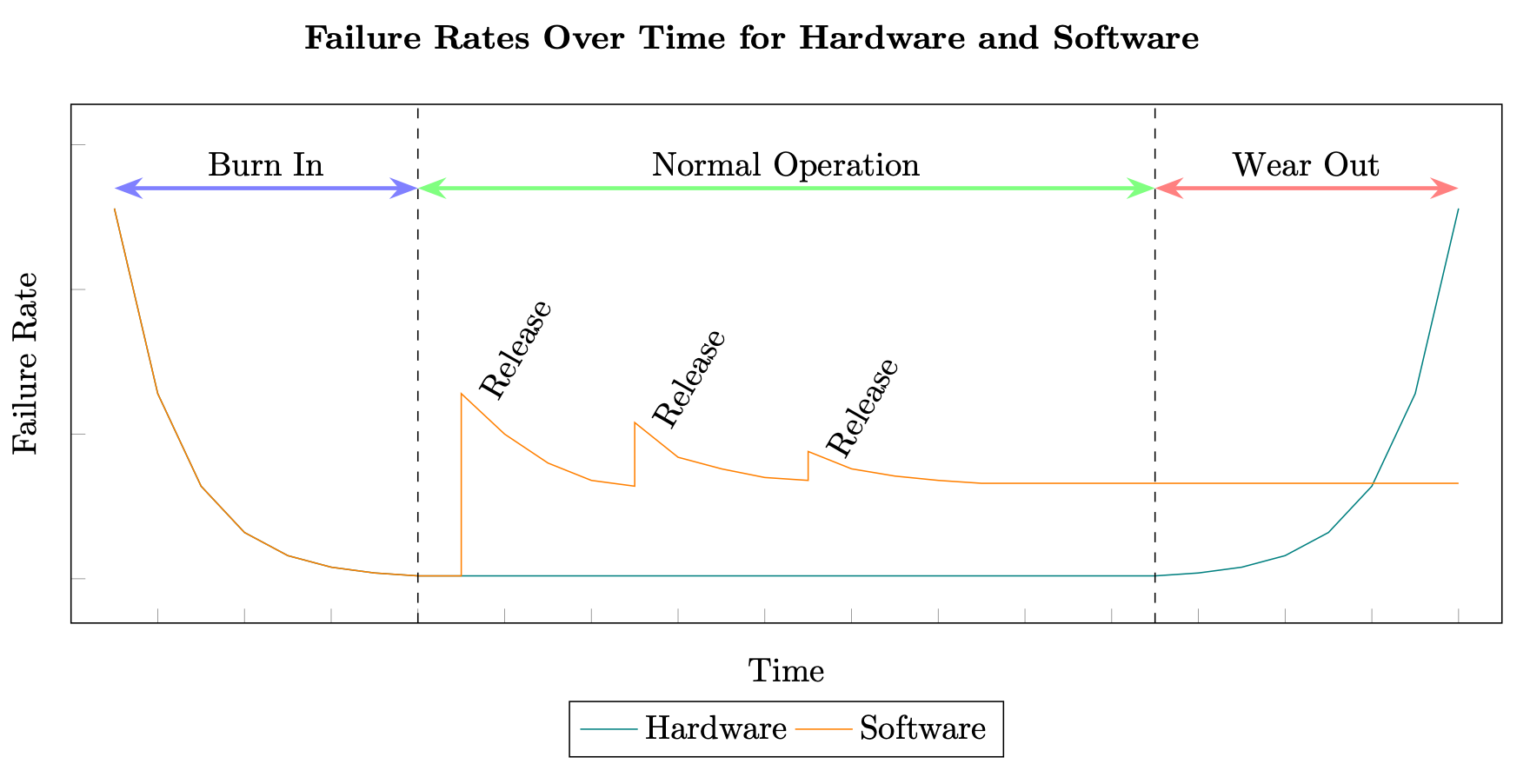
Índices de hardware y software
Además, el software de los sistemas distribuidos suele cambiar a índices exponencialmente superiores a las del hardware. Por ejemplo, un disco duro magnético estándar puede tener un índice medio de errores anual (AFR) del 0,93 %, lo que, en la práctica, en el caso de un disco HDD puede suponer una vida útil de al menos 3 a 5 años antes de que llegue al período de deterioro, y podría ser superior (consulte los datos y estadísticas sobre discos duros publicados en 2020 por Backblaze
El hardware también está sujeto al concepto de obsolescencia programada; es decir, tiene una vida útil incorporada y será necesario reemplazarlo después de un período de tiempo determinado. (Lea “The Great Lightbulb Conspiracy
Todo esto significa que los mismos modelos de prueba y predicción utilizados para calcular el MTBF y el MTTR del hardware no se aplican al software. Desde la década de 1970, se han realizado cientos de intentos de diseñar modelos para solucionar este problema, pero generalmente todos se dividen en dos categorías: modelos de predicción y modelos de estimación (consulte la lista de modelos de fiabilidad del software
Según esto, el cálculo de un MTBF y un MTTR prospectivos para sistemas distribuidos y, por lo tanto, de una disponibilidad prospectiva, siempre se derivará de algún tipo de predicción o estimación. Pueden generarse mediante modelos predictivos, simulaciones estocásticas, análisis históricos o pruebas rigurosas, pero esos cálculos no garantizan el tiempo de actividad o el tiempo de inactividad.
Es posible que las razones por las que un sistema distribuido falló en el pasado nunca vuelvan a repetirse. Es probable que las causas por las que se produzca un error en el futuro sean diferentes y, posiblemente, desconocidas. Los mecanismos de recuperación necesarios también pueden ser diferentes para errores futuros de los utilizados en el pasado y requerir mucho más o menos tiempo.
Además, los MTBF y MTTR son promedios. Habrá alguna variación entre el valor promedio y los valores reales observados (la desviación estándar [σ] mide esta variación). Por lo tanto, es posible que trascurra más o menos tiempo entre errores de las cargas de trabajo y que los tiempos de recuperación sean algo diferentes en un entorno de producción real.
Dicho esto, la disponibilidad de los componentes de software que componen un sistema distribuido sigue siendo importante. El software puede fallar por numerosos motivos (que se analizarán con más detalle en la siguiente sección) y repercuten en la disponibilidad de la carga de trabajo. Por lo tanto, en el caso de los sistemas distribuidos de alta disponibilidad, se debe prestar la misma atención al cálculo, la medición y la mejora de la disponibilidad de los componentes de software que a los subsistemas de hardware y software externos.
Regla 2
La disponibilidad del software en su carga de trabajo es un factor importante de la disponibilidad general de la carga de trabajo y debe recibir la misma atención que otros componentes.
Es importante señalar que, a pesar de que el MTBF y el MTTR son difíciles de predecir para los sistemas distribuidos, aún proporcionan información clave sobre cómo mejorar la disponibilidad. Reducir la frecuencia de los errores (mayor MTBF) y disminuir el tiempo de recuperación después de que se produzca un error (menor MTTR) redundará en una mayor disponibilidad empírica.
Tipos de errores en los sistemas distribuidos
En general, existen dos clases de errores en los sistemas distribuidos que afectan a la disponibilidad, denominados cariñosamente Bohrbug y Heisenbug (lea “A Conversation with Bruce Lindsay” de ACM Queue; vol. 2, núm. 8; noviembre de 2004).
Un Bohrbug es un problema de software funcional que se repite. Con los mismos datos de entrada, el error generará coherentemente los mismos datos de salida incorrectos (como el modelo atómico determinista de Bohr, que es sólido y se detecta fácilmente). Estos tipos de errores son poco frecuentes cuando una carga de trabajo entra en el entorno de producción.
Un Heisenbug es un error transitorio, lo que significa que solo ocurre en condiciones específicas e infrecuentes. Estas condiciones suelen estar relacionadas con aspectos como el hardware (por ejemplo, un error transitorio del dispositivo o detalles específicos de la implementación del hardware, como el tamaño del registro), optimizaciones del compilador e implementación del lenguaje, condiciones límite (por ejemplo, falta de almacenamiento temporal) o condiciones de carrera (por ejemplo, no usar un semáforo para operaciones con varios subprocesos).
Los errores Heisenbug constituyen la mayoría de los errores de producción y son difíciles de encontrar porque son esquivos y parecen cambiar de comportamiento o desaparecer cuando se intenta observarlos o depurarlos. Sin embargo, si se reinicia el programa, es probable que la operación fallida se realice correctamente porque el entorno operativo es ligeramente diferente, lo que elimina las condiciones que originaron el Heisenbug.
Por lo tanto, la mayoría de los errores en el entorno de producción son transitorios y, cuando se vuelve a intentar realizar la operación, es poco probable que vuelva a fallar. Para ser resilientes, los sistemas distribuidos tienen que ser tolerantes a los errores Heisenbug. Descubriremos cómo se logra esto en la sección Cómo incrementar el MTBF de los sistemas distribuidos.
