Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Cómo medir la disponibilidad
Como hemos visto anteriormente, crear un modelo de disponibilidad prospectivo para un sistema distribuido es difícil y puede que no proporcione los resultados deseados. Lo que puede ser más útil es desarrollar formas coherentes de medir la disponibilidad de la carga de trabajo.
La definición de disponibilidad como tiempo de actividad y tiempo de inactividad representa el error como una opción binaria: o bien la carga de trabajo está activa o no lo está.
Sin embargo, esto rara vez es el caso. El error tiene cierto grado de impacto y, a menudo, se produce en algún subconjunto de la carga de trabajo y afecta a un porcentaje de usuarios o solicitudes, a un porcentaje de ubicaciones o a un percentil de latencia. Todos estos son modos de error parcial.
Y si bien el tiempo medio de recuperación (MTTR) y el tiempo medio entre errores (MTBF) son útiles para comprender qué es lo que impulsa la disponibilidad resultante de un sistema y, por lo tanto, cómo mejorarlo, su utilidad no representa una medida empírica de la disponibilidad. Además, las cargas de trabajo se componen de muchos elementos. Por ejemplo, una carga de trabajo tipo un sistema de procesamiento de pagos se compone de muchas interfaces de programación de aplicaciones (API) y subsistemas. Entonces, cuando nos preguntamos por la disponibilidad de toda la carga de trabajo, estamos haciendo una pregunta muy compleja y con matices.
En esta sección, vamos a examinar tres formas de medir empíricamente la disponibilidad: el índice de éxito de las solicitudes del servidor, el índice de éxito de las solicitudes del cliente y el tiempo de inactividad anual.
Índice de éxito de las solicitudes del servidor y del cliente
Los dos primeros métodos son muy similares y solo que difieren desde el punto de vista en que se realiza la medición. Las métricas del servidor se pueden recopilar a partir de la instrumentación del servicio. Sin embargo, no están completas. Si los clientes no pueden acceder al servicio, las métricas no podrán recopilarse. Para entender la experiencia del cliente, en lugar de confiar en la telemetría de los clientes para detectar solicitudes con errores, una forma más sencilla de recopilar métricas del cliente es simular el tráfico de clientes con valores controlados de un software que comprueba periódicamente los servicios y registra las métricas.
Estos dos métodos calculan la disponibilidad como la fracción del total de unidades de trabajo válidas que el servicio recibe y las que procesa correctamente (ignora las unidades de trabajo no válidas, como una solicitud HTTP que causa un error 404).

Ecuación 8
Para un servicio basado en solicitudes, la unidad de trabajo es la solicitud, como una solicitud HTTP. En el caso de los servicios basados en eventos o en tareas, las unidades de trabajo son eventos o tareas, como procesar un mensaje de una cola. Esta medida de disponibilidad es significativa en intervalos de tiempo cortos, como intervalos de uno o cinco minutos. También es más adecuada desde una perspectiva granular, por ejemplo, a nivel de API para un servicio basado en solicitudes. La siguiente figura proporciona una vista del aspecto que podría tener la disponibilidad a lo largo del tiempo si se calcula de esta manera. Cada punto de datos del gráfico se calcula mediante la ecuación (8) durante un período de cinco minutos (se pueden elegir otras dimensiones de tiempo, como intervalos de uno o diez minutos). Por ejemplo, el punto de datos 10 muestra una disponibilidad del 94,5 %. Esto significa que, entre los minutos t+45 y t+50, si el servicio recibió 1000 solicitudes, solo 945 de ellas se procesaron correctamente.
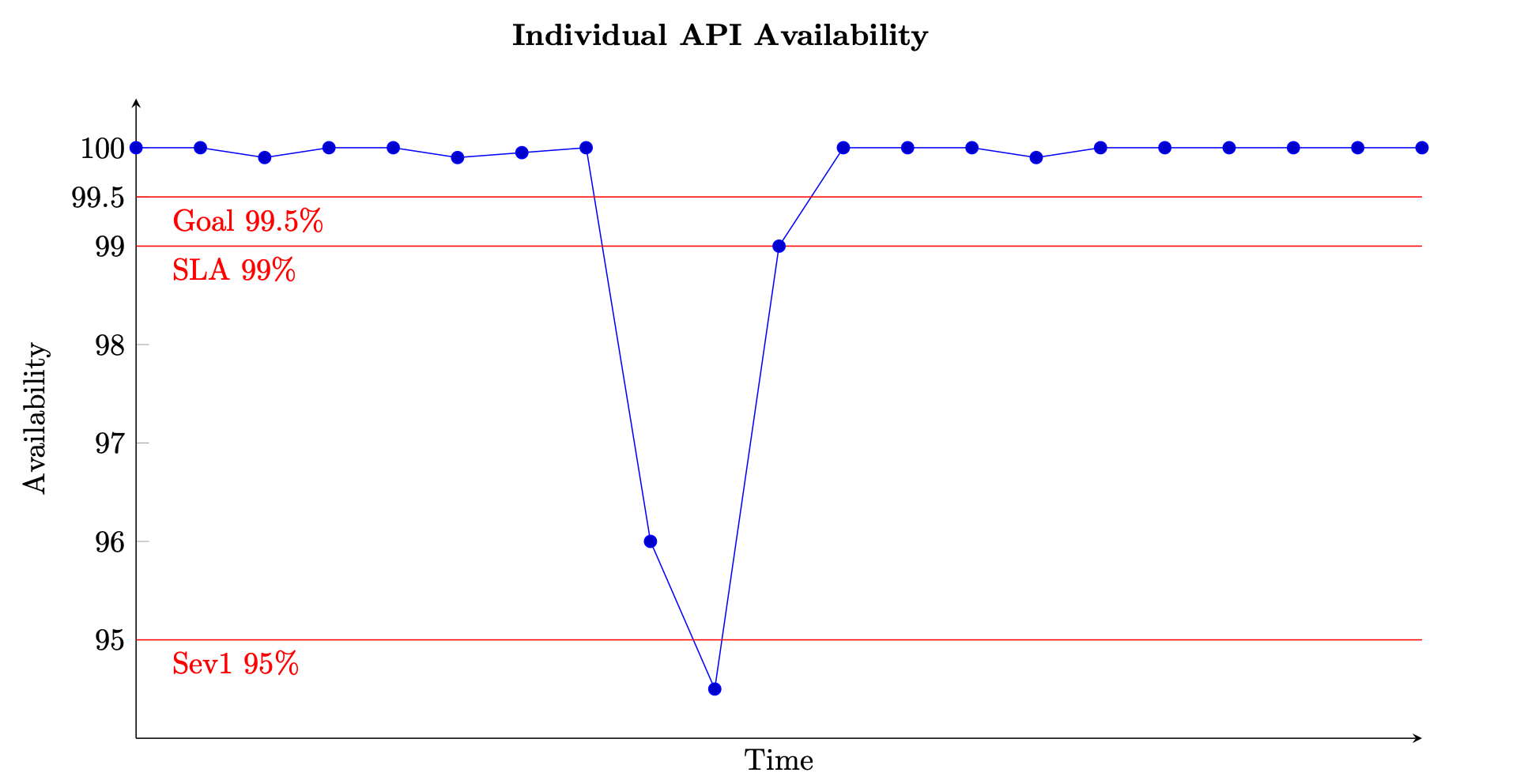
Ejemplo de medición de la disponibilidad a lo largo del tiempo para una sola API
El gráfico también muestra el objetivo de disponibilidad de la API (99,5 %), el acuerdo de nivel de servicio (SLA) que ofrece a los clientes en cuanto a la disponibilidad (99 %) y el umbral para que se envíe una alarma de alta gravedad (95 %). Sin el contexto de estos diferentes umbrales, es posible que un gráfico de disponibilidad no proporcione información significativa sobre el funcionamiento del servicio.
También queremos poder hacer un seguimiento de la disponibilidad de un subsistema más grande y describirla, como un plano de control, o de un servicio completo. Una forma de hacerlo es tomar el promedio de cada punto de datos de cinco minutos para cada subsistema. El gráfico tendrá un aspecto similar al anterior, pero representará un conjunto más grande de datos de entrada. También otorga el mismo peso a todos los subsistemas que componen el servicio. Un enfoque alternativo podría ser sumar todas las solicitudes recibidas y procesadas con éxito de todas las API en el servicio para calcular la disponibilidad en intervalos de cinco minutos.
Sin embargo, este último método podría ocultar una API individual con un bajo rendimiento y una baja disponibilidad. Tomemos como ejemplo sencillo un servicio con dos API.
La primera API recibe 1 000 000 de solicitudes en un período de cinco minutos y procesa correctamente 999 000 de ellas, lo que proporciona una disponibilidad del 99,9 %. La segunda API recibe 100 solicitudes en el mismo período de cinco minutos y procesa correctamente solamente 50 de ellas, lo que proporciona una disponibilidad del 50 %.
Si sumamos las solicitudes de ambas API, tenemos un total de 1 000 100 solicitudes válidas y 999 050 de ellas se procesaron correctamente, lo que supone una disponibilidad del 99,895 % para el servicio en general. Sin embargo, si calculamos la media de las disponibilidades de las dos API (el primer método), obtenemos una disponibilidad del 74,95 %, lo que podría reflejar mejor la experiencia real.
Ninguno de los dos enfoques es erróneo, pero demuestra la importancia de entender lo que indican las métricas de disponibilidad. Puede optar por sumar las solicitudes de todos los subsistemas si su carga de trabajo recibe un volumen de solicitudes similar en cada uno de ellos. Este enfoque se centra en la propia solicitud y en su éxito como medida de la disponibilidad y la experiencia del cliente. Como alternativa, puede optar por calcular la media de las disponibilidades de los subsistemas para representar de manera equitativa su criticidad, a pesar de las diferencias existentes en el volumen de solicitudes. Este enfoque se centra en los subsistemas y en la capacidad de cada uno de ellos como indicador de la experiencia del cliente.
Tiempo de inactividad anual
El tercer enfoque consiste en calcular el tiempo de inactividad anual. Esta forma de métrica de disponibilidad es más adecuada para establecer y revisar objetivos a largo plazo. Requiere definir qué significa el tiempo de inactividad para la carga de trabajo. Después, puede medir la disponibilidad en función del número de minutos que la carga de trabajo no estuvo en estado de interrupción en relación con el número total de minutos del período determinado.
Es posible que algunas cargas de trabajo puedan definir el tiempo de inactividad como una caída por debajo del 95 % de la disponibilidad de una sola API o función de la carga de trabajo durante un intervalo de uno o cinco minutos (lo que vimos en el gráfico de disponibilidad anterior). También puede considerar el tiempo de inactividad solo en lo que respecta a un subconjunto de operaciones críticas del plano de datos. Por ejemplo, el acuerdo de nivel de servicio de mensajería de Amazon (SQS, SNS)
Es posible que las cargas de trabajo más grandes y complejas deban definir las métricas de disponibilidad de todo el sistema. En el caso de un sitio de comercio electrónico de grandes dimensiones, una métrica para todo el sistema puede ser algo así como el volumen de pedidos de los clientes. En este caso, una caída del 10 % o más en los pedidos en comparación con la cantidad prevista durante un período de cinco minutos puede definir el tiempo de inactividad.
En cualquiera de los dos enfoques, se pueden sumar todos los períodos de interrupción para calcular la disponibilidad anual. Por ejemplo, si durante un año natural hubo 27 períodos de inactividad de cinco minutos, definidos como una disminución de la disponibilidad de cualquier API del plano de datos por debajo del 95 %, el tiempo de inactividad total fue de 135 minutos (algunos períodos de cinco minutos podrían haber sido consecutivos y otros aislados), lo que representa una disponibilidad anual del 99,97 %.
Este método adicional de medición de la disponibilidad puede proporcionar datos e información que no se encuentran ni en las métricas del cliente ni en las del servidor. Tomemos como ejemplo una carga de trabajo que no funciona correctamente y que presenta índices de error significativamente elevados. Los clientes de esta carga de trabajo podrían dejar de realizar llamadas a sus servicios. Tal vez hayan activado un interruptor o hayan seguido su plan de recuperación de desastres
Latencia
Por último, también es importante medir la latencia de las unidades de trabajo de procesamiento dentro de la carga de trabajo. Parte de la definición de disponibilidad implica realizar el trabajo dentro de un SLA establecido. Si devolver una respuesta tarda más tiempo que el tiempo de espera del cliente, el cliente piensa que la solicitud ha fallado y que la carga de trabajo no está disponible. Sin embargo, en el servidor, puede parecer que la solicitud se ha procesado correctamente.
La medición de la latencia proporciona otra perspectiva con la que evaluar la disponibilidad. Los percentiles y la media recortada son buenas estadísticas para esta medición. Por lo general, se miden en el percentil 50 (P50 y MR50) y en el percentil 99 (P99 y MR99). La latencia debe medirse con valores controlados a la hora de representar la experiencia del cliente, así como con métricas del servidor. Cada vez que el promedio de algún percentil de latencia (como P99 o MR99,9) supere el SLA objetivo, se puede tener en cuenta ese tiempo de inactividad, lo que contribuye al cálculo del tiempo de inactividad anual.
