Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Réglage des paramètres de mémoire pour Aurora PostgreSQL
Dans Amazon Aurora PostgreSQL, vous pouvez utiliser plusieurs paramètres qui contrôlent la quantité de mémoire utilisée pour diverses tâches de traitement. Si une tâche prend plus de mémoire que la quantité définie pour un paramètre donné, Aurora PostgreSQL utilise d’autres ressources pour le traitement, par exemple en écrivant sur le disque. Cela peut entraîner un ralentissement ou un arrêt de votre cluster de bases de données Aurora PostgreSQL, avec une erreur de mémoire insuffisante.
Le réglage par défaut de chaque paramètre de mémoire permet généralement de traiter les tâches prévues. Cependant, vous pouvez également régler les paramètres liés à la mémoire de votre cluster de bases de données Aurora PostgreSQL . Vous effectuez ce réglage pour vous assurer qu’une quantité suffisante de mémoire est allouée pour traiter votre charge de travail spécifique.
Vous trouverez ci-dessous des informations sur les paramètres qui contrôlent la gestion de la mémoire. Vous pouvez également apprendre à évaluer l’utilisation de la mémoire.
Vérification et réglage des valeurs des paramètres
Les paramètres que vous pouvez définir pour gérer la mémoire et évaluer l’utilisation de la mémoire de votre cluster de bases de données Aurora PostgreSQL sont les suivants :
work_mem: spécifie la quantité de mémoire que le cluster de bases de données Aurora PostgreSQL utilise pour les opérations de tri internes et les tables de hachage avant d’écrire dans des fichiers disques temporaires.log_temp_files: consigne la création de fichiers temporaires, leurs noms et leurs tailles. Lorsque ce paramètre est activé, une entrée de journal est enregistrée pour chaque fichier temporaire créé. Activez cette option pour voir à quelle fréquence votre cluster de bases de données Aurora PostgreSQL doit écrire sur le disque. Désactivez-la à nouveau après avoir recueilli des informations sur la génération de fichiers temporaires de votre cluster de bases de données Aurora PostgreSQL, pour éviter une journalisation excessive.logical_decoding_work_mem: spécifie la quantité de mémoire (en kilooctets) à utiliser par chaque tampon interne de réorganisation avant le déversement sur le disque. Cette mémoire est utilisée pour le décodage logique, qui désigne le processus de création d’un réplica. Il s’effectue en convertissant les données du fichier journal à écriture anticipée (WAL) en sortie de streaming logique nécessaire à la cible.La valeur de ce paramètre crée un seul tampon de la taille spécifiée pour chaque connexion de réplication. Par défaut, elle est de 65536 Ko. Une fois ce tampon rempli, l’excédent est écrit sur le disque sous forme de fichier. Pour minimiser l’activité du disque, vous pouvez définir la valeur de ce paramètre sur une valeur beaucoup plus élevée que celle de
work_mem.
Ce sont tous des paramètres dynamiques, vous pouvez donc les modifier pour la session en cours. Pour ce faire, connectez-vous au cluster de bases de données Aurora PostgreSQL avec psql et en utilisant l’instruction SET, comme indiqué ci-dessous.
SET parameter_name TO parameter_value;Les paramètres de la session ne sont valables que pour la durée de la session. Lorsque la session se termine, le paramètre revient à sa valeur dans le groupe de paramètres de la base de données. Avant de modifier un paramètre, vérifiez d’abord les valeurs actuelles en interrogeant la table pg_settings, comme suit.
SELECT unit, setting, max_val FROM pg_settings WHERE name='parameter_name';
Par exemple, pour trouver la valeur du paramètre work_mem, connectez-vous à l’instance d’enregistreur du cluster de bases de données Aurora PostgreSQL et exécutez la requête suivante.
SELECT unit, setting, max_val, pg_size_pretty(max_val::numeric) FROM pg_settings WHERE name='work_mem';unit | setting | max_val | pg_size_pretty ------+----------+-----------+---------------- kB | 1024 | 2147483647| 2048 MB (1 row)
Pour modifier les paramètres afin qu’ils persistent, il faut utiliser un groupe de paramètres de cluster de bases de données personnalisé. Après avoir testé votre cluster de bases de données RDS pour PostgreSQL avec différentes valeurs pour ces paramètres à l’aide de l’instruction SET, vous pouvez créer un groupe de paramètres personnalisé et l’appliquer à votre cluster de bases de données Aurora PostgreSQL. Pour plus d’informations, consultez Groupes de paramètres pour Amazon Aurora.
Comprendre le paramètre de la mémoire de travail
Le paramètre de mémoire de travail (work_mem) spécifie la quantité maximale de mémoire qu’Aurora PostgreSQL peut utiliser pour traiter des requêtes complexes. Les requêtes complexes comprennent celles qui impliquent des opérations de tri ou de regroupement ; en d’autres termes, les requêtes qui utilisent les clauses suivantes :
ORDER BY
DISTINCT
GROUP BY
JOIN (MERGE et HASH)
Le planificateur de requêtes affecte indirectement la façon dont votre cluster de bases de données Aurora PostgreSQL utilise la mémoire de travail. Le planificateur de requêtes génère des plans d’exécution pour le traitement des instructions SQL. Un plan donné peut décomposer une requête complexe en plusieurs unités de travail qui peuvent être exécutées en parallèle. Lorsque cela est possible, Aurora PostgreSQL utilise la quantité de mémoire spécifiée dans le paramètre work_mem pour chaque session avant d’écrire sur le disque pour chaque processus parallèle.
Plusieurs utilisateurs de bases de données exécutant plusieurs opérations simultanément et générant plusieurs unités de travail en parallèle peuvent épuiser la mémoire de travail allouée à votre cluster de bases de données Aurora PostgreSQL. Cela peut entraîner la création excessive de fichiers temporaires et d’entrées/sorties sur le disque, ou pire, cela peut entraîner une erreur de mémoire insuffisante.
Identifier l’utilisation des fichiers temporaires
Lorsque la mémoire nécessaire au traitement des requêtes dépasse la valeur spécifiée dans le paramètre work_mem, les données de travail sont déchargées sur le disque dans un fichier temporaire. Vous pouvez voir combien de fois cela se produit en activant le paramètre log_temp_files. Par défaut, ce paramètre est désactivé (il est défini sur -1). Pour capturer toutes les informations relatives aux fichiers temporaires, définissez ce paramètre sur 0. Définissez log_temp_files sur tout autre nombre entier positif pour capturer les informations de fichier temporaire pour les fichiers égaux ou supérieurs à cette quantité de données (en kilo-octets). Dans l’image suivante, vous pouvez voir un exemple de la AWS Management Console.
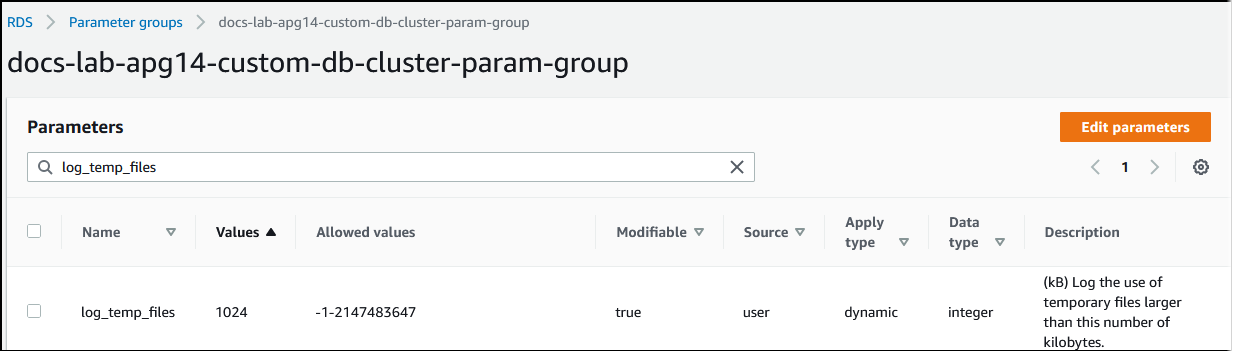
Après avoir configuré la journalisation des fichiers temporaires, vous pouvez tester votre propre charge de travail pour voir si votre paramètre de mémoire de travail est suffisant. Vous pouvez également simuler une charge de travail en utilisant pgbench, une application d’évaluation simple de la communauté PostgreSQL.
L’exemple suivant initialise pgbench (-i) en créant les tables et les lignes nécessaires à l’exécution des tests. Dans cet exemple, le facteur d’échelle (50 -s) crée 50 lignes dans la table pgbench_branches, 500 lignes dans pgbench_tellers, et 5 000 000 lignes dans la table pgbench_accounts de la base de données labdb.
pgbench -U postgres -h your-cluster-instance-1.111122223333.aws-regionrds.amazonaws.com -p 5432 -i -s 50 labdb
Password:
dropping old tables...
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
creating tables...
generating data (client-side)...
5000000 of 5000000 tuples (100%) done (elapsed 15.46 s, remaining 0.00 s)
vacuuming...
creating primary keys...
done in 61.13 s (drop tables 0.08 s, create tables 0.39 s, client-side generate 54.85 s, vacuum 2.30 s, primary keys 3.51 s)Après avoir initialisé l’environnement, vous pouvez exécuter l’évaluation pour une durée spécifique (-T) et le nombre de clients (-c). Cet exemple utilise également l’option -d pour générer des informations de débogage à mesure que les transactions sont traitées par le cluster de bases de données Aurora PostgreSQL.
pgbench -h -U postgresyour-cluster-instance-1.111122223333.aws-regionrds.amazonaws.com -p 5432 -d -T 60 -c 10labdbPassword:*******pgbench (14.3) starting vacuum...end. transaction type: <builtin: TPC-B (sort of)> scaling factor: 50 query mode: simple number of clients: 10 number of threads: 1 duration: 60 s number of transactions actually processed: 1408 latency average = 398.467 ms initial connection time = 4280.846 ms tps = 25.096201 (without initial connection time)
Pour obtenir plus d’informations sur pgbench, consultez pgbench
Vous pouvez utiliser la commande métacommande psql (\d) pour répertorier les relations telles que les tables, les vues et les index créés par pgbench.
labdb=>\d pgbench_accountsTable "public.pgbench_accounts" Column | Type | Collation | Nullable | Default ----------+---------------+-----------+----------+--------- aid | integer | | not null | bid | integer | | | abalance | integer | | | filler | character(84) | | | Indexes: "pgbench_accounts_pkey" PRIMARY KEY, btree (aid)
Comme le montre la sortie, la table pgbench_accounts est indexée sur la colonne aid. Pour s’assurer que la prochaine requête utilise la mémoire de travail, interrogez une colonne non indexée, comme celle présentée dans l’exemple suivant.
postgres=>SELECT * FROM pgbench_accounts ORDER BY bid;
Vérifiez la présence de fichiers temporaires dans le journal. Pour ce faire, ouvrez la AWS Management Console, choisissez l’instance du cluster de bases de données Aurora PostgreSQL, puis sélectionnez l’onglet Logs & Events (Journaux et événements). Visualisez les journaux dans la console ou téléchargez-les pour une analyse plus approfondie. Comme le montre l’image suivante, la taille des fichiers temporaires nécessaires au traitement de la requête indique que vous devriez envisager d’augmenter la quantité spécifiée pour le paramètre work_mem.
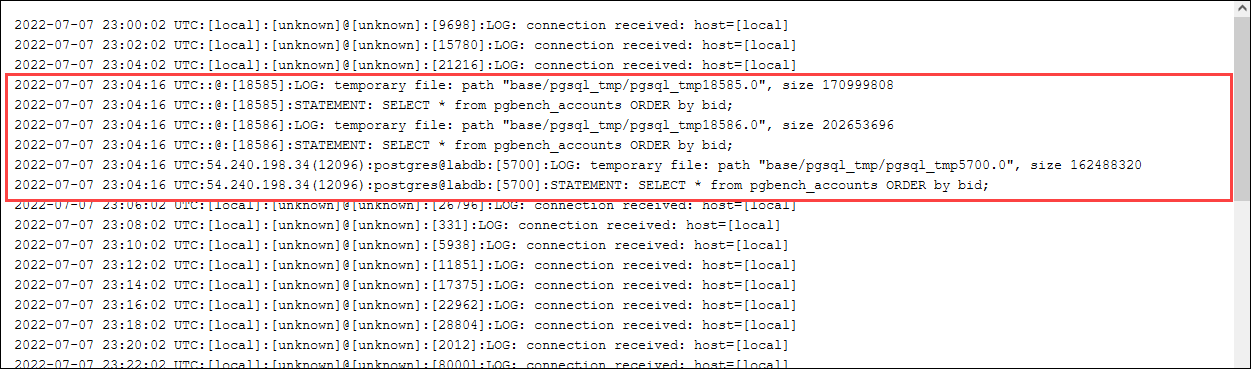
Vous pouvez configurer ce paramètre différemment pour les individus et les groupes, en fonction de vos besoins opérationnels. Par exemple, vous pouvez définir le paramètre work_mem sur 8 Go pour le rôle nommé dev_team.
postgres=>ALTER ROLEdev_teamSET work_mem=‘8GB';
Avec ce paramètre pour work_mem, tout rôle qui est membre du rôle dev_team se voit attribuer jusqu’à 8 Go de mémoire de travail.
Utilisation des index pour un temps de réponse plus rapide
Si vos requêtes prennent trop de temps pour renvoyer les résultats, vous pouvez vérifier que vos index sont utilisés comme prévu. Tout d’abord, activez \timing, la métacommande psql, comme suit.
postgres=>\timing on
Après avoir activé la synchronisation, utilisez une simple instruction SELECT.
postgres=>SELECT COUNT(*) FROM (SELECT * FROM pgbench_accounts ORDER BY bid) AS accounts;count ------- 5000000 (1 row) Time: 3119.049 ms (00:03.119)
Comme le montre la sortie, cette requête a pris un peu plus de 3 secondes pour se terminer. Pour améliorer le temps de réponse, créez un index sur pgbench_accounts, comme suit.
postgres=>CREATE INDEX ON pgbench_accounts(bid);CREATE INDEX
Relancez la requête et remarquez que le temps de réponse est plus rapide. Dans cet exemple, la requête a été effectuée environ cinq fois plus vite, en une demi-seconde environ.
postgres=>SELECT COUNT(*) FROM (SELECT * FROM pgbench_accounts ORDER BY bid) AS accounts;count ------- 5000000 (1 row) Time: 567.095 ms
Ajustement de la mémoire de travail pour le décodage logique
La réplication logique est disponible dans toutes les versions d’Aurora PostgreSQL depuis son introduction dans la version 10 de PostgreSQL. Lorsque vous configurez la réplication logique, vous pouvez également définir le paramètre logical_decoding_work_mem pour spécifier la quantité de mémoire que le processus de décodage logique peut utiliser pour le processus de décodage et de streaming.
Pendant le décodage logique, les enregistrements WAL (write-ahead log) sont convertis en instructions SQL qui sont ensuite envoyées à une autre cible pour la réplication logique ou une autre tâche. Lorsqu’une transaction est écrite dans le WAL et ensuite convertie, la totalité de la transaction doit tenir dans la valeur spécifiée pour logical_decoding_work_mem. Par défaut, ce paramètre est défini sur 65536 Ko. Tout dépassement est écrit sur le disque. Cela signifie qu’il doit être relu à partir du disque avant de pouvoir être envoyé à sa destination, ce qui ralentit le processus global.
Vous pouvez évaluer la quantité de déversement de transactions dans votre charge de travail actuelle à un moment précis en utilisant la fonction aurora_stat_file comme indiqué dans l’exemple suivant.
SELECT split_part (filename, '/', 2) AS slot_name, count(1) AS num_spill_files, sum(used_bytes) AS slot_total_bytes, pg_size_pretty(sum(used_bytes)) AS slot_total_size FROM aurora_stat_file() WHERE filename like '%spill%' GROUP BY 1;slot_name | num_spill_files | slot_total_bytes | slot_total_size ------------+-----------------+------------------+----------------- slot_name | 590 | 411600000 | 393 MB (1 row)
Cette requête renvoie le nombre et la taille des fichiers de déversement sur votre cluster de bases de données Aurora PostgreSQL lorsque la requête est appelée. Les charges de travail qui s’exécutent depuis longtemps peuvent ne pas avoir encore de fichiers de déversement sur le disque. Pour établir le profil des charges de travail à long terme, nous vous recommandons de créer une table pour capturer les informations du fichier de déversement au fur et à mesure de l’exécution de la charge de travail. Vous pouvez créer la table comme suit.
CREATE TABLE spill_file_tracking AS SELECT now() AS spill_time,* FROM aurora_stat_file() WHERE filename LIKE '%spill%';
Pour voir comment les fichiers de déversement sont utilisés pendant la réplication logique, configurez un éditeur et un abonné, puis lancez une réplication simple. Pour plus d’informations, consultez Configuration de la réplication logique pour votre cluster de bases de données Aurora PostgreSQL. Une fois la réplication en cours, vous pouvez créer une tâche qui capture l’ensemble de résultats à partir de la fonction de fichier de déversement aurora_stat_file(), comme suit.
INSERT INTO spill_file_tracking SELECT now(),* FROM aurora_stat_file() WHERE filename LIKE '%spill%';
Utilisez la commande psql suivante pour exécuter la tâche une fois par seconde.
\watch 0.5
Pendant que la tâche est en cours d’exécution, connectez-vous à l’instance en écriture depuis une autre session psql. Utilisez la série d’instructions suivante pour exécuter une charge de travail qui dépasse la configuration de la mémoire et amène Aurora PostgreSQL à créer un fichier de déversement.
labdb=>CREATE TABLE my_table (a int PRIMARY KEY, b int);CREATE TABLElabdb=>INSERT INTO my_table SELECT x,x FROM generate_series(0,10000000) x;INSERT 0 10000001labdb=>UPDATE my_table SET b=b+1;UPDATE 10000001
Ces déclarations prennent plusieurs minutes à s’effectuer. Lorsque vous avez terminé, appuyez simultanément sur les touches Ctrl et C pour arrêter la fonction de surveillance. Ensuite, utilisez la commande suivante pour créer une table qui contiendra les informations sur l’utilisation du fichier de déversement du cluster de bases de données Aurora PostgreSQL.
SELECT spill_time, split_part (filename, '/', 2) AS slot_name, count(1) AS spills, sum(used_bytes) AS slot_total_bytes, pg_size_pretty(sum(used_bytes)) AS slot_total_size FROM spill_file_tracking GROUP BY 1,2 ORDER BY 1;spill_time | slot_name | spills | slot_total_bytes | slot_total_size ------------------------------+-----------------------+--------+------------------+----------------- 2022-04-15 13:42:52.528272+00 | replication_slot_name | 1 | 142352280 | 136 MB 2022-04-15 14:11:33.962216+00 | replication_slot_name | 4 | 467637996 | 446 MB 2022-04-15 14:12:00.997636+00 | replication_slot_name | 4 | 569409176 | 543 MB 2022-04-15 14:12:03.030245+00 | replication_slot_name | 4 | 569409176 | 543 MB 2022-04-15 14:12:05.059761+00 | replication_slot_name | 5 | 618410996 | 590 MB 2022-04-15 14:12:07.22905+00 | replication_slot_name | 5 | 640585316 | 611 MB (6 rows)
Le résultat montre que l’exécution de l’exemple a créé cinq fichiers de déversement qui ont utilisé 611 Mo de mémoire. Pour éviter d’écrire sur le disque, nous vous recommandons de définir le paramètre logical_decoding_work_mem sur la taille de mémoire la plus élevée suivante, à savoir 1024.
