Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Gestion de l’abandon des connexions d’Aurora PostgreSQL avec regroupement des connexions
Lorsque les applications clientes se connectent et se déconnectent si souvent que le temps de réponse du cluster de bases de données Aurora PostgreSQL ralentit, on dit que le cluster connaît un abandon de connexion. Chaque nouvelle connexion au point de terminaison du cluster de bases de données Aurora PostgreSQL consomme des ressources, ce qui réduit les ressources pouvant être utilisées pour traiter la charge de travail réelle. L’abandon de la connexion est un problème que nous vous recommandons de gérer en suivant certaines des bonnes pratiques présentées ci-dessous.
Pour commencer, vous pouvez améliorer les temps de réponse sur les clusters de bases de données Aurora PostgreSQL qui présentent des taux élevés d’abandon de connexion. Pour ce faire, vous pouvez utiliser une fonction de regroupement de connexions, telle que RDS Proxy. Une fonction de regroupement de connexions fournit un cache de connexions prêtes à être utilisées pour les clients. Presque toutes les versions d’Aurora PostgreSQL prennent en charge RDS Proxy. Pour plus d’informations, consultez Amazon RDS Proxy avec Aurora PostgreSQL.
Si votre version spécifique d’Aurora PostgreSQL ne prend pas en charge RDS Proxy, vous pouvez utiliser une autre fonction de regroupement de connexions compatible avec PostgreSQL, telle que PgBouncer. Pour en savoir plus, consultez le site Web de PgBouncer
Pour voir si votre cluster de bases de données Aurora PostgreSQL peut bénéficier du regroupement des connexions, vous pouvez vérifier le fichier postgresql.log des connexions et des déconnexions. Vous pouvez également utiliser Performance Insights pour connaître le taux d’abandon de connexion de votre cluster de bases de données Aurora PostgreSQL. Vous trouverez ci-dessous des informations sur ces deux sujets.
Consignation des connexions et des déconnexions
Les paramètres log_connections et log_disconnections de PostgreSQL peuvent capturer les connexions et déconnexions à l’instance en écriture du cluster de bases de données Aurora PostgreSQL. Par défaut, ces paramètres sont désactivés. Pour activer ces paramètres, utilisez un groupe de paramètres personnalisés et activez-les en remplaçant la valeur par 1. Pour obtenir plus d’informations sur les groupes de paramètres personnalisés, consultez Groupes de paramètres de cluster de bases de données pour les clusters de bases de données Amazon Aurora. Pour vérifier les paramètres, connectez-vous au point de terminaison de votre cluster de bases de données pour Aurora PostgreSQL en utilisant psql et effectuez la requête suivante.
labdb=>SELECT setting FROM pg_settings WHERE name = 'log_connections';setting --------- on (1 row)labdb=>SELECT setting FROM pg_settings WHERE name = 'log_disconnections';setting --------- on (1 row)
Lorsque ces deux paramètres sont activés, le journal capture toutes les nouvelles connexions et déconnexions. Vous voyez l’utilisateur et la base de données pour chaque nouvelle connexion autorisée. Au moment de la déconnexion, la durée de la session est également enregistrée, comme le montre l’exemple suivant.
2022-03-07 21:44:53.978 UTC [16641] LOG: connection authorized: user=labtek database=labdb application_name=psql
2022-03-07 21:44:55.718 UTC [16641] LOG: disconnection: session time: 0:00:01.740 user=labtek database=labdb host=[local]
Pour vérifier l’abandon de connexion de votre application, activez ces paramètres s’ils ne le sont pas déjà. Rassemblez ensuite les données dans le journal PostgreSQL pour les analyser en exécutant votre application avec une charge de travail et une période de temps réalistes. Vous pouvez consulter le fichier journal dans la console RDS. Choisissez l’instance d’enregistreur de votre cluster de bases de données Aurora PostgreSQL, puis sélectionnez l’onglet Logs & events (Journaux et événements). Pour plus d’informations, consultez Liste et affichage des fichiers journaux de base de données.
Vous pouvez aussi télécharger le fichier journal à partir de la console et utiliser la séquence de commandes suivante. Cette séquence trouve le nombre total de connexions autorisées et abandonnées par minute.
grep "connection authorized\|disconnection: session time:" postgresql.log.2022-03-21-16|\ awk {'print $1,$2}' |\ sort |\ uniq -c |\ sort -n -k1
Dans l’exemple de sortie, vous pouvez voir un pic de connexions autorisées suivies de déconnexions à partir de 16:12:10.
.....
,......
.........
5 2022-03-21 16:11:55 connection authorized:
9 2022-03-21 16:11:55 disconnection: session
5 2022-03-21 16:11:56 connection authorized:
5 2022-03-21 16:11:57 connection authorized:
5 2022-03-21 16:11:57 disconnection: session
32 2022-03-21 16:12:10 connection authorized:
30 2022-03-21 16:12:10 disconnection: session
31 2022-03-21 16:12:11 connection authorized:
27 2022-03-21 16:12:11 disconnection: session
27 2022-03-21 16:12:12 connection authorized:
27 2022-03-21 16:12:12 disconnection: session
41 2022-03-21 16:12:13 connection authorized:
47 2022-03-21 16:12:13 disconnection: session
46 2022-03-21 16:12:14 connection authorized:
41 2022-03-21 16:12:14 disconnection: session
24 2022-03-21 16:12:15 connection authorized:
29 2022-03-21 16:12:15 disconnection: session
28 2022-03-21 16:12:16 connection authorized:
24 2022-03-21 16:12:16 disconnection: session
40 2022-03-21 16:12:17 connection authorized:
42 2022-03-21 16:12:17 disconnection: session
40 2022-03-21 16:12:18 connection authorized:
40 2022-03-21 16:12:18 disconnection: session
.....
,......
.........
1 2022-03-21 16:14:10 connection authorized:
1 2022-03-21 16:14:10 disconnection: session
1 2022-03-21 16:15:00 connection authorized:
1 2022-03-21 16:16:00 connection authorized:
Grâce à ces informations, vous pouvez décider si votre charge de travail peut tirer parti d’une fonction de regroupement de connexions. Pour une analyse plus détaillée, vous pouvez utiliser Performance Insights.
Détection de l’abandon de connexions avec Performance Insights
Vous pouvez utiliser Performance Insights pour évaluer le nombre d’abandons de connexion sur votre cluster de bases de données Aurora Édition compatible avec PostgreSQL. Lorsque vous créez un cluster de bases de données Aurora PostgreSQL, le paramètre pour Performance Insights est activé par défaut. Si vous avez désactivé ce choix lors de la création de votre cluster de bases de données, modifiez votre cluster pour activer cette fonctionnalité. Pour plus d’informations, consultez Modification d’un cluster de bases de données Amazon Aurora.
Lorsque Performance Insights fonctionne sur votre cluster de bases de données Aurora PostgreSQL, vous pouvez choisir les métriques que vous souhaitez surveiller. Vous pouvez accéder à Performance Insights à partir du panneau de navigation de la console. Vous pouvez également accéder à Performance Insights à partir de l’onglet Monitoring (Surveillance) de l’instance d’enregistreur pour votre cluster de bases de données Aurora PostgreSQL, comme le montre l’image suivante.
Dans la console Performance Insights, choisissez Manage metrics (Gérer les métriques). Pour analyser l’activité de connexion et de déconnexion de votre cluster de bases de données Aurora PostgreSQL, choisissez les métriques suivantes. Ce sont toutes des métriques de PostgreSQL.
xact_commit: nombre de transactions dédiées.total_auth_attempts– Nombre de tentatives de connexions d’utilisateurs authentifiés par minute.numbackends: nombre de backends actuellement connectés à la base de données.
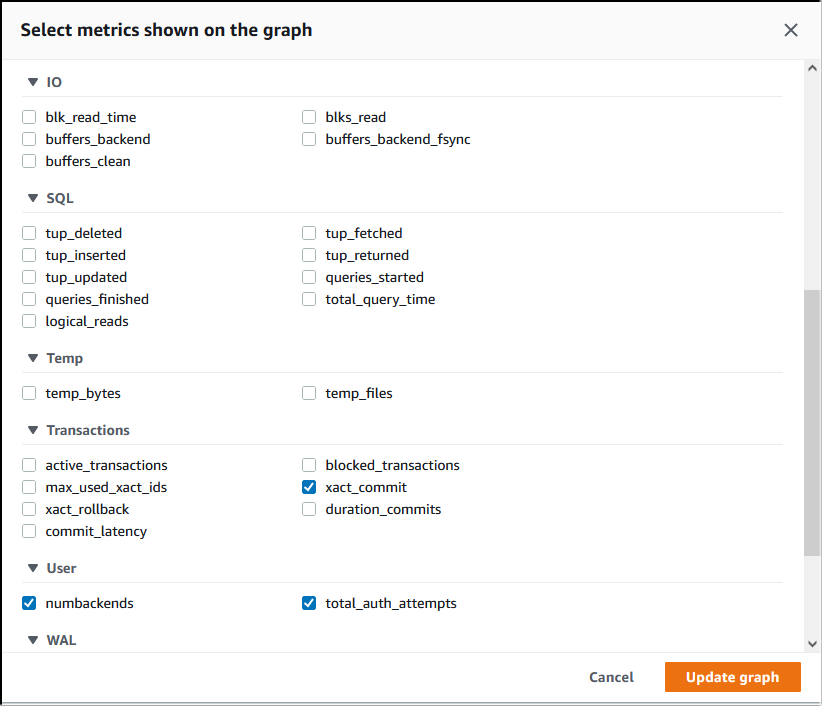
Pour enregistrer les paramètres et afficher l’activité de connexion, sélectionnez Update graph (Mettre à jour le graphique).
Dans l’image suivante, vous pouvez voir l’impact de l’exécution de pgbench avec 100 utilisateurs. La ligne indiquant les connexions est sur une pente ascendante constante. Pour en savoir plus sur pgbench et comment l’utiliser, consultez pgbench
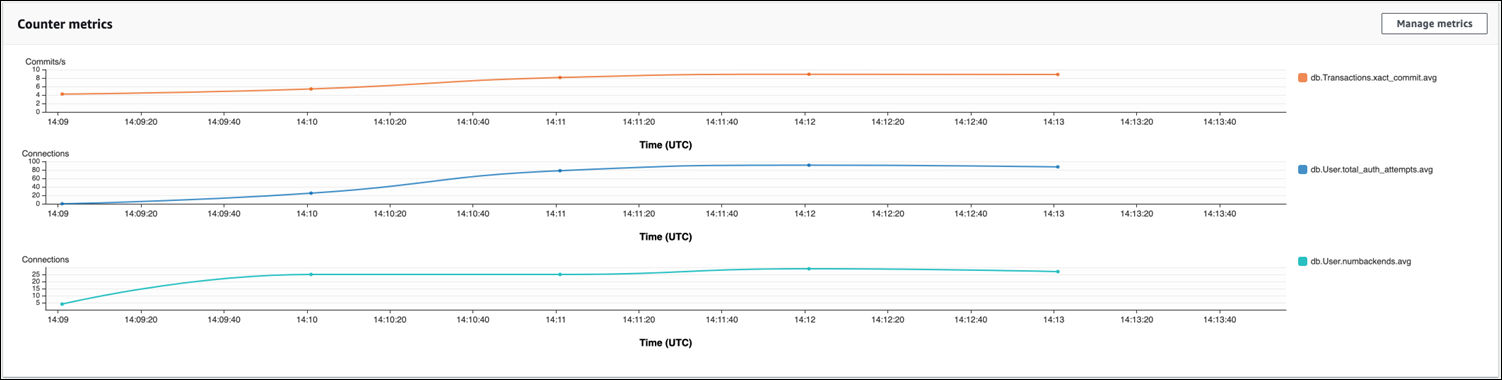
L’image montre que l’exécution d’une charge de travail avec 100 utilisateurs sans fonction de regroupement de connexions peut entraîner une augmentation significative du nombre de total_auth_attempts pendant toute la durée du traitement de la charge de travail. Notez qu’il est préférable que total_auth_attempts reste le plus proche possible de zéro.
Avec le regroupement de connexions RDS Proxy, les tentatives de connexion augmentent au début de la charge de travail. Après la mise en place du regroupement de connexions, la moyenne diminue. Les ressources utilisées par les transactions et le backend restent cohérentes tout au long du traitement de la charge de travail.
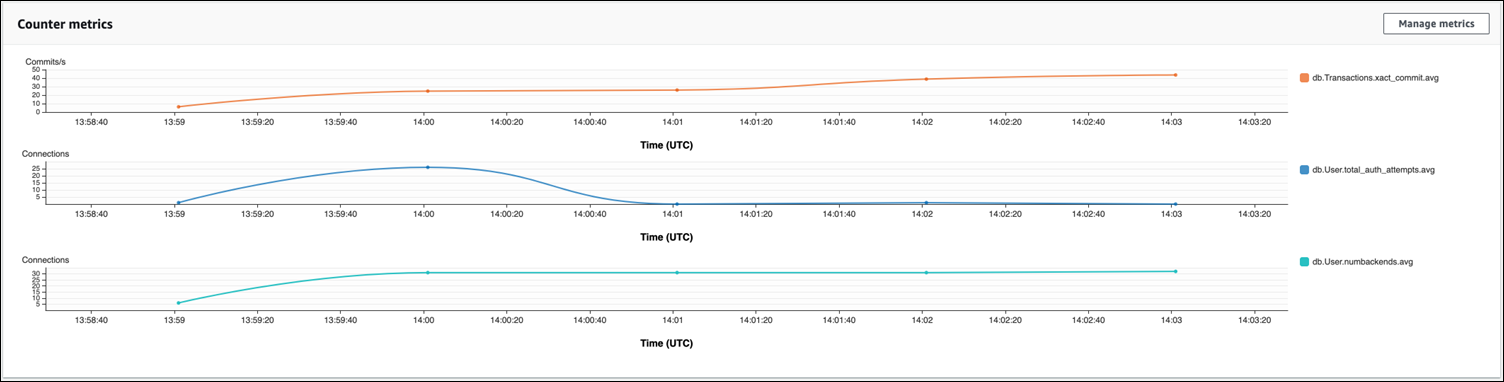
Pour obtenir plus d’informations sur l’utilisation de Performance Insights avec votre cluster de bases de données Aurora PostgreSQL, consultez Surveillance de la charge de la base de données avec Performance Insights sur . Pour analyser les métriques, consultez Analyse des métriques à l’aide du tableau de bord de Performance Insights.
Démonstration des avantages du regroupement de connexions
Comme indiqué précédemment, si vous déterminez que votre cluster de bases de données Aurora PostgreSQL a un problème d’abandon de connexion, vous pouvez utiliser RDS Proxy pour améliorer les performances. Vous trouverez ci-dessous un exemple qui montre les différences dans le traitement d’une charge de travail lorsque les connexions sont regroupées et lorsqu’elles ne le sont pas. L’exemple utilise pgbench pour modéliser une charge de travail de transaction.
Comme psql, pgbench est une application client PostgreSQL que vous pouvez installer et exécuter depuis votre machine cliente locale. Vous pouvez également l’installer et l’exécuter depuis l’instance Amazon EC2 que vous utilisez pour gérer votre cluster de bases de données Aurora PostgreSQL. Pour plus d’informations, consultez pgbench
Pour réaliser cet exemple, vous devez d’abord créer l’environnement pgbench dans votre base de données. La commande suivante désigne le modèle de base pour initialiser les tables pgbench dans la base de données spécifiée. Cet exemple utilise le compte utilisateur principal par défaut, postgres, pour la connexion. Modifiez-le selon vos besoins pour votre cluster de bases de données Aurora PostgreSQL. Vous créez l’environnement pgbench dans une base de données sur l’instance en écriture de votre cluster.
Note
Le processus d’initialisation de pgbench supprime et recrée les tables nommées pgbench_accounts, pgbench_branches, pgbench_history et pgbench_tellers. Assurez-vous que la base de données que vous choisissez pour dbname
pgbench -U postgres -hdb-cluster-instance-1.111122223333.aws-region.rds.amazonaws.com -p 5432 -d -i -s 50dbname
Pour pgbench, spécifiez les paramètres suivants.
- -d
-
Produit un rapport de débogage pendant l’exécution de pgbench.
- -h
-
Spécifie le point de terminaison de l’instance de base de données Aurora PostgreSQL en écriture.
- -i
-
Initialise l’environnement pgbench dans la base de données pour les tests d’évaluation.
- -p
-
Identifie le port utilisé pour les connexions à la base de données. La valeur par défaut pour Aurora PostgreSQL est généralement 5432 ou 5433.
- -s
-
Spécifie le facteur d’échelle à utiliser pour remplir les tables avec des lignes. Le facteur d’échelle par défaut est 1, ce qui génère 1 ligne dans la table
pgbench_branches, 10 lignes dans la tablepgbench_tellerset 100 000 lignes dans la tablepgbench_accounts. - -U
-
Spécifie le compte utilisateur pour l’instance d’enregistreur du cluster de bases de données Aurora PostgreSQL.
Une fois l’environnement pgbench configuré, vous pouvez exécuter des tests d’analyse comparative avec et sans regroupement de connexions. Le test par défaut consiste en une série de cinq commandes SELECT, UPDATE et INSERT par transaction qui s’exécutent de manière répétée pendant la durée spécifiée. Vous pouvez spécifier le facteur d’échelle, le nombre de clients et d’autres détails pour modéliser vos propres cas d’utilisation.
À titre d’exemple, la commande suivante exécute l’évaluation pendant 60 secondes (option -T, pour time) avec 20 connexions simultanées (option -c). L’option -C permet d’exécuter le test en utilisant une nouvelle connexion à chaque fois, plutôt qu’une fois par session client. Ce paramètre vous donne une indication de la surcharge de la connexion.
pgbench -h docs-lab-apg-133-test-instance-1.c3zr2auzukpa.us-west-1.rds.amazonaws.com -U postgres -p 5432 -T 60 -c 20 -C labdbPassword:**********pgbench (14.3, server 13.3) starting vacuum...end. transaction type: <builtin: TPC-B (sort of)> scaling factor: 50 query mode: simple number of clients: 20 number of threads: 1 duration: 60 s number of transactions actually processed: 495 latency average = 2430.798 ms average connection time = 120.330 ms tps = 8.227750 (including reconnection times)
L’exécution de pgbench sur l’instance d’enregistreur d’un cluster de bases de données Aurora PostgreSQL sans réutilisation de connexions montre que seulement 8 transactions environ sont traitées chaque seconde. Cela donne un total de 495 transactions pendant le test d’une minute.
Si vous réutilisez les connexions, la réponse du cluster de bases de données Aurora PostgreSQL pour le nombre d’utilisateurs est presque 20 fois plus rapide. Avec la réutilisation, un total de 9 042 transactions est traité contre 495 dans le même laps de temps et pour le même nombre de connexions utilisateurs. La différence est que dans ce qui suit, chaque connexion est réutilisée.
pgbench -h docs-lab-apg-133-test-instance-1.c3zr2auzukpa.us-west-1.rds.amazonaws.com -U postgres -p 5432 -T 60 -c 20 labdbPassword:*********pgbench (14.3, server 13.3) starting vacuum...end. transaction type: <builtin: TPC-B (sort of)> scaling factor: 50 query mode: simple number of clients: 20 number of threads: 1 duration: 60 s number of transactions actually processed: 9042 latency average = 127.880 ms initial connection time = 2311.188 ms tps = 156.396765 (without initial connection time)
Cet exemple vous montre que le regroupement des connexions peut améliorer considérablement les temps de réponse. Pour plus d’informations sur la configuration de RDS Proxy pour votre cluster de bases de données Aurora PostgreSQL, consultez Proxy Amazon RDS pour Aurora.
