Fiabilidad
Definición
La fiabilidad hace referencia a la capacidad de un servicio o sistema para realizar su función prevista cuando sea necesario. La fiabilidad de un sistema puede medirse por el nivel de su calidad operativa en un plazo determinado. Se contrapone a la resiliencia, que se refiere a la capacidad de un sistema para recuperarse de las interrupciones de la infraestructura o de los servicios, de forma dinámica y fiable.
Para obtener más detalles sobre cómo se utilizan la disponibilidad y la resiliencia para medir la fiabilidad, consulte el pilar de fiabilidad del Marco de AWS Well-Architected.
Preguntas clave
Disponibilidad
La disponibilidad es el porcentaje de tiempo que una carga de trabajo está disponible para utilizarse. Entre los objetivos comunes se incluyen el 99 % (3,65 días de tiempo de inactividad permitido al año), el 99,9 % (8,77 horas) y el 99,99 % (52,6 minutos), con una abreviatura del número de nueves en el porcentaje ("dos nueves" para el 99 %, "tres nueves" para el 99,9 %, y así sucesivamente). La disponibilidad de la solución de red entre AWS y el centro de datos en las instalaciones puede ser diferente de la disponibilidad general de la solución o de la aplicación.
Entre las preguntas clave sobre la disponibilidad de una solución de red se incluyen las siguientes:
-
¿Pueden seguir funcionando mis recursos de AWS si no pueden comunicarse con mis recursos en las instalaciones? ¿Y a la inversa?
-
¿Debo considerar el tiempo de inactividad programado para el mantenimiento planificado como incluido o excluido de la métrica de disponibilidad?
-
¿Cómo mediré la disponibilidad de la capa de red, separada del estado general de la aplicación?
La sección Disponibilidad del pilar de fiabilidad del Marco de Well-Architected contiene sugerencias y fórmulas para calcular la disponibilidad.
Resistencia
La resiliencia es la capacidad de una carga de trabajo para recuperarse de interrupciones en la infraestructura o el servicio, para incorporar dinámicamente recursos computacionales que satisfagan la demanda y para mitigar las interrupciones, como errores de configuración o problemas de red temporales. Si un componente de red redundante (enlace, dispositivos de red, etc.) no tiene la disponibilidad suficiente para proporcionar la función esperada por sí solo, significa que tiene una baja resiliencia a los errores. La consecuencia es una experiencia de usuario deficiente y degradada.
Entre las preguntas clave sobre la resiliencia de una solución de red se incluyen las siguientes:
-
¿Cuántos errores simultáneos y discretos debo permitir?
-
¿Cómo puedo reducir los puntos únicos de error tanto con las soluciones de conectividad como con mi red interna?
-
¿Cuál es mi vulnerabilidad ante los eventos de denegación de servicio distribuido (DDoS)?
Solución técnica
En primer lugar, es importante tener en cuenta que no todas las soluciones de conectividad de red híbrida requieren un elevado nivel de fiabilidad y que el aumento de los niveles de fiabilidad tiene su correspondiente incremento de costo. En algunos escenarios, un sitio principal puede requerir conexiones fiables (redundantes y resilientes), ya que el tiempo de inactividad tiene un mayor impacto en la empresa, mientras que los sitios regionales pueden no requerir el mismo nivel de fiabilidad debido al menor impacto en la empresa en caso de un evento de error. Se recomienda consultar las Recomendaciones sobre resiliencia de AWS Direct Connect
Para lograr una solución de conectividad de red híbrida fiable en el contexto de resiliencia, el diseño debe tener en cuenta los siguientes aspectos:
-
Redundancia: el objetivo es eliminar cualquier punto único de error en la ruta de conectividad de red híbrida, incluidas, entre otras, las conexiones de red, los dispositivos de red periférica, la redundancia en las zonas de disponibilidad, Regiones de AWS y las ubicaciones de DX, así como las fuentes de alimentación de los dispositivos, las rutas de fibra y los sistemas operativos. Para el propósito y el alcance de este documento técnico, la redundancia se centra en las conexiones de red, los dispositivos periféricos (por ejemplo, los dispositivos de puerta de enlace de cliente), la ubicación de AWS DX y Regiones de AWS (para arquitecturas de varias regiones).
-
Componentes de conmutación por error fiables: en algunos escenarios, un sistema puede ser funcional, pero no desempeñar sus funciones al nivel requerido. Esta situación es habitual durante un evento de error único en el que se descubre que los componentes redundantes planificados funcionaban de forma no redundante: su carga de red no tiene otro lugar al que acudir debido al uso, lo que provoca una capacidad insuficiente para toda la solución.
-
Tiempo de conmutación por error: es el tiempo que tarda un componente secundario en asumir completamente el rol del componente principal. El tiempo de conmutación por error depende de varios factores: cuánto se tarda en detectar el error, cuánto se tarda en habilitar la conectividad secundaria y cuánto se tarda en notificar el cambio al resto de la red. La detección de errores puede mejorarse mediante la detección de pares muertos (DPD) en el caso de los enlaces VPN y la detección de reenvío bidireccional (BFD) en el caso de los enlaces de AWS Direct Connect. El tiempo para habilitar la conectividad secundaria puede ser muy bajo (si estas conexiones están siempre activas), puede ser un intervalo de tiempo corto (si hay que habilitar una conexión de VPN preconfigurada) o más largo (si hay que mover recursos físicos o configurar nuevos recursos). La notificación al resto de la red suele producirse a través de protocolos de enrutamiento en la red del cliente, cada uno de los cuales tiene diferentes tiempos de convergencia y opciones de configuración. En este documento técnico no se aborda la configuración de los mismos.
-
Ingeniería de tráfico: en el contexto del diseño de una conectividad de red híbrida resiliente, la ingeniería de tráfico tiene como objetivo abordar cómo debe fluir el tráfico a través de las múltiples conexiones disponibles en escenarios normales y de error. Se recomienda seguir el concepto de diseño preparado para errores, en el que hay que ver cómo funcionará la solución en diferentes escenarios de error y si será aceptable para la empresa o no. En esta sección se analizan algunos de los casos de uso habituales de la ingeniería de tráfico, cuyo objetivo es mejorar el nivel general de resiliencia de la solución de conectividad de red híbrida. En la sección sobre enrutamiento y BGP de AWS Direct Connect se habla de varias opciones de ingeniería de tráfico para influir en el flujo de tráfico (comunidades, preferencia local BGP o longitud de la ruta AS). Para diseñar una solución de ingeniería de tráfico eficaz, debe conocer bien cómo cada uno de los componentes de red de AWS gestiona el enrutamiento IP en términos de evaluación y selección de rutas, así como los posibles mecanismos para influir en la selección de rutas. En este documento no se abordan los detalles al respecto. Para obtener más información, consulte la documentación Orden de evaluación de rutas de Transient Gateway, Prioridad de rutas de VPN de sitio a sitio y Enrutamiento de Direct Connect y BGP, según sea necesario.
nota
En la tabla de enrutamiento de VPC, puede hacer referencia a una lista de prefijos que tenga reglas adicionales de selección de rutas. Para obtener más información sobre este caso de uso, consulte la prioridad de ruta para listas de prefijos. Las tablas de enrutamiento de AWS Transit Gateway también admiten listas de prefijos, pero, una vez aplicadas, se amplían a entradas de ruta específicas.
Ejemplo de doble conexión de VPN de sitio a sitio con rutas más específicas
Este escenario se basa en un pequeño sitio en las instalaciones que se conecta a una única región de Región de AWS mediante conexiones de VPN redundantes a través de Internet a AWS Transit Gateway. El diseño de ingeniería de tráfico representado en la figura 10 muestra que con la ingeniería de tráfico se puede influir en la selección de ruta que aumenta la fiabilidad de la solución de conectividad híbrida:
-
Conectividad híbrida resiliente: las conexiones de VPN redundantes proporcionan cada una la misma capacidad de rendimiento, admiten la conmutación por error automatizada mediante el uso del protocolo de enrutamiento dinámico (BGP) y aceleran la detección de errores de conexión mediante la detección de pares muertos de VPN.
-
Eficiencia de rendimiento: la configuración de ECMP en ambas conexiones de VPN a AWS Transit Gateway contribuye a maximizar el ancho de banda total de la conexión de VPN. Como alternativa, mediante el anuncio de rutas diferentes, más específicas, junto con la ruta de resumen del sitio, se puede administrar la carga de forma independiente en las dos conexiones de VPN.

Figura 10. Ejemplo de doble conexión de VPN de sitio a sitio con rutas más específicas
Ejemplo de dos sitios en las instalaciones con varias conexiones de DX
El escenario representado en la figura 11 muestra dos sitios de centros de datos en las instalaciones situados en diferentes regiones geográficas y conectados a AWS a través del modelo de conectividad de máxima resiliencia (descrito en las Recomendaciones de resiliencia de AWS Direct Connect
Al asociar atributos de comunidad BGP a las rutas anunciadas a AWS DXGW, puede influir en la selección de la ruta de salida desde AWS DXGW. Estos atributos de comunidad controlan el atributo de preferencia local BGP de AWS asignado a la ruta anunciada. Para obtener más información, consulte Políticas de enrutamiento y comunidades BGP de AWS DX.
Para maximizar la fiabilidad de la conectividad en el nivel de Región de AWS, cada par de conexiones de AWS DX configura ECMP de modo que ambas puedan utilizarse al mismo tiempo para la transferencia de datos entre cada sitio en las instalaciones y AWS.

Figura 11. Ejemplo de dos sitios en las instalaciones con varias conexiones de DX
Con este diseño, los flujos de tráfico destinados a las redes en las instalaciones (con la misma longitud de prefijo anunciada y comunidad BGP) se distribuirán a través de las conexiones de DX duales por sitio mediante ECMP. No obstante, si no se requiere ECMP a través de la conexión de DX, se puede utilizar el mismo concepto comentado anteriormente y descrito en la documentación de Routing policies and BGP communities para diseñar aún más la selección de rutas en el nivel de conexión de DX.
Nota: Si hay dispositivos de seguridad en la ruta en los centros de datos en las instalaciones, estos dispositivos deben configurarse para permitir flujos de tráfico que salgan por un enlace de DX y lleguen desde otro enlace de DX (ambos enlaces se utilizan con ECMP) en el mismo sitio de centro de datos.
Ejemplo de conexión de VPN como copia de seguridad de la conexión de AWS DX
Se puede seleccionar VPN para proporcionar una conexión de red de copia de seguridad a una conexión de AWS Direct Connect. Normalmente, este tipo de modelo de conectividad se basa en el costo, ya que proporciona un menor nivel de fiabilidad a la solución global de conectividad híbrida debido al rendimiento no determinista a través de Internet, y no existe un SLA que pueda obtenerse para una conexión a través del Internet público. Es un modelo de conectividad válido y económico, y debe utilizarse cuando el costo sea la consideración prioritaria y se disponga de un presupuesto limitado, o posiblemente como solución provisional hasta que pueda aprovisionarse un DX secundario. En la figura 12 se ilustra el diseño de este modelo de conectividad. Una consideración clave con este diseño, en el que tanto la conexión de VPN como la de DX terminan en AWS Transit Gateway, es que la conexión de VPN puede anunciar un mayor número de rutas en comparación con las que se pueden anunciar a través de una conexión de DX realizada a AWS Transit Gateway. Esto puede provocar una situación de enrutamiento poco óptima. Una opción para resolver este problema es configurar el filtrado de rutas en el dispositivo de puerta de enlace de cliente (CGW) para las rutas recibidas de la conexión de VPN, de forma que solo se permitan las rutas de resumen.
Nota: Para crear la ruta resumen en AWS Transit Gateway, es necesario especificar una ruta estática a un adjunto arbitrario en la tabla de enrutamiento de AWS Transit Gateway para que el resumen se envíe a lo largo de la ruta más específica.
Desde el punto de vista de la tabla de enrutamiento de AWS Transit Gateway, las rutas para el prefijo en las instalaciones se reciben tanto de la conexión de AWS DX (a través de DXGW) como de VPN, con la misma longitud de prefijo. Siguiendo la lógica de prioridad de rutas de AWS Transit Gateway, las rutas recibidas a través de Direct Connect tienen una mayor preferencia que las recibidas a través de VPN de sitio a sitio y, por lo tanto, la ruta a través de AWS Direct Connect será la preferida para llegar a las redes en las instalaciones.
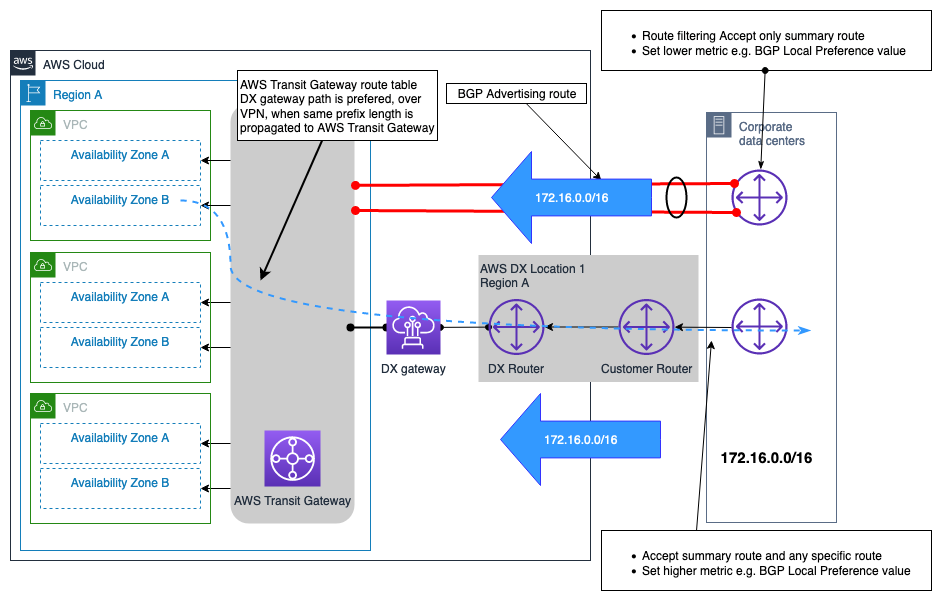
Figura 12. Ejemplo de conexión de VPN como copia de seguridad de la conexión de AWS DX
El siguiente árbol de decisiones le servirá de guía a la hora de tomar la decisión deseada para conseguir una conectividad de red híbrida resiliente (lo que se traducirá en una red fiable). Para obtener más información, consulte Kit de herramientas de resiliencia de AWS Direct Connect.

Figura 13. Árbol de decisiones de fiabilidad
